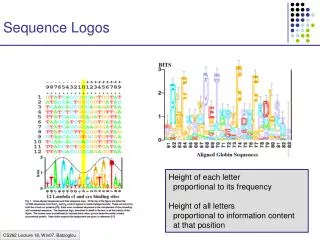
Sequence Logos
Sequence Logos. Height of each letter proportional to its frequency Height of all letters proportional to information content at that position. Probabilistic Motif: M ij ; 1 i W 1 j 4 M ij = Prob[ letter j, pos i ]

Sequence Logos
E N D
Presentation Transcript
Sequence Logos Height of each letter proportional to its frequency Height of all letters proportional to information content at that position
Probabilistic Motif: Mij; 1 i W 1 j 4 Mij = Prob[ letter j, pos i ] Find best M, and positions p1,…, pN in sequences Combinatorial Motif M: m1…mW Some of the mi’s blank Find M that occurs in all si with k differences Problem Definition Given a collection of promoter sequences s1,…, sN of genes with common expression
Discrete Formulations Given sequences S = {x1, …, xn} • A motif W is a consensus string w1…wK • Find motif W* with “best” match to x1, …, xn Definition of “best”: d(W, xi) = min hamming dist. between W and any word in xi d(W, S) = i d(W, xi)
Exhaustive Searches 1. Pattern-driven algorithm: For W = AA…A to TT…T (4K possibilities) Find d( W, S ) Report W* = argmin( d(W, S) ) Running time: O( K N 4K ) (where N = i |xi|) Advantage:Finds provably “best” motif W Disadvantage:Time
Exhaustive Searches 2. Sample-driven algorithm: For W = any K-long word occurring in some xi Find d( W, S ) Report W* = argmin( d( W, S ) ) or, Report a local improvement of W* Running time: O( K N2 ) Advantage: Time Disadvantage: If the true motif is weak and does not occur in data then a random motif may score better than any instance of true motif
MULTIPROFILER • Extended sample-driven approach Given a K-long word W, define: Nα(W) = words W’ in S s.t. d(W,W’) α Idea: Assume W is occurrence of true motif W* Will use Nα(W) to correct “errors” in W
Example W* = GATTACA AGATCGCATCGTAGCTGCATGTAGCTGC GCATGCTACTAGTCGTTTTACTACATAG ACGTGACTAGATAGCATGAGCGATCGTA AGCTAGCTAGCGATCACTGTGCGTGTCA ATGCTACTGTCTGTGCTGTGATTATCGA GGAGTCCACTAGCATCGATGGGCATCGG TATGCATCGATAACGCTGCGATTATGCG TAGAGTGCAGTATGATGCTGCTAGCGTG CTATCTACTATCGAGATTTTATCGTCCG TATTTTACAAGCATGCTGCTTTTAGCAG GGCGGCATCATCTGAGGACGGGATTACT TTTGTGGTCTGTACTATGATCCCAATGC √ d = 3 d = 4 W = GATCGCA √ d = 2 d = 4 Let = 3 d = 4 N(W): √ d = 3 √ d = 2 TACTACA GATCACT GATAACG GAGTGCA GATTTTA GATTACT GATCCCA √ d = 3 d = 4 √ d = 3 √ d = 1
MULTIPROFILER Assume W differs from true motif W* in at most L positions Define: A wordlet G of W is a L-long pattern with blanks, differing from W • L is smaller than the word length K Example: K = 7; L = 3 W = ACGTTGA G = --A--CG
MULTIPROFILER Algorithm: For each W in S: For L = 1 to Lmax • Find the α-neighbors of W in S Nα(W) • Find all “strong” L-long wordlets G in Na(W) • For each wordlet G, • Modify W by the wordlet G W’ • Compute d(W’, S) Report W* = argmin d(W’, S) Step 2 above: Smaller motif-finding problem; Use exhaustive search
