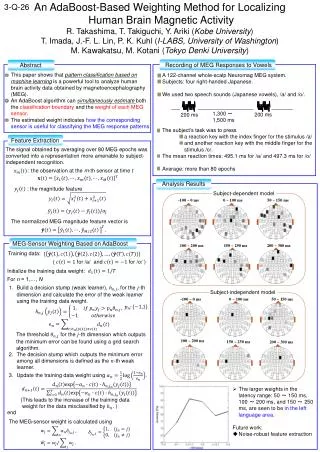
Adaboost Theory
Adaboost Theory. Exponential loss function of a classifier h : Suppose we have run Adaboost for T iterations. We have our ensemble classifier H T . Now suppose we run it for one additional iteration. Then we have a classifier H T +α T+ 1 h T+ 1 .


Adaboost Theory
E N D
Presentation Transcript
Adaboost Theory • Exponential loss function of a classifier h: Suppose we have run Adaboost for T iterations. We have our ensemble classifier HT. Now suppose we run it for one additional iteration. Then we have a classifier HT +αT+1hT+1. For simplicity, we’ll call this H + αh . Then:
We want to minimize this loss with respect to α. So we solve Solving this gives us
A similar kind of derivation can be given for the weight adjustment formula, See Zhi-Hua Zhou and Yang Yu. The AdaBoost algorithm. In: X. Wu and V. Kumar eds. The Top Ten Algorithms in Data Mining, Boca Raton, FL: Chapman & Hall, 2009.
Adaboost on UCI ML datasets(from Zhou and Yang chapter) • T = 50. • Three different base learning algorithms: • Decision stumps • Pruned decision trees • Unpruned decision trees attributei > threshold T F Class A Class B
From Schapire et al., Boosing the margin: A new explanation for the effectiveness of voting methods C4.5 error rate Adaboost error rate
Why does Adaboost work? • Reduces bias and variance • Increases classification margin with increasing T. • Increasing T doesn’t lead to overfitting!
Sources of Classifier Error: Bias, Variance, and Noise • Bias: • Classifier cannot learn the correct hypothesis (no matter what training data is given), and so incorrect hypothesis h is learned. The bias is the average error of h over all possible training sets. • Variance: • Training data is not representative enough of all data, so the learned classifier h varies from one training set to another. • Noise: • Training data contains errors, so incorrect hypothesis his learned.
Classification margin • Classification margin of example (x,y): • The magnitude of the classification margin is the strength of agreement of base classifiers, and the sign indicates whether the ensemble produced a correct classification.
From Schapire et al., Boosing the margin: A new explanation for the effectiveness of voting methods