Prefetch -Aware DRAM Controllers
This study explores how adaptive prefetch scheduling and dropping can optimize DRAM system performance by prioritizing and canceling prefetch requests based on prefetch accuracy estimation. Goals include maximizing useful prefetch benefits and eliminating useless prefetches. The Prefetch-Aware DRAM Controllers aim to achieve higher performance and efficiency.


Prefetch -Aware DRAM Controllers
E N D
Presentation Transcript
Prefetch-Aware DRAM Controllers Chang Joo Lee Onur Mutlu* Veynu Narasiman Yale N. Patt Electrical and Computer Engineering The University of Texas at Austin *Microsoft Research and Carnegie Mellon University
Outline • Motivation • Mechanism • Experimental Evaluation • Conclusion
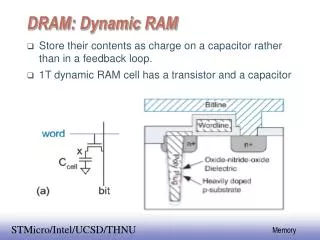
Modern DRAM Systems DRAM Bank • Rows and columns of DRAM cells • A row buffer in each bank • Non-uniform access latency: • Row-hit: • Data is in the row buffer • Row-conflict: • Data is not in the row buffer • Needs to access the DRAM cells • Row-hit latency < Row-conflict latency Row B Row Buffer Row A Row-conflict Row-hit Data Bus Processor: Row A Processor: Row B Prioritize row-hit accesses to increase DRAM throughput [Rixner et al. ISCA2000]
Problems of Prefetch Handling • How to schedule prefetches vs demands? • Demand-first: Always prioritizes demands over prefetch requests • Demand-prefetch-equal: Always treats them the same Neither of these perform best Neither take into account both: 1. Non-uniform access latency of DRAM systems 2. Usefulness of prefetches
When Prefetches are Useful Stall Execution DRAM • Demand-first Row B Row A Row Buffer 2 row-conflicts, 1 row-hit DRAM Row-conflict Row-hit Processor DRAM Controller Miss Y Miss X Miss Z Pref Row A : X Dem Row B : Y Pref Row A : Z Processor needs Y, X, and Z
When Prefetches are Useful Stall Execution DRAM • Demand-first Row A Row B Row Buffer 2 row-conflicts, 1 row-hit DRAM Row-conflict Row-hit Processor DRAM Controller Miss Y Miss X Miss Z Demand-pref-equal outperforms demand-first Pref Row A : X Dem Row B : Y • Demand-pref-equal Pref Row A : Z 2 row-hits, 1 row-conflict DRAM Processor Processor needs Y, X, and Z Saved Cycles Miss Y Hit X Hit Z
When Prefetches are Useless DRAM • Demand-first Row A Row Buffer DRAM Y X Z Processor DRAM Controller Saved Cycles Miss Y Pref Row A : X Demand-first outperforms demand-pref-equal Dem Row B : Y • Demand-pref-equal Pref Row A : Z DRAM X Z Y Processor Processor needs ONLY Y Miss Y
Demand-first vs. Demand-pref-equal policy Stream prefetcher enabled Useless prefetches: Off-chip bandwidth Queue resources Cache Pollution Goal 1: Adaptively schedule prefetches based on prefetch usefulness Demand-pref-equal is better Goal 2: Eliminate useless prefetches Demand-first is better
Goals 1. Maximize the benefits of prefetching: Increase DRAM throughput by adaptively scheduling requests based on prefetch usefulness → increase timeliness of useful prefetches 2. Minimize the harm of prefetching: Adaptively delay the service of useless prefetches and remove useless prefetches → increase efficiency of resource utilization Achieve higher performance and efficiency
Outline • Motivation • Mechanism • Experimental Evaluation • Conclusion
Prefetch-Aware DRAM Controllers (PADC) To DRAM • Adaptive Prefetch Scheduling (APS): Prioritizes prefetch and demand requests based on prefetch accuracy estimation • Adaptive Prefetch Dropping (APD): Cancels likely-useless prefetches from memory request buffer based on prefetch accuracy Update APS Request priority Memory request buffer APD Drop Request Info PADC Prefetch accuracy from each core
Prefetch Accuracy Estimation #Prefetches used • Prefetch accuracy = • Hardware support: • Prefetch bit (per L2 cache line, MSHR entry): Indicates whether it is a prefetch or demand • Prefetch sent counter (per core) • Prefetch used counter (per core) • Prefetch accuracy register (per core) • Estimated every 100K cycles #Prefetches sent
To DRAM Update APS Request priority Memory request buffer APD Drop Request Info PADC Prefetch accuracy from each core Adaptive Prefetch Scheduling (APS) 1. Adaptively change the priority of prefetch requests • Low prefetch accuracy → prioritize demands from the core • High prefetch accuracy → treat demands and prefetches equally 2. In a CMP system: prioritize demand requests from a core that has many useless prefetches • To avoid starving demand requests from a core with low prefetch accuracy → improves system performance