Example AGATCGCATCGTAGCTGCATGTAGCTGC GCATGCTACTAGTCGTTTTACTACATAG ACGTGACTAGATAGCATGAGCGATCGTA AGCTAGCTAGCGATCACTGTGCGTGTCA ATGCTACTGTCTGTGCTGTGATTATCGA GGAGTCCACTAGCATCGATGGGCATCGG TATGCATCGATAACGCTGCGATTATGCG TAGAGTGCAGTATGATGCTGCTAGCGTG CTATCTACTATCGAGATTTTATCGTCCG TATTTTACAAGCATGCTGCTTTTAGCAG GGCGGCATCATCTGAGGACGGGATTACT TTTGTGGTCTGTACTATGATCCCAATGC W* = GATTACA L = ---TA-- W = GATCGCA N(W): TACTACAd = 0 GATCACTd = 1 GATAACGd = 1 GAGTGCAd = 1 GATTTTAd = 1 GATTACTd = 0 GATCCCA d = 2
Example AGATCGCATCGTAGCTGCATGTAGCTGC GCATGCTACTAGTCGTTTTACTACATAG ACGTGACTAGATAGCATGAGCGATCGTA AGCTAGCTAGCGATCACTGTGCGTGTCA ATGCTACTGTCTGTGCTGTGATTATCGA GGAGTCCACTAGCATCGATGGGCATCGG TATGCATCGATAACGCTGCGATTATGCG TAGAGTGCAGTATGATGCTGCTAGCGTG CTATCTACTATCGAGATTTTATCGTCCG TATTTTACAAGCATGCTGCTTTTAGCAG GGCGGCATCATCTGAGGACGGGATTACT TTTGTGGTCTGTACTATGATCCCAATGC W* = GATTACA L = ---TA-- W = GATCGCA N(W): TACTACAd = 0 GATCACTd = 1 GATAACGd = 1 GAGTGCAd = 1 GATTTTAd = 1 GATTACTd = 0 GATCCCA d = 2
motif All K-long words background Expectation Maximization S: A bag of k-long words Algorithm (sketch): • Given genomic sequences list all k-long words • Assume each word is motif or background • Find likeliest Motif Model Background Model classification of words into either Motif or Background
motif background Expectation Maximization Given sequences x1, …, xN, • List all k-long words X1,…, Xn • Define motif model: M = (M1,…, MK) Mi = (Mi1,…, Mi4) (assume {A, C, G, T}) where Mij = Prob[ letter j occurs in motif position i ] • Define background model: B = B1, …, B4 Bi = Prob[ letter j in background sequence ] 1 – M1 MK B M1 A C G T
motif background Expectation Maximization Define Zi1 = { 1, if Xi is motif; 0, otherwise } Zi2 = { 0, if Xi is motif; 1, otherwise } Given a word Xi = x[s]…x[s+k], P[ Xi, Zi1=1 ] = M1x[s]…Mkx[s+k] P[ Xi, Zi2=1 ] = (1 – ) Bx[s]…Bx[s+k] Let 1 = ; 2 = (1 – ) 1 – M1 MK B M1 A C G T
Expectation Maximization 1 – Define: Parameter space = (M, B) 1: Motif; 2: Background Objective: Maximize log likelihood of model: M1 MK B M1 A C G T
Expectation Maximization • Maximize expected likelihood, in iteration of two steps: Expectation: Find expected value of log likelihood: Maximization: Maximize expected value over ,
Expectation Maximization: E-step Expectation: Find expected value of log likelihood: where expected values of Z can be computed as follows:
Expectation Maximization: M-step Maximization: Maximize expected value over and independently For , this has the following solution: (we won’t prove it) Effectively, NEW is the expected # of motifs per position, given our current parameters
Expectation Maximization: M-step • For = (M, B), define cjk = E[ # times letter k appears in motif position j] c0k = E[ # times letter k appears in background] • cij values are calculated easily from Z* values It then follows: to not allow any 0’s, add pseudocounts
