Download

1 / 81
820 likes | 1.07k Vues
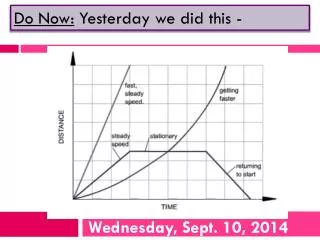
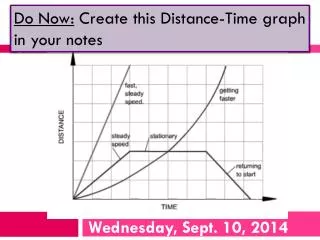
Revision Sept 2014. ELX305. Topics. Reliability Scada Pneumatics Boolean Algebra Timers and timing diagrams PLC programming. RELIABILITY. Definitions.

E N D
Revision Sept 2014 ELX305
Topics • Reliability • Scada • Pneumatics • Boolean Algebra • Timers and timing diagrams • PLC programming
Definitions • RELIABILITY, R(t), is defined as ‘the probability that a system will operate to an agreed level of performance for a specified period, subject to specific environmental conditions.’ (Probability of survival) • UNRELIABILITY, U(t), is ‘the probability that the system will fail in a specified time period’. (Probability of failure) • Since there are only two possibilities statistically : R(t) + U(t) = 1 • The definitions for Reliability and Unreliability are generally accepted, but do not take into account the age of a system. • It is possible to distinguish three periods in the operating life of a system - the “bathtub” curve
Region where l is ~ constant Bathtub Curve Failure rate
Constant Failure Rate • Research into the failure rate of a large range of aerospace industry products and components, showed that many electronic devices could be represented by a l(t) characterised by a short early failure region and an extended ‘constant failure’ region. (no ‘wear out’ region) (Bentley 1999) • Many electronic components fall into this category • Through quality techniques such as ‘burning in components and equipment, early failure can be significantly reduced or eliminated • So given this type of equipment and these quality interventions (burn in), failure rate can be considered to be constant
MTTF and MTBF • The term Mean Time Before Failure (MTBF) relates to equipment or systems that are repairable. It is measured by testing it for a total period of time (T) and recording the number of faults (N). Each fault is repaired and the equipment put back onto to test. The observed MTBF is given by M=T/N • In the case of MTTF this is a reliability measure which is suitable for ‘throw away’ items such as capacitors, resistors, transistors i.e. items that cannot be repaired. If a number of items were tested to failure the MTTF is again M= T/N
Reliability formulae R(t) = 1 + U(t) ……………………….(1) R(t) = e- lt……………………………(2) MTBF = ………………….(3) andtherefore l = 1/M ………….……(4) General formula to be used when l is not constant ……………….(5) (See Lesson 9 student guide for proofs)
Analysis of ‘Series’ systems • If a system consists of two or more units and for 'system success’ both must work, then in reliability terms the units are considered to be in series i.e. It is assumed that the failure of any unit occurs independently of the failure of the others
Series Systems From equation (2) Reliability of the series system
Series Systems Using Equations (3) M = 1/l therefore (4) l = 1/M failure rate of the system ls and Mean time between Failure Ms can be calculated
Series Systems EXAMPLE 1 (Tutorial sheet) In the following example, assuming a series reliability, find the system MTBF and Reliability in 1000 hours. Unit Type 1 2 3 Number of fails (N) 10 4 5 MTBF (hours) 4x105 1062x106
Series Systems EXAMPLE 2. A system consists of 4 elements, each having a probability of survival to 1000 hours R(1000) = 0.95 . What is the combined 1000 hour reliability of the system. Rs = R1xR2xR3 = .95 x .95 x .95 = 0.857
Analysis of Parallel Systems • If a system consists of two or more units which ‘normally’ contribute to the systems operation, and if one unit fails, the system continues to function, then the system is considered to be in parallel. • In series situation, ‘system success’ requires both units to succeed, whereas in parallel ‘system failure’ requires both units to fail, that is, the reliability logic is reversed.
