FROM GENE TO PROTEIN
600 likes | 1.04k Vues
FROM GENE TO PROTEIN. Chapter 17. Proteins make the Organism. Overview of the Gene to Protein Concept. The Triplet Code. The Dictionary of The Genetic Code. Transcription. Genes have nucleotide segments upstream of them called promoters

FROM GENE TO PROTEIN
E N D
Presentation Transcript
FROM GENE TO PROTEIN Chapter 17 Proteins make the Organism
Overview of the Gene to Protein Concept • The Triplet Code
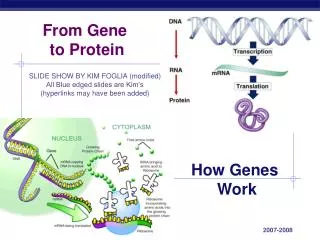
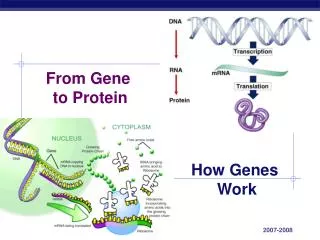
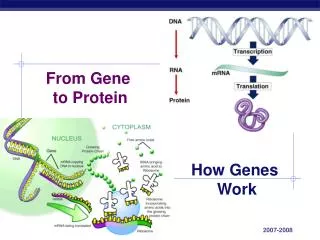
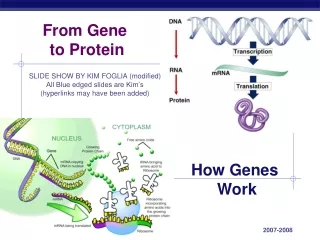
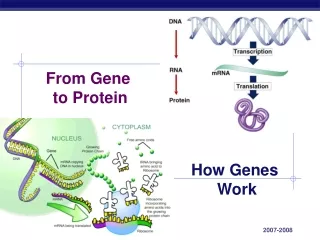
Transcription • Genes have nucleotide segments upstream of them called promoters • Promoter sites have a segment that are high in Thymine and Adenine residues – called TATA boxes • Certain specific transcription factors bind to TATA box of the promoter site • RNA Polymerase can then recognize the promoter site and transcription can begin • RNA Pol. Uses ATP, UTP, GTP and CTP to copy the template (anti-sense) strand of the gene.
Transcription, cont’d. • Initiation (Binding of RNA Polymerase) • Elongation (Lengthening of mRNA strand) • Termination (End of transcription)
Enhancers and Silencers • Enhancers are sequences further upstream of the gene’s promoter • Special proteins called Activators bind to these enhancer sequences to increase rate of transcription • Silencer sequences are also found upstream of gene promoters • Proteins called Repressors ind to silencers and decrease rate of transcription
Pre-mRNA Processing • Splicing of introns (By snRNPS – spliceosomes) • 5’ Methylguanosine cap • 3’ Poly A tail
Are introns necessary? • Humans have just 20,000 to 25,000 genes, but the human body may contain more than 2 million different proteins, each having different functions. • One gene one protein? Can’t be! • A bacterial chromosome contains between 500-1500 genes (depending on type of bacterium) and about the same number of proteins • Eukaryotes have many introns, whereas bacteria have few to none
Alternate Splicing of Exons • A classic example of alternate splicing is the rat muscle protein, troponin T. The gene consists of five exons, each representing a domain of a final protein. These exons are each separated by an intron. The five exons are W, X, Alpha, Beta, and Z. Two types of protein are found. The alpha form consists of exons W, X, alpha and Z. The beta form consists of the W, X, Beta and Z exons. The two different types of the protein are produced by alternative splicing of the same gene. The two different gene products are produced by selective splicing such that introns three and four and the fourth exon are spliced as one unit. In some manner the 5' GT sequence of intron 3 and the 3' AG sequence of the fourth intron are used during the splcing event.
