Download

1 / 8
100 likes | 250 Vues
The paper discusses the challenges of workload optimization in server management, specifically addressing the issues of power efficiency and performance stability. It highlights the need for workload optimization techniques to increase server utilization while minimizing idle power consumption without sacrificing performance. The authors explore the unpredictable nature of workload fluctuations—cliffs, spikes, and valleys—and propose strategies for robust query processing. Key metrics for achieving consistent performance are examined, focusing on practical improvements in data management software.

E N D
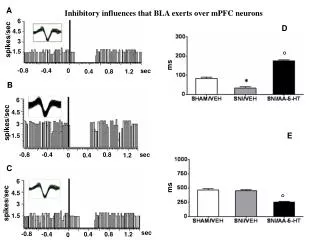
Cliffs, Spikes and Valleys Goetz Graefe and Harumi Kuno
50% of power is load-independent • Clearly we need workload optimization: • Increase server utilization • Decrease power wasted by idle machines • Without sacrificing performance. • So what’s the problem? • Hard to predict cliffs, spikes, and valleys in mixed workloads • Hard to plan Safer to over-provision
Scan one index, apply 2nd predicate Example: System B has a cliff System A System B
Example: contention moves cliffs overflow
Example valley and spike: online index creation Load Combined load System capacity Query load Indexing load Time SMDB 2011 - Hannover
For example: prevent a spike by accommodating a valley Load System capacity Query load Delayed indexcompletion Time SMDB 2011 - Hannover
How to motivate, evaluate, protect improvements in robust query processing? • Metrics for “good performance every time” • As opposed to optimal performance, predictability or progress estimation. • Metric that rewards lack of cliffs, spikes, and valleys, • Not just predict them • Improvements include: • Robust algorithms (e.g., memory-adaptive sorting) • Robust algorithm choices (e.g., g-join and g-distinct) • Robust plans (e.g., dynamic re-ordering of operations within a plan), etc.
Nutshell • How can (data management) software prevent over-provisioning? • Workload management and optimization : great, but what about the cliffs, spikes, and valleys? • What are good metrics and tests for “good performance every time” ? • How can we improve query processing robustness?