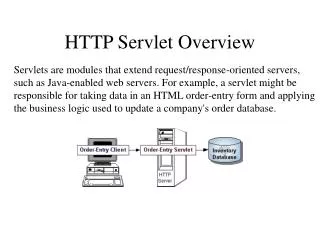
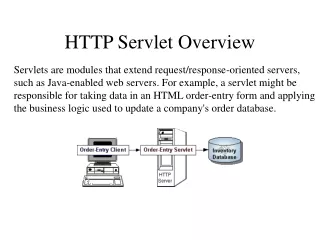
HTTP Overview
HTTP Overview. User Group Meeting. The Technology Firm www.thetechfirm.com. HTTP Information. HTTP (0.9) Is the original version of HTTP. HTTP (1.0) is stateless, since the TCP ports are closed after each use. (RFC1945)


HTTP Overview
E N D
Presentation Transcript
HTTP Overview User Group Meeting The Technology Firm www.thetechfirm.com
HTTP Information • HTTP (0.9) Is the original version of HTTP. • HTTP (1.0) is stateless, since the TCP ports are closed after each use. (RFC1945) • This implementation causes a lot of overhead/latency since many TCP port connections have to be setup during a HTTP session. This includes process includes inefficiencies like the Slow Start Algorithm. • Persistent HTTP (1.1) addresses slow start overhead by keeping the initial connection open for subsequent requests. Therefore, there is no need to open new TCP connections. (RFC2068) Or as many TCP connections.
Performance Enhancements • HTTP 1.1 should be noticeably faster than HTTP 1.0, particularly when fetching many documents from the same server. • The main enhancement involves "persistent connections." • Under HTTP 1.0, the browser opens a new TCP connection to a server for every URL it fetches. If an HTML document contains three unique inline graphics, the browser will open a total of four TCP connections: one for each image, and one for the HTML document itself. But each new TCP connection incurs a series of delays: one while the browser looks up the server's hostname in the DNS, another while browser and server perform the initial TCP handshake, and a third while the browser tears down the connection. In addition, there's a slowdown at the beginning of each connection as the TCP/IP protocol adjusts its transmission speed to match the available bandwidth. • HTTP 1.1 allows several URL requests to be piggybacked on top of a single TCP session. When the browser first contacts the server and downloads an HTML document, the connection remains open. The browser can then use the connection to request additional documents from the server; for example, the URL for each inline image. Browsers can "pipeline" requests for a new URL, submitting a request without waiting for the previous one to complete. A series of new HTTP headers allows the browser and server to negotiate persistent connections and gracefully terminate the session. • The HTTP 1.1 handling of persistent connections is similar to the "keep-alive" extension that Netscape introduced some time back, and is, in fact, backward compatible. In HTTP 1.1, however, persistent connections are the default. In addition, various differences in detail allow HTTP 1.1 connections to work correctly across Web proxies, and give them a slight performance edge.
Reliability Enhancements • How many times have you waited to download a large document over a noisy link, only to have the remote server time out before you got to the end? Or how many times have you interrupted a transfer to avoid waiting for a long page to download, only to press "reload" when you realize that you really do want the whole thing? • HTTP 1.1 introduces byte-range fetches to accommodate this frequent problem. If a partial document is sitting in your browser's cache (or in the cache of a proxy server, for that matter), the browser can ask the server to retrieve just the part that's missing. Byte-range requests work correctly even if the document has changed since it was first downloaded: In such a case, the server will return the entire document rather than the requested section. • Another enhancement in HTTP 1.1 provides a different way of specifying document size. Developers who write CGI scripts have long been aware of the problem of specifying the content length in dynamically created documents. Ideally, CGI scripts should send the user a Content-length header so that her browser can display the "percent complete" in its status bar. However, the content length has to be sent before the rest of the document, and it's often difficult to know the length in advance. As a result, most developers don't provide it, so users get no feedback on the progress of a script-generated document and have no way of knowing whether the document was transferred completely. With HTTP 1.1's new "chunked" document transfer, documents are transmitted in small chunks, each of which is preceded by a byte count. In addition to providing download size information, chunked transfers also check integrity -- any missing text will be noticed. • HTTP 1.1 also introduces a more formal type of document-integrity checking: A new HTTP header, Content-MD5, allows servers to include with each transmitted document a message-integrity check (MIC) value that consists of an MD5 hash of the document's contents. If the document is corrupted during transmission, its MD5 hash will no longer match the MIC, and the browser will detect the problem.