Introns Early or Late? • The Introns-early theory says exons were minigenes. At some stage, such as precellular life, minigenes would have functioned as genes do today. At a later stage in evolution, the minigenes were assembled to make whole genes. Introns were the functionless pieces that held the exons together. All genes were built that way. Bacteria have no introns, and single-celled eukaryotes have very few because they lost them in later evolutionary stages. That's the introns-early theory. • Meanwhile, the introns-late theory also has a hard time explaining the usefulness of introns. One possibility is, "Introns originated to circumvent the problem of the random distribution of stop codons in random primordial sequences"
Capping and Polyadenylation • In eukaryotes, the RNA is processed at both ends before it is spliced. • At the 5' end, a cap is added consisting of a modified GTP (guanosine triphosphate). This occurs at the beginning of transcription. The 5' cap is used as a recognition signal for ribosomes to bind to the mRNA. At the 3' end, a poly(A) tail of 150 or more adenine nucleotides is added. The tail plays a role in the stability of the mRNA. • The cap and tail also protect the mRNA from degradation.
Translation • Ribosomes • mRNA • tRNA, tRNA-acyl synthetase • Amino Acids • Initiation • Elongation • Termination
Ribosomes • Composed of rRNA and proteins • Large and small subunits lock together to translate mRNA
The Nucleolus – Home of Ribosome Assembly • The nucleolus is located inside the nucleus. There is no membrane separating the nucleolus from the rest of the nucleus. • Though most nuclei have one nucleolus, the number ranges from zero to several because of their transient structure. • Nucleoli appear as dark, dense, irregular shaped areas of fibers and granules in the cell's nucleus. • Only plant and animal cells contain nucleoli. • They are made of proteins and ribonucleic acid, or RNA, and contain proteins, ribosomal RNA, and ribosomes that are being synthesized. • The genetic information needed to create ribosomal proteins is copied from the nucleus by messenger RNA, which then takes it to the cell cytoplasm. • The cytoplasm then takes the information and transfers it to the ribosomes in the cytoplasm. • This protein then goes into the nucleus and with the other ribosmal RNA subunits creates the two blocks that make up a complete ribosome.
Aminoacyl-tRNA Synthatase An enzyme that adds amino acids to the 3’ end of the free tRNA
Translation Initiation E, P and A sites Each ribosome has a binding site for mRNA and three binding sites for tRNA molecules.The P site holds the tRNA carrying the growing polypeptide chain.The A site carries the tRNA with the next amino acid.Discharged tRNAs leave the ribosome at the E site
Termination When the stop codon enters the ribosome, a protein called a release factor enters the A site and hydrolyzes the bond between the tRNA in the P site and the last amino acid of the polypeptide chain. This frees the polypeptide and breaks up the ribosomal subunits.
Elongation • mRNA are translated in the 5’ – 3’ direction • The polypeptide chain grows from the NH2 (N-Terminus) end to COOH (C-Terminus)end
The Dictionary of The Genetic Code There are 64 possible codons that can be produced with 4 bases ATGC read in sets of 3 43 = 64 61 of these 64 codons code for amino acids 3 of the 64 codons are called STOP codons and terminate the translation process. The STOP codons do not code for amino acids.
UTRs • The mRNA also contains regions that are not translated. In eukaryotes the 5' untranslated region and the 3' untranslated region contain a methyl guanine cap and polyA tail respectively.
Polyribosomes • Each mRNA is translated by multiple ribosomes. • So each mRNA transcripts gives rise to multiple polypeptide chains • Polyribosomes Video
Polyribosomes in Prokaryotes • Prokaryotes can have transcription and translation occurring simultaneously. • WHY?
Get Help • http://www.phschool.com/science/biology_place/biocoach/translation/gencode.html
Bound versus Free Ribosomes and the role of the Endoplasmic Reticulum Some polypeptides have an ER signal sequence. The signal sequence is recognized by a Recognition Particle, or SRP. This is then bound to a receptor. This complex guides the protein through a channel like region. It also consists of a docking site for the ribosome.
Those Funny Bases in tRNA • Inosine (a form of Adenine, a pre-cursor to adenine) It is usually found in the anticodon region • Pseudoruidine (most common modified base it is an isomer of uridine) • Dihydrouridine – is a uridine with 2 extra hydrogens – a more saturated version of uridine • Thymine – although not usually found in RNA, it is in tRNA
Mutations • Single-base Substitutions • Single base Insertions and Deletions – frame-shift mutations
Substitutions - Missense mutations A single base, say an A, becomes replaced by another. Single base substitutions are also called point mutations. EXAMPLE: sickle-cell disease The replacement of A by T at the 17th nucleotide of the gene for the beta chain of hemoglobin changes the codon GAG (for glutamic acid) to GTG (which encodes valine). Thus the 6th amino acid in the chain becomes valine instead of glutamic acid.
