Download

1 / 46
460 likes | 576 Vues
This paper explores the Tom Thumb algorithm's capability to self-replicate arbitrary structures within FPGAs. It introduces the concept of ontogenetic hardware, inspired by biological growth processes, to design complex computing systems. Key areas include organizing multicellular structures, cellular differentiation, and self-repair mechanisms. By leveraging bio-inspired algorithms, we address challenges in complexity, scalability, and fault tolerance. Applications range from adaptive systems to streaming data processing, showcasing the potential of programmable logic in advancing computing technologies.

E N D
Ontogenetic hardware • Ok, so the Tom Thumb algorithm can self-replicate an arbitrary structure within an FPGA • But what kindof structures is it interesting to self-replicate
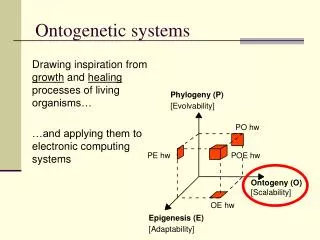
Ontogenetic hardware Embryonics = embryonic electronics: Drawing inspiration from growth processes of living organisms to design complex computing systems Phylogeny (P) [Evolvability] PO hw PE hw POE hw Ontogeny (O) [Scalability] OE hw Epigenesis (E) [Adaptability]
Bio-Inspired Approaches • Growth • Self-organization • Massive parallelism (multicellular systems) • Issues that growth can potentially address: • Complexity • Scalability • Fault tolerance
Caenorhabditis Elegans 11 December 1998
Caenorhabditis Elegans From S.F. Gilbert, Developmental Biology, Sinauer, 1991
Multicellular Organization 959 somatic cells
Cellular Differentiation Pharynx Intestine
Embryonics: How? Iterative electronic circuit based on 3 features: • multicellular organization • cellular division • cellular differentiation
Embryonics Landscape Population level S (population = organisms) Organismic level S (organism = cells) Cellular level S (cell = molecules) Molecular level (basic FPGA's element)
StopWatch • First step: design of a totipotent cell (stem cell) (of course, in practice it can be optimized)
BioWatch • The application can of course be anything… • But then, the size and structure of the cell will vary from application to application: we need programmable logic!
MUXTREE Molecule • The “molecular” layer of Embryonics is an FPGA
Cellular Self-Replication • But if we use FPGAs, then we need to CREATE the array of cells in the first place, before differentiation can take place (self-replication)
Cellular Self-Replication • But if we use FPGAs, then we need to CREATE the array of cells in the first place, before differentiation can take place (self-replication)
Cellular Self-Replication • But if we use FPGAs, then we need to CREATE the array of cells in the first place, before differentiation can take place (self-replication)
Cellular Self-Replication • Self-replication will allow the same FPGA partial configuration to be duplicated as many times as needed
Cellular Self-Repair • But self-replication, and custom FPGAs, can ALSO be used to improve the reliability of the system
Cellular Self-Repair • But self-replication, and custom FPGAs, can ALSO be used to improve the reliability of the system … within limits
Genotype Layer • Phenotype Layer • Mapping Layer Example – Automatic Synthesis Application-specific (parallel) functions Developmental algorithm Genetic code
Example – Automatic Synthesis Totipotent Cell • Phenotype Layer • Mapping Layer • Genotype Layer
Example – Automatic Synthesis Programmable Logic Totipotent Cell
Example – Automatic Synthesis Programmable Logic Cellular Array
What kind of applications can take advantage of this kind of system? Complex "real-world" streaming applications computation is carried out sequentially can be represented by a DAG of computation nodes each node processes data locally then forwards them to the next node in the graph Applications × ×+ ÷≠ FFT + DCT IN OUT
READ DCT QNTZ CMPR WRT Example: JPEG • Specialized MOVE functional units can be designed for each of these steps IN OUT
Context Programmable substrate × ×+ ÷≠ FFT + DCT IN OUT Problem: task or resource allocation – i.e. how do we map the graph nodes to the array? Specifically: dynamic allocation
Self-Scaling Stream Processing Source Funct B Funct A Funct A Funct C Funct C Join Funct A Funct A Funct C Funct C Funct A Funct A Funct A
SSSP The MJPEG application consists of a four-stage computation pipeline. The data to be compressed are composed of 192 bytes corresponding to an 8x8 array of pixels using 24-bit colour. The maximum rate achievable (determined by the input rate) is of 700 packets per second - roughly 1 MBit/second. With a single pipeline, the performance tops at about 60 packets per second.
SSSP When performance peaks, the average output rate is of 675 packets per second (out of a maximum of 700): this technique allows to multiply the throughput by a factor of 11 using 28 processors.