Initial Parameters Matter! Consider the following artificial example: 6-mers X1, …, Xn: (n = 2000) • 990 words “AAAAAA” • 990 words “CCCCCC” • 20 words “ACACAC” Some local maxima: • = 49.5%; B = 100/101 C, 1/101 A M = 100% AAAAAA • = 1%; B = 50% C, 50% A M = 100% ACACAC
Overview of EM Algorithm • Initialize parameters = (M, B), : • Try different values of from N-1/2 up to 1/(2K) • Repeat: • Expectation • Maximization • Until change in = (M, B), falls below • Report results for several “good”
Gibbs Sampling • Given: • Sequences x1, …, xN, • motif length K, • background B, • Find: • Model M • Locations a1,…, aN in x1, …, xN Maximizing log-odds likelihood ratio:
Gibbs Sampling • AlignACE: first statistical motif finder • BioProspector: improved version of AlignACE Algorithm (sketch): • Initialization: • Select random locations in sequences x1, …, xN • Compute an initial model M from these locations • Sampling Iterations: • Remove one sequence xi • Recalculate model • Pick a new location of motif in xi according to probability the location is a motif occurrence
Gibbs Sampling Initialization: • Select random locations 1,…, N in x1, …, xN • For these locations, compute M: • where j are pseudocounts to avoid 0s, • and B = j j • That is, Mkj is the number of occurrences of letter j in motif position k, over the total
Gibbs Sampling Predictive Update: • Select a sequence x = xi • Remove xi, recompute model: M • where j are pseudocounts to avoid 0s, • and B = j j
Gibbs Sampling Sampling: For every K-long word xj,…,xj+k-1 in x: Qj = Prob[ word | motif ] = M(1,xj)…M(k,xj+k-1) Pi = Prob[ word | background ] B(xj)…B(xj+k-1) Let Sample a random new position ai according to the probabilities A1,…, A|x|-k+1. Prob 0 |x|
Gibbs Sampling Running Gibbs Sampling: • Initialize • Run until convergence • Repeat 1,2 several times, report common motifs
Advantages / Disadvantages • Very similar to EM Advantages: • Easier to implement • Less dependent on initial parameters • More versatile, easier to enhance with heuristics Disadvantages: • More dependent on all sequences to exhibit the motif • Less systematic search of initial parameter space
Repeats, and a Better Background Model • Repeat DNA can be confused as motif • Especially low-complexity CACACA… AAAAA, etc. Solution: more elaborate background model 0th order: B = { pA, pC, pG, pT } 1st order: B = { P(A|A), P(A|C), …, P(T|T) } … Kth order: B = { P(X | b1…bK); X, bi{A,C,G,T} } Has been applied to EM and Gibbs (up to 3rd order)
Example Application: Motifs in Yeast Group: Tavazoie et al. 1999, G. Church’s lab, Harvard Data: • Microarrays on 6,220 mRNAs from yeast Affymetrix chips (Cho et al.) • 15 time points across two cell cycles • Clustering genes according to common expression • K-means clustering -> 30 clusters, 50-190 genes/cluster • Clusters correlate well with known function • AlignACE motif finding • 600-long upstream regions