Parallel Systems Therefore for a simple active parallel system the probability Us that the system is in the failed state is: Us = U1 x U2
Parallel Systems Since U(t) = 1 – R(t) It follows that: Reliability of the parallel network
Parallel Systems Missing steps Using this information
Parallel Systems - Example Two identical PLC units are connected in parallel. The reliability requirement is such that both units have to fail before the complete system fails. Each unit has a Mean Time Between Failure (MTBF) =105 hours. Calculate the reliability of the system RS in 104hours Solution
SCADA ELX305
Introduction • SCADA – Supervisory, Control And Data Acquisition • Generic term given to a computer based system which provides a user interface to connect to PLC’s and other devices • SCADA software packages enable data to be shown graphically in ‘real time’ and some cases can be used to supervise/control processes and equipment
SCADA Software • Many suppliers of SCADA software e.g. Wonderware, Microscan, Labview • Usually charged according to number of tags – (inputs/outputs) • Developers or design capability versus a user license • Some systems protected by a ‘dongle’, a hardware key
Networks • PLC’s or SCADA pc’s can be connected together or interconnected using a ‘network’ • The need to have a common data communications standard came about due to the rapid growth of PLC control in industrial applications. • PLC manufacturers initially developed their own individual network communications • End users faced problems when they had to interface products from different manufacturers • This led to the development of the Open Systems Interconnection (OSI) framework which identified the main features and function of communication networks that manufacturers have to adhere
Why network PLC’s • Allows ‘non-critical’ data to be transmitted and shared between controllers and computers. Typical applications include: • taking quality readings with a PLC and sending the data to a database computer • distributing recipes or special orders to batch processing equipment • remote monitoring and control of equipment SCADA
Ring and Bus Topologies • In the Ring and Bus topologies the network control is distributed between all of the PLC’s on the network. • The wiring only uses a single loop or run of wire. • Only one wire means that the network will slow down significantly as traffic increases. • It also requires more sophisticated network interfaces to determine when a PLC is allowed to transmit messages. • It is also possible for a problem on the network wires to halt the entire network.
Ring and Bus Topologies BUS • Advantages - Easy to implement/extend, Less cabling, cheap • Disadvantages - Administration difficult, Limited length/stations, loss of cable-loss of network. RING • Advantages - Easy to extend, Network collisions prevented (token passing) • Disadvantages - Slow, Fault Detection difficult, must break to extend
Star Topologies • The Star topology requires more cabling to connect each computer to an intelligent hub. • The network interfaces in the PLC’s are simpler, and the network is more reliable. • If one remote device fails then normally the rest of the network continues to function • Because of this it is often easier to fault find • Said to be deterministic –performance can be predicted. • This can be important in critical applications, especially in cases where the signal sampling and control output has to be strictly controlled.
Star Topology STAR • Advantages - Easy to expand, Fault detection easy, Deterministic, Non-centralised failures handled, • Disadvantages – Relatively expensive, Extra hardware needed, loss of hub catastrophic
Pros and Cons • For a factory environment the bus topology is popular. • The large number of wires required for a star configuration can be expensive and confusing. • The loop of wire required for a ring topology is also difficult to connect, and it can lead to ground loop problems. • Smaller bus networks can be connected into a ‘tree’ structure using repeaters. (see study guide lesson 8 pg.4) These boost the signal strength and allow the network to be made larger.
Network hardware • Various types of hardware are used to connect the devices together • These include routers, repeaters, hubs, bridges, gateways which transmit and control data Physical connection via cabling are terminated with 10base2 (BNC),10baseF (fibre optic) connectors. • Fibre optic networks are highly tolerant to interference but can need specialist to test/commission system. Cables can be prone to damage if not ran correctly, loss of or reduced signal faults can be difficult to trace
Types of transmission The transmission type determines the communication speed and noise immunity. • Baseband, simplest, where voltages are switched off and on according to signal bit states . This method is subject to noise, and operates at low speeds e.g. RS-232 • Carrierbandtransmission uses FSK (Frequency Shift Keying) that will switch a signal between two frequencies to indicate a true or false bit. Provides higher transmission speeds, with reduced noise effects • Broadband networks transmit data over more than one channel by using multiple carrier frequencies on the same wire.
