s cikit -learn
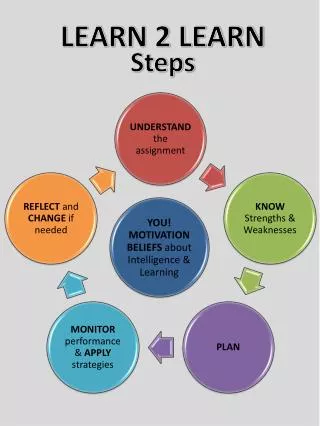
s cikit -learn. Machine Learning in Python Vandana Bachani http://infolab.tamu.edu Spring 2012. Outline. What is scikit -learn? How can it be useful to the lab? There are other packages too! Features Usage Conclusion. What is scikit -learn?.


s cikit -learn
E N D
Presentation Transcript
scikit-learn Machine Learning in Python VandanaBachani http://infolab.tamu.edu Spring 2012
Outline • What is scikit-learn? • How can it be useful to the lab? • There are other packages too! • Features • Usage • Conclusion http://infolab.tamu.edu
What is scikit-learn? scikit-learn is a Python module integrating classic machine learning algorithms in the tightly-knit world of scientific Python packages (numpy, scipy, matplotlib) • A comprehensive package for all machine learning needs. • Faster • Accuracy? If you have the right data, it is pretty loyal. Ref: http://scikit-learn.org/stable/
How can it be useful to the lab? • Our daily jobs: • Regression/Prediction • Text Classification • Text Feature Extraction • Text Feature Selection • Using Chi-Square and other metrics • Cross-Validation • K-Fold • Clustering (K-Means, etc.) • Maybe in future: • Image Classification All in one package! http://infolab.tamu.edu
There are other packages too! http://infolab.tamu.edu
Features Linear Models • Regression (Predicting Continuous Values) Example: Prices of houses (Boston house dataset) • Linear, Ridge, Lasso (for sparse coefficients, useful in field of compressed sensing), LARS (very-high dimensional data), Bayesian • Classification • Logistic Regression, Stochastic Gradient Descent http://infolab.tamu.edu
Features Support Vector Machines • Classification • SVC (one-vs-one), LinearSVC (one-vs-rest) • Regression • SVR • Density Detection & Outlier Detection (unsupervised learning) http://infolab.tamu.edu
Features Unsupervised Learning • Clustering • K-Means, Mean Shift, Spectral Clustering • Ward (hierarchical, constructs tree) • Manifold Learning • Dimensionality Reduction (for visualization, etc) • Novelty and Outlier Detection • Uses SVM http://infolab.tamu.edu
Features Miscellaneous • Nearest neighbors • Unsupervised, Classification • Decision Trees • Classification, Regression • Gaussian Processes • Regression • Metrics • metrics.roc_curve(y_true, y_score) • metrics.precision_recall_fscore_support(...) • joblib and pickle http://infolab.tamu.edu
Features • Cross-Validation • cross_validation.KFold(n, k[, indices]) • Datasets • Feature Extraction • Text • feature_extraction.text.WordNGramAnalyzer([...]) • feature_extraction.text.CharNGramAnalyzer([...]) • Image • feature_extraction.image.extract_patches_2d(...) • Feature Selection • feature_selection.chi2(X, y) • feature_selection.SelectKBest(score_func[, k]) http://infolab.tamu.edu
Usage • Linear Regression >>> from sklearn import linear_model >>> clf = linear_model.LinearRegression() >>> clf.fit ([[0, 0], [1, 1], [2, 2]], [0, 1, 2]) LinearRegression(copy_X=True, fit_intercept=True, normalize=False) • Classification >>> from sklearn.linear_model import SGDClassifier >>> X = [[0., 0.], [1., 1.]] >>> y = [0, 1] >>> clf = SGDClassifier(loss="hinge", penalty="l2") >>> clf.fit(X, y) SGDClassifier(alpha=0.0001, class_weight=None, eta0=0.0, fit_intercept=True, learning_rate='optimal', loss='hinge', n_iter=5, n_jobs=1, penalty='l2', power_t=0.5, rho=0.85, seed=0, shuffle=False, verbose=0) http://infolab.tamu.edu
Usage • SVC & Cross-Validation >>> from sklearn import datasets >>> from sklearn import svm >>> from sklearn import cross_validation >>> iris = datasets.load_iris() >>> clf = svm.SVC(kernel='linear') >>> scores = cross_validation.cross_val_score(clf, iris.data, iris.target, cv=5) >>> scores array([ 1. ..., 0.96..., 0.9 ..., 0.96..., 1. ...]) http://infolab.tamu.edu
Sample Code penalty = "l2" #LinearSVC can be tried with L1, L2 penalties print "LinearSVC" linearSVC = LinearSVC(loss='l2', penalty=penalty, C=1000, dual=False, tol=1e-3) classify(linearSVC, X_train, y_train, X_test, y_test) #SGDClassifier print "SGDClassifier" sgdClf = SGDClassifier(alpha=.0001, n_iter=50, penalty=penalty) classify(sgdClf, X_train, y_train, X_test, y_test) print "NaiveBayes - Multinomial" bernoulliNBClf= BernoulliNB(alpha=.01) classify(bernoulliNBClf, X_train, y_train, X_test, y_test) -------------- def classify(clf, X_train, y_train, X_test, y_test): clf.fit(X_train, y_train) train_time = time() - t0 print "train time: %0.3fs" % train_time pred= clf.predict(X_test) test_time = time() - t0 print "test time: %0.3fs" % test_time print "classification report:" print metrics.classification_report(y_test, pred, target_names=categories) data_train, data_test = trainData.data, testData.data y_train, y_test = trainData.target, testData.target print "Extracting features from the training dataset" #can use a specific analyzer to be passed to vectorizer #by default WordNGramAnalyzer is used vectorizer = Vectorizer() X_train = vectorizer.fit_transform(data_train) print "done in %fs" % (time() - t0) print "n_samples: %d, n_features: %d" % X_train.shape print "Extracting features from the test dataset" X_test= vectorizer.transform(data_test) print "done in %fs" % (time() - t0) print "n_samples: %d, n_features: %d" % X_test.shape http://infolab.tamu.edu
Sample Results SGDClassifier train time: 1.505s test time: 0.023s classification report: precision recall f1-score support TECHNOLOGY 0.75 0.99 0.85 3918 IDIOMS 0.94 0.66 0.78 5205 POLITICAL 0.88 0.99 0.93 4268 MUSIC 0.90 0.74 0.81 872 GAMES 0.97 0.95 0.96 457 SPORTS 0.87 0.98 0.92 443 MOVIES 0.97 0.90 0.93 1092 CELEBRITY 0.73 0.46 0.56 24 avg / total 0.88 0.86 0.86 16279 http://infolab.tamu.edu
Conclusion • If you are a python person - • Seems like a good library • NLTK + scikit-learn should make an excellent pair for our lab • Good documentation wins! http://infolab.tamu.edu
Thanks Email: vandana_bvj_tamu@tamu.edu http://infolab.tamu.edu