Motifs are preferentially conserved across evolution Gal4 TBP GAL4 GAL4 GAL4 GAL4 MIG1 MIG1 TBP Factor footprint Conservation island Gal10 Gal1 GAL10 Scer TTATATTGAATTTTCAAAAATTCTTACTTTTTTTTTGGATGGACGCAAAGAAGTTTAATAATCATATTACATGGCATTACCACCATATACA Spar CTATGTTGATCTTTTCAGAATTTTT-CACTATATTAAGATGGGTGCAAAGAAGTGTGATTATTATATTACATCGCTTTCCTATCATACACA Smik GTATATTGAATTTTTCAGTTTTTTTTCACTATCTTCAAGGTTATGTAAAAAA-TGTCAAGATAATATTACATTTCGTTACTATCATACACA Sbay TTTTTTTGATTTCTTTAGTTTTCTTTCTTTAACTTCAAAATTATAAAAGAAAGTGTAGTCACATCATGCTATCT-GTCACTATCACATATA * * **** * * * ** ** * * ** ** ** * * * ** ** * * * ** * * * Scer TATCCATATCTAATCTTACTTATATGTTGT-GGAAAT-GTAAAGAGCCCCATTATCTTAGCCTAAAAAAACC--TTCTCTTTGGAACTTTCAGTAATACG Spar TATCCATATCTAGTCTTACTTATATGTTGT-GAGAGT-GTTGATAACCCCAGTATCTTAACCCAAGAAAGCC--TT-TCTATGAAACTTGAACTG-TACG Smik TACCGATGTCTAGTCTTACTTATATGTTAC-GGGAATTGTTGGTAATCCCAGTCTCCCAGATCAAAAAAGGT--CTTTCTATGGAGCTTTG-CTA-TATG Sbay TAGATATTTCTGATCTTTCTTATATATTATAGAGAGATGCCAATAAACGTGCTACCTCGAACAAAAGAAGGGGATTTTCTGTAGGGCTTTCCCTATTTTG ** ** *** **** ******* ** * * * * * * * ** ** * *** * *** * * * Scer CTTAACTGCTCATTGC-----TATATTGAAGTACGGATTAGAAGCCGCCGAGCGGGCGACAGCCCTCCGACGGAAGACTCTCCTCCGTGCGTCCTCGTCT Spar CTAAACTGCTCATTGC-----AATATTGAAGTACGGATCAGAAGCCGCCGAGCGGACGACAGCCCTCCGACGGAATATTCCCCTCCGTGCGTCGCCGTCT Smik TTTAGCTGTTCAAG--------ATATTGAAATACGGATGAGAAGCCGCCGAACGGACGACAATTCCCCGACGGAACATTCTCCTCCGCGCGGCGTCCTCT Sbay TCTTATTGTCCATTACTTCGCAATGTTGAAATACGGATCAGAAGCTGCCGACCGGATGACAGTACTCCGGCGGAAAACTGTCCTCCGTGCGAAGTCGTCT ** ** ** ***** ******* ****** ***** *** **** * *** ***** * * ****** *** * *** Scer TCACCGG-TCGCGTTCCTGAAACGCAGATGTGCCTCGCGCCGCACTGCTCCGAACAATAAAGATTCTACAA-----TACTAGCTTTT--ATGGTTATGAA Spar TCGTCGGGTTGTGTCCCTTAA-CATCGATGTACCTCGCGCCGCCCTGCTCCGAACAATAAGGATTCTACAAGAAA-TACTTGTTTTTTTATGGTTATGAC Smik ACGTTGG-TCGCGTCCCTGAA-CATAGGTACGGCTCGCACCACCGTGGTCCGAACTATAATACTGGCATAAAGAGGTACTAATTTCT--ACGGTGATGCC Sbay GTG-CGGATCACGTCCCTGAT-TACTGAAGCGTCTCGCCCCGCCATACCCCGAACAATGCAAATGCAAGAACAAA-TGCCTGTAGTG--GCAGTTATGGT ** * ** *** * * ***** ** * * ****** ** * * ** * * ** *** Scer GAGGA-AAAATTGGCAGTAA----CCTGGCCCCACAAACCTT-CAAATTAACGAATCAAATTAACAACCATA-GGATGATAATGCGA------TTAG--T Spar AGGAACAAAATAAGCAGCCC----ACTGACCCCATATACCTTTCAAACTATTGAATCAAATTGGCCAGCATA-TGGTAATAGTACAG------TTAG--G Smik CAACGCAAAATAAACAGTCC----CCCGGCCCCACATACCTT-CAAATCGATGCGTAAAACTGGCTAGCATA-GAATTTTGGTAGCAA-AATATTAG--G Sbay GAACGTGAAATGACAATTCCTTGCCCCT-CCCCAATATACTTTGTTCCGTGTACAGCACACTGGATAGAACAATGATGGGGTTGCGGTCAAGCCTACTCG **** * * ***** *** * * * * * * * * ** Scer TTTTTAGCCTTATTTCTGGGGTAATTAATCAGCGAAGCG--ATGATTTTT-GATCTATTAACAGATATATAAATGGAAAAGCTGCATAACCAC-----TT Spar GTTTT--TCTTATTCCTGAGACAATTCATCCGCAAAAAATAATGGTTTTT-GGTCTATTAGCAAACATATAAATGCAAAAGTTGCATAGCCAC-----TT Smik