Bus Network Topology • Only uses a single transmission wire for all nodes. • If all of the nodes decide to send messages simultaneously, the messages would be corrupted (a collision occurs). • There are a variety of methods for dealing with network collisions, and arbitration
Data Transfer • Data is sent of the network in ‘packets’ • Packet sizes can be different depending on the particular network • Data is organised in a ‘frame’ which is like a long serial byte. • Each bit of data and its position in the ‘serial byte’ has a specific purpose and meaning (protocol) • Error detection is normally provided to ensure data security using either checksum or CRC
Bus Network Collision Techniques • CSMA/CD (Collision Sense Multiple Access/Collision Detection) – if two nodes start talking and detect a collision then they will stop, wait a random time, and then start again. The time period is usually 1 cycle time (typically 50 microsecs), after which another attempt is made to transmit • CSMA/BA (Collision Sense Multiple Access/Bitwise Arbitration) – if two nodes start talking at the same time the will stop and use their node addresses to determine which one goes first.
Bus Network Collision Techniques • Master-Slave – one device on the network is the master and is the only one that may start communication. Slave devices will only respond to requests from the master. • Token Passing – A token, or permission to talk, is passed sequentially around a network so that only one station may talk at a time.
Bus Network Collision Techniques Pros and Cons • The token passing method is deterministic, but it may require that a node with an urgent message to wait to receive the token. • The master-slave method will put a single machine in charge of sending and receiving. This can be restrictive if multiple controllers are to exist on the same network. • The CSMA/CD and CSMA/BA methods will both allow nodes to talk when needed. But, as the number of collisions increase the network performance degrades quickly.
Control Valve Symbols • For every control valve status a square is drawn • The ports are indicated (on the initial status) :- Output Port ( Top ) Inlet Port ( Bottom ) 2/2 Way Directional Control Valve (Flow Switch) • Flow is indicated by an arrow ( No flow by lines at right angles )
Actuation of Control Valves :-1. Mechanical • General • Pushbutton • Lever Operated • Foot Pedal • Spring Return • Spring Centered • Roller • Idle Return Roller
Actuation of Control Valves :-2. Electrical / Pneumatic • Direct Pneumatic • Indirect Pneumatic • Pressure Release • Single Solenoid • Double Solenoid • Electro-Pneumatic
Describe this Control Valve ? • The control valve has two positions • The control valve has four ports • The control valve is operated by a Pushbutton and returned by a Spring 4/2 Way Directional Pushbutton Control Valve with Spring Return • The control valve changes the flow direction at the output ports
Single Acting Cylinder (SPRING RETURN) • Double Acting Cylinder • Double Acting Cylinder with double ended piston • Double Acting Cylinders with non-adjustable and adjustable cushioning on one or both ends Linear Actuators
2 Actuate Spring Return 2 Actuate Spring Return 3/2 Pneumatic Control Valve
Single Acting Cylinder (SPRING RETURN) 3/2 Pneumatic Control Valve driving a Linear Actuator • This is the simplest and cheapest form of cylinder. It only uses 1 port so can be controlled with a 3/2 valve. Particularly useful where many cylinders are needed e.g. automation applications where on/off push type actions are needed. Also used for controlling valves and flaps where on/off states are needed without speed control.
Non-Actuated • Actuated 2 2 2 2 Open Open 3/2 Pneumatic Control Valve driving a Linear Actuator What Happens if the Pressure Supply is lost ?
4 2 Actuate Spring Return 4 2 Actuate Spring Return 5/2 Pneumatic Control Valve
Non-Actuated • Actuated 4 2 4 2 Open Open 5/2 Pneumatic Control Valve driving a Linear Actuator What Happens if the Pressure Supply is lost ?