Identifying Patterns in Time Series Data
220 likes | 365 Vues
Identifying Patterns in Time Series Data. Daniel Lewis 04/06/06. Time Series Data. Definition: “An ordered set of m real-valued variables” How can patterns that occur in time series data be located?. Comparing Time Series. Euclidean Distance:. Adaptive Piecewise Constant Approximation.

Identifying Patterns in Time Series Data
E N D
Presentation Transcript
Identifying Patterns in Time Series Data Daniel Lewis 04/06/06
Time Series Data • Definition: • “An ordered set of m real-valued variables” • How can patterns that occur in time series data be located?
Comparing Time Series • Euclidean Distance:
Adaptive Piecewise Constant Approximation • Segments of time series data are represented by 2 values, the mean value of all points in the segment and the right endpoint of the segment • Allows large queries to be quickly compared, but APCA representations must be created first.
APCA (cont') • Data Compression allows for faster search • Can be used for indexing large series • Can handle large queries • But what if we want to identify patterns in streaming time series data?
Pattern Recognition • For a given query q and a time series s, if the Euclidean distance between q and s < r, the series match • r: user defined, application specific threshold
Detecting Patterns in Streaming Data • Brute Force Method: • P1 ,.., Pn : Set of patterns of length k • S: Input Stream • For every possible substring of length k in s, calculate the distance between the substring and all n patterns • This method is obviously extremely costly in the case of a large pattern set and a large input stream • O(n(|S| - k))
Speeding Up Pattern Identification • Early Abandoning: • If at any point error > r 2, we can stop computation
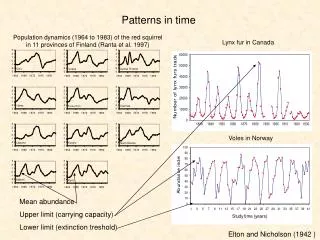
Wedge Creation • Combine multiple patterns into a wedge: • Define Upper Limit: • Ui = max( C1i , .. , Cki) • Define Lower Limit: • Li = min( C1i , .. , Cki) • This produces a wedge such that:
Wedge Comparison • Distance Between a Query and a Wedge: • If distance > r, then the distance between the query and all component patterns > r, allowing you to eliminate multiple possible matches with a single comparison
Hierarchical Wedges • The usefulness of any wedge is determined by the similarity of the patterns used in its construction. • More similar patterns create smaller, more useful wedges • Patterns can be combined in a tree-like pattern to produce a hierarchy of wedges
Atomic Wedgie • Preparation: • All patterns are clustered by similarity • The most similar patterns are combined into wedges • The resulting wedges are combined to form larger, less specific wedges
Atomic Wedgie (cont') • Usage: • When streaming data arrives, each substring of length k is first compared to the largest wedge, if dist > r, comparison stops, else, the distance is compared against the two component wedges, eliminating any branches where the distance exceeds r. • Eventually, all branches are eliminated or a single (atomic) pattern is matched
Atomic Wedgie Optimization • Optimization: • Summation is order independent • Large sections are less likely to increase error than small sections • Thus, if error is summed starting with the smallest sections first, the requirements for early abandon are more likely to be met earlier
Atomic Wedgie (cont') • Advantages: • If wedges are well formed, large speed increases can occur • A large number of similar possible patterns can be analyzed quickly • Disadvantages: • If wedges are poorly formed, the time required will exceed the Brute Force Method • Dissimilar patterns are not handled well
Special Considerations • The choice of r (similarity threshold) is of great importance: • if r is too large, a substring can match too many patterns to be useful • if r is too small, too little matching may occur • Good Choice: • r = average distance from any pattern to its nearest neighbor
Chakrabarti, K., Keogh, E., Mehrotra, S., and Pazzani, M., Locally Adaptive Dimensionality Reduction for Indexing Large Time Series Databases, ACM Transactions on Database Systems, Vol 27, 2002. Wei, L., Keogh, E., Van Herle, H., Mafra-Neto, A., Atomic Wedgie: Efficient Query Filtering for Streaming Times Series, Data Mining, Fifth IEEE International Conference on 27-30 Nov. 2005 Page(s):490 - 497 References