Substitutions – Nonsense Mutations With a nonsense mutation, the new nucleotide changes a codon that specified an amino acid to one of the STOP codons (TAA, TAG, or TGA). Therefore, translation of the messenger RNA transcribed from this mutant gene will stop prematurely. The earlier in the gene that this occurs, the more truncated the protein product and the more likely that it will be unable to function.
Substitutions - Silent mutations Most amino acids are encoded by several different codons. For example, if the third base in the TCT codon for serine is changed to any one of the other three bases, serine will still be encoded. Such mutations are said to be silent because they cause no change in their product and cannot be detected without sequencing the gene (or its mRNA).
Insertions and Deletions Extra base pairs may be added (insertions) or removed (deletions) from the DNA of a gene. This usually causes a shift in the reading frame and changes the amino acid sequence of the protein from that point onward. Frameshifts often create new STOP codons and thus generate nonsense mutations. Perhaps that is just as well as the protein would probably be too garbled anyway to be useful to the cell.
Each mRNA has 3 Reading Frames • Each reading frame will translate into a completely different protein. • However the correct reading frame is set by several initiation factors and by the fact that the start codon for protein synthesis is always AUG, which codes for methionine. • Therefore in all proteins, at least as they are synthesized on the ribosome, their first amino acid is always methionine
Mutations: Thymine Dimers • A thymine dimer is the covalent bonding of two adjacent thymine residues within a DNA molecule. • Thymine dimers usually occur in response to ultraviolet radiation or chemical mutagenic agents. • Create kinks in DNA • Can be repaired by certain enzymes
Xeroderma Pigmentosa • Xeroderma pigmentosa, or XP, is an autosomal recessive genetic disorder . • In XP, thymine dimers in DNA caused by ultraviolet (UV) light cannot be repaired due to mutations in the genes that code for the repair enzymes. Therefore, the repair enzymes(proteins) are not made. • This disorder leads to multiple basaliomas and other skin malignancies at a young age. • In severe cases, it is necessary to avoid sunlight completely. • The two most common causes of death for XP victims are metastatic malignant melanoma and squamous cell carcinoma. • For some reason, XP is about six times more common in Japanese people than in other groups.
Wobble Base Pairing • The presence of more than one codon for a given amino acid raises the issue of how many tRNAs are necessary to read the code. • You could have one for each codon, but it turns out that there are less than this (~45). • The reason has to do with what Crick called "wobble base pairing". • Wobble refers to non Watson-Crick base pairing that can take place at the third position of the codon and first position of the anticodon. • The wobble pair is so-called because the base has shifted ("wobbled") in order to make the hydrogen bonding work.
The Wobble Rules Wobble Rules: Read as 5' position in anticodon pairs with 3' position in codon: G pairs with C or U; C pairs with G; A pairs with U; U pairs with A or G; I pairs with A, U, or C Note that the anticodon position in the tRNA can also have the base inosine (I), a purine that is not present in the messenger RNA (codon)
Euchromatin • Euchromatin is DNA (true chromatin) that is actively transcribed, because it contains all the normally functional genes • These regions of a chromosome are very “relaxed” or least condensed during interphase • These parts of the chromosome stain poorly or not at all;
Heterochromatin • Heterochromatin on the other hand, is densely staining and condensed chromosomal regions • It is, for the most part, genetically inert. chromatin that remains tightly coiled (and darkly staining) throughout the cell cycle.
Role of histones • They are positively charged and therefore, the negatively charged DNA molecule is attracted to them • They condense 6 feet of DNA so that it would fit inside the nucleus of each cell
Histone Acetylation • Acetylation of the lysine residues at the N terminus of histone proteins removes positive charges, thereby reducing the affinity between histones and DNA. This makes RNA polymerase and transcription factors easier to access the promoter region. Therefore, in most cases, histone acetylation enhances transcription while histone deacetylation represses transcription • Histone acetylation is catalyzed by histone acetyltransferases (HATs) and histone deacetylation is catalyzed by histone deacetylases