Source View
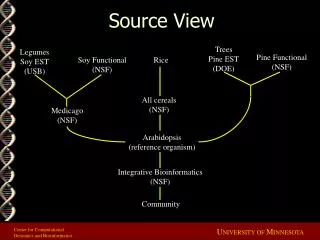
Source View. Trees Pine EST (DOE). Legumes Soy EST (USB). Pine Functional (NSF). Soy Functional (NSF). Rice. All cereals (NSF). Medicago (NSF). Arabidopsis (reference organism). Integrative Bioinformatics (NSF). Community. Partnerships. Federal Support: Grants and Contracts.

Source View
E N D
Presentation Transcript
Source View Trees Pine EST (DOE) Legumes Soy EST (USB) Pine Functional (NSF) Soy Functional (NSF) Rice All cereals (NSF) Medicago (NSF) Arabidopsis (reference organism) Integrative Bioinformatics (NSF) Community
Partnerships Federal Support: Grants and Contracts Corporate Support: Hardware, Software, and Data • Research Community Support: • Shared Expertise and Knowledge • Bioinformatics Community • Plant Community • Metacomputing Community Integrated Genomics
Application View Similarity Searches Unigene Sets Diogenes BioData Sequence processing Pipeline, Automation All public genomic data
Application View Similarity Searches Unigene Sets Visualization & Exploration Diogenes BioData • Functional Genomics • Array Design • SAGE • Clustering • Data Mining Sequence processing Pipeline, Automation Genomics Desktop All public genomic data
Application View Similarity Searches Unigene Sets Visualization & Exploration Diogenes BioData • Functional Genomics • Array Design • SAGE • Clustering • Data Mining Sequence processing Pipeline, Automation Genomics Desktop Warehouse All public genomic data Metabolic Pathway Reconstruction Multi-species Comparative Functional Genomics Relational Genbank Metafam
The Genomics Grid Real Time, Visual Collaboration High Throughput Genomics Visual Exploration of Global Data Resources Distributed Computing: Condor, Globus, Sun Grid Clusters of Workstations Special Purpose Hardware Time Logic “DeCypher” High Performance Networking ATM / GBE / FCAL Internet 2 Interoperable Software “Grid Aware” Applications Remote SQL Queries Java Enterprise level data storage Oracle
Design Goals • Scalable - Provide a workload management solution for large scale bioinformatics processing • Extensible - Add new tools easily without modifying core components • Portable - Deliver functionality in heterogeneous environments • Collaborative - Combine processing resources to increase throughput
Web Based Submission Tool Data submissions happen in batches, initiated by clients. File formats, processing requirements, and batch structure vary widely. Unique Internal Identifiers 55 56 57 58 Data Files Individual Data Items (Chromatograms or sequence files) “Preprocessing” database Client Metadata Data arrives at CCGB in a well structured format, amenable to automatic processing. Context All metadata related to each individual sequence XML format
Data Submission Prototype In this example of a data submission page, the user selects the appropriate data directory, and uses Netscape’s file browser to upload the TAB delimited spreadsheet file.
Metadata Required for Processing Some quality control checking is done at submission time to ensure that the metadata are consistent and correct. This includes a “spellcheck” like feature to be sure that primers, citations and such reference things known to CBC. Name Type Sequence ID String (used to identify which data file is associated with this metadata) Sequence Name String (used for GSS# or EST# in GB submission) Experiment Type <GSS, EST> Data Type <Chromatogram, FASTA_sequence, array_expression> Date Sequenced Date Seq Primer Identifier for Primer (CBC maintained list) Contact Name Identifier for NCBI Contact File (CBC maintained list) Citation Identifier for NCBI Citation File (CBC maintained list) Library Identifier for NCBI Library File (CBC maintained list) Class <BAC_end, YAC_end, exon-trapped> Organism Identifier for organism (CBC maintained list) Send to DB <Yes, No, Update>
Tasks in Processing Biological Data • Base Calling (Phred, Phran) • Vector Filter (VF4) • Artifact Filter (af) • BLAST (blast, blastx, tblastx, blastn) • Contig construction (Phrap) • Microarray Design • Primer Selection • Functional Analysis & Annotation • Submission to public repositories (Genbank) • Publication
TkBatch User Interface Provide a configurable interface to a set of tools. Batch Processing System Enable batch submission of thousands of jobs Dependency Management Define Directed Acyclic Graphs (DAG)s for process flow. A DAG is not a tree.
TkBatch – Use Outline Watchlist: Directed Acyclic Graph of processes which will act on the input data Compile to - Job Description: Enumerates all tasks included in the job, all job dependencies, as well as a “status journal” indicating progress through the tasks. File List: Input data, possibly selected from diverse locations in the file system • Submit to – Distributed Processing • CONDOR metacomputing platform • Similar to GLOBUS and Sun’s GRID • Uses idle workstations to perform processing tasks • Dependancy • Observe through TkBatch • Building process monitoring capabilities into the TkBatch system. • Obtaining CONDOR source code to make improvements directly.
Application Configuration • Tools cannot be selected unless they are appropriate to the current output type in the watchlist. • Reasonable defaults are provided for command line options. Some system abstraction, but still a very “close to the road” interface
Analysis Tools • RelGB • A simple relational framework for GenBank Data • Java based UI for biologically relevant queries • SSR Identification & primer design for ESTs • All; UTR; BAC-end; BAC • EST contigs: Diogenes-Blast; Primer3 • Analysis Tools
BioData Summary PERL and CGI Scripts, operating on XML indexes to data directories Creates set of predefined web views on data http://web.ahc.umn.edu/biodata • Grant Summary • Grant Info • Grant Statistics • Contig list • Submission Set List • Submission • Sequence Length Distribution • Submission Set Visualization • Search BLAST reports • Sequence List • Contig Sets • Contig Info Table • Phrap Parameters • Submissions in the Contig Set • Contig Quality Graphs • Sequences in the Contig Set • Project Statistics • Number of sequences • Number of submissions • Length Statistics • Contig Statistics • Quality Statistics • Sequence Info • Raw Sequence • Filtered Sequence • Sequence Quality Graph • Sequence Analysis Tools • BLAST Reports • Contig Page • Sequence Info • Contig Visualization • Sequence Analysis Tools • BLAST Reports
BioData File Tree contig_dir_### | +-index.xml | | <contigdata | | kingdom="Planta" | | family="Pinaceae" | | species="Pinus taeda" | | files="contigs" | | > | | | | <tissuelist> | | Xylem | | </tissuelist> | | | | <librarylist> | | NXNV | | </librarylist> | | | | <submissionlist> | | 991206a 991206b 991207a 991207b | | 20000103a 20000217a 20000515a 20000612 | | 20000103b 20000221a 20000515b 20000613a | | 20000103c 20000328a 20000515c 20000613b | | </submissionlist> | | | | <phrapparams | | minmatch="40" | | minscore="80" | | > | | </phrapparams> | | | | <contigversionlist | | AssemblyProcessId="PtaedaNormalXylem" | | AssemblyProcessVersion="1" | | AssemblyStepNumber="1" | | > | | </contigversionlist> | | </contigdata> | | | +-libraryname.fasta.screen.ace.1 | |
CCGB Condor Cluster • 65 processors on 37 machines • Performance • 4.75 Gflops • 25 BIPS • 19 GB memory • Figures are roughly equivalent to a 16 processor IBM SP2 • Customized usage policies