Adaptive Prefetch Scheduling (APS) 1. Critical requests • All demand requests • Prefetch requests from cores whose prefetch accuracy ≥ promotion threshold 2. Urgent requests • Demand requests from cores whose prefetch accuracy < promotion threshold
C RH U FCFS Adaptive Prefetch Scheduling (APS) • Each memory request buffer entry: priority fields • Prioritization order: 1. Critical request (C) 2. Row-hit request (RH) 3. Urgent request (U) 4. Oldest request (FCFS)
To DRAM Update APS Request priority Memory request buffer APD Drop Request Info PADC Prefetch accuracy from each core Adaptive Prefetch Dropping (APD) • Proactively drops old prefetches based on prefetch accuracy estimation • Old requests are likely useless • APS prioritizes demand requests when prefetch accuracy is low • A prefetch that is hit by a demand is promoted to a demand • Dropping old, useless prefetches saves resources(bandwidth, queues, caches) • Saved resources can be used by useful requests
P ID AGE Adaptive Prefetch Dropping (APD) • Each memory request buffer entry: drop information • Prefetch bit (P) • Core ID field (ID) • Age field (AGE) • Drop prefetch requests whoseAGE > Drop threshold • Drop threshold is dynamically determined based on prefetch accuracy estimation • Lower accuracy → Lower threshold
Hardware Cost for 4-core CMP • Total storage: 34,720 bits (~4.25KB) are needed • ~ 4KB are prefetch bits in each cache line • If prefetch bits are already implemented: ~228B • Logic is not on the critical path • Scheduling and dropping decisions are made every DRAM bus cycle
Outline • Motivation • Mechanism • Experimental Evaluation • Conclusion
Simulation Methodology • x86 cycle accurate simulator • Baseline processor configuration • Per core • 4-wide issue, out-of-order, 256-entry ROB • 512KB, 8-way unified L2 cache (1MB for single core processor) • Stream prefetcher (Lookahead, prefetch degree: 4, prefetch distance: 64) • Shared • On-chip, demand-first FR-FCFS memory controller • 64, 128, 256 L2 MSHRs, memory request buffer for 1-, 4-, 8-core • DDR3 1333, 15-15-15ns, 4KB row buffer • PADC configuration • Promotion threshold: 85% • Drop threshold:
Workloads for Evaluation • Single-core processor: All 55 SPEC 2000/2006 benchmarks • Single-threaded • 38 prefetch sensitive benchmarks • 17 prefetch insensitive benchmarks • CMP: Randomly chosen multiprogrammed workloads from 55 benchmarks: • 4-core CMP: 32 workloads • 8-core CMP: 21 workloads
Performance of PADC 4.3% 8.2% 9.9%
Bus Traffic of PADC -10.4% -10.7% -9.4%
Performance with Other Prefetchers 4-core CMP 6.0% 6.6% 2.2%
Bus Traffic with Other Prefetchers 4-core CMP -5.7% -6.8% -10.3%
Outline • Motivation • Mechanism • Experimental Evaluation • Conclusion
Conclusions • Prefetch-Aware DRAM Controllers (PADC) • Adaptive Prefetch Scheduling • Increase DRAM throughput by exploiting row-buffer locality when prefetches are useful • Delay service of prefetches when they are useless • Adaptive Prefetch Dropping • With APS, remove useless prefetches effectively while keeping the benefits of useful prefetches • Improve performance and bandwidth efficiency for both single-core and CMP systems • Low cost and easily implementable
Performance Detail • Single-core: • 38 prefetch-sensitive: 6.2% • Prefetch-friendly: 29 benchmarks • Prefetch-unfriendly: 9 benchmarks • 17 out of 38 are memory intensive (MPKI > 10) : 11.8% • 17 prefetch-insensitive
Two Channel Memory Performance 16% 31% 5.9% 5.5%
Two Channel Memory Bus Traffic -12.9% -13.2%
Comparison with Feedback Directed Prefetching 4-core CMP 6.4%
Prefetch Friendly Application • libquantum
Average Performance on Single-Core • All 55 SPEC 2000/2006 CPU benchmarks
System Performance on 4-Core CMP • 32 randomly chosen 4-core workloads
System Performance on 8-core CMP • 21 randomly chosen 8-core workloads
Prefetch Friendly Application • leslie3d
Performance on 4-Core • omnetpp, libquantum, galgel, and GemsFDTD on 4-core CMP
Performance on 4-Core • omnetpp, libquantum, galgel, and GemsFDTD on 4-core CMP
System Performance on 4-Core • omnetpp, libquantum, galgel, and GemsFDTD