TTCTCA--CCTTTCTCTGTGATAATTCATCACCGAAATG--ATGGTTTA--GGACTATTAGCAAACATATAAATGCAAAAGTCGCAGAGATCA-----AT Sbay TTTTCCGTTTTACTTCTGTAGTGGCTCAT--GCAGAAAGTAATGGTTTTCTGTTCCTTTTGCAAACATATAAATATGAAAGTAAGATCGCCTCAATTGTA * * * *** * ** * * *** *** * * ** ** * ******** **** * Scer TAACTAATACTTTCAACATTTTCAGT--TTGTATTACTT-CTTATTCAAAT----GTCATAAAAGTATCAACA-AAAAATTGTTAATATACCTCTATACT Spar TAAATAC-ATTTGCTCCTCCAAGATT--TTTAATTTCGT-TTTGTTTTATT----GTCATGGAAATATTAACA-ACAAGTAGTTAATATACATCTATACT Smik TCATTCC-ATTCGAACCTTTGAGACTAATTATATTTAGTACTAGTTTTCTTTGGAGTTATAGAAATACCAAAA-AAAAATAGTCAGTATCTATACATACA Sbay TAGTTTTTCTTTATTCCGTTTGTACTTCTTAGATTTGTTATTTCCGGTTTTACTTTGTCTCCAATTATCAAAACATCAATAACAAGTATTCAACATTTGT * * * * * * ** *** * * * * ** ** ** * * * * * *** * Scer TTAA-CGTCAAGGA---GAAAAAACTATA Spar TTAT-CGTCAAGGAAA-GAACAAACTATA Smik TCGTTCATCAAGAA----AAAAAACTA.. Sbay TTATCCCAAAAAAACAACAACAACATATA * * ** * ** ** ** Is this enough to discover motifs? No. GAL1 slide credits: M. Kellis
Comparison-based Regulatory Motif Discovery Study known motifs Derive conservation rules Discover novel motifs slide credits: M. Kellis
Erra Erra Erra Dog Mouse Rat Conservation rate: 37% Known motifs are frequently conserved Human • Across the human promoter regions, the Erra motif: • appears 434 times • is conserved 162 times • Compare to random control motifs • Conservation rate of control motifs: 6.8% • Erra enrichment: 5.4-fold • Erra p-value < 10-50 (25 standard deviations under binomial) Motif Conservation Score (MCS) slide credits: M. Kellis
Finding conserved motifs in whole genomesM. Kellis PhD Thesis on yeasts, X. Xie & M. Kellis on mammals • Define seed “mini-motifs” • Filter and isolate mini-motifs that are more conserved than average • Extend mini-motifs to full motifs • Validate against known databases of motifs & annotations • Report novel motifs N T C A A C G slide credits: M. Kellis
CGG-11-CCG Test 1: Intergenic conservation Conserved count Total count slide credits: M. Kellis
CGG-11-CCG Higher Conservation in Genes Test 2: Intergenic vs. Coding Intergenic Conservation Coding Conservation slide credits: M. Kellis
CGG-11-CCG Downstream motifs? Most Patterns Test 3: Upstream vs. Downstream Upstream Conservation Downstream Conservation slide credits: M. Kellis
5 6 Y R T C G C A C G A Extend Extend Extend Collapse Extend G T C A C A C G A A T C R Y A C G A Collapse Collapse Collapse R T C G C A C G A Merge 72 Full motifs Full Motifs Constructing full motifs Test 1 Test 2 Test 3 2,000 Mini-motifs R T C A A C G R slide credits: M. Kellis
New New New New New Summary for promoter motifs • 174 promoter motifs • 70 match known TF motifs • 115 expression enrichment • 60 show positional bias 75% have evidence • Control sequences < 2% match known TF motifs < 5% expression enrichment < 3% show positional bias < 7% false positives Most discovered motifs are likely to be functional slide credits: M. Kellis