HTTP 1.1 Security Enhancements • New HTTP 1.1 features modestly enhance the security of the HTTP protocol without introducing the overhead of full end-to-end encryption. • To password-protect a file or directory, HTTP 1.1 has introduced "Digest" authentication to replace the truly awful Basic authentication that has plagued Web users ever since HTTP 1.0 was first introduced. Now, by supplying a valid account name and password, a remote user can gain access to a protected resource. • With Basic authentication, the user's account name and password were sent across the network as plaintext, allowing anyone with access to a packet sniffer somewhere along the route to intercept the information and then access the protected documents and any other documents in the same tree. • With digest authentication, passwords are never transmitted across the network. Instead, when the user tries to access a protected document, the server sends the browser a random "challenge" string. In response to a prompt, the user types in her name and password; her browser uses these values to encrypt the challenge string. The encrypted challenge is now returned to the server, which uses the user's stored name and password to encrypt the challenge again. If the server derives an encrypted challenge value identical to what the browser has returned, then the server can be confident that the user knows the correct password. • Digest authentication can be made more secure by incorporating the name of the desired URL, the browser's IP address, and a timestamp into the random challenge. This creates a challenge that can only be used by a particular machine to fetch a single URL during a limited stretch of time, effectively preventing anyone from intercepting the encrypted challenge and "replaying" it to the server to gain access to other resources. An optional feature of the protocol allows a message authentication check (MAC) to be added to returned documents, preventing them from being intercepted and modified by a malicious third party.
Caching • Fully one third of the HTTP 1.1 specification deals with document caching. Anyone who has ever submitted a query to a CGI script and then pressed the Back button knows that certain browsers implement local caching in inconsistent ways. The situation for caching servers and Web proxies is even more chaotic; each vendor has implemented its own heuristics for determining when to cache a document, when a cached document is still "fresh" and can be returned from local storage, and when a document has gone "stale" and must be fetched anew from its mother site. • These vendor-specific differences can lead to unexpected behavior. HTTP 1.1 introduces nearly a dozen new headers that fine tune the Web's caching and proxying algorithms. • With a dozen new headers, this will bring some order to the chaos. Well at least a dozen different ways.
Sample HTTP Request Information • HTTP: ----- Hypertext Transfer Protocol ----- • HTTP: Line 1: GET / HTTP/1.1 • HTTP: Line 2: Accept: */* • HTTP: Line 3: Accept-Language: en-us • HTTP: Line 4: Accept-Encoding: gzip, deflate • HTTP: Line 5: User-Agent: Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0; DigExt) • HTTP: Line 6: Host: www.microsoft.com • HTTP: Line 7: Connection: Keep-Alive • HTTP: Line 8: Cookie: • MC1=V=3&LV=200111&HASH=0EB9&GUID=E1FDB90E77B34E3B8856B2153CBE50BF The HTTP version being used. Accept headers can be used to indicate that the request is specifically limited to a small set of desired types, as in the case of a request for an in-line image.
Keep Alive Notes • In order for persistent connections to work properly in HTTP, there needs to be an easy mechanism whereby all parties to the HTTP communication can signal the desire for connection persistence and a willingness to abide by the stricter message requirements of HTTP/1.1. • These features can be implemented with HTTP/1.0, but cannot be used reliably with old proxies and gateways until a new protocol version can be indicated. • Proxies are required to remove or rewrite the Connection header and any of the header fields named by the Connection header. • The presence of the Keep-Alive keyword in a Connection header signals that the sender wishes to maintain a persistent connection. The presence of a Keep-Alive header field defines parameters for the persistence. • So, the client will send • Connection: keep-alive • to indicate that it desires a multiple-request session, and the server responds with • Connection: keep-alive • Keep-Alive: max=20, timeout=10 • to indicate that the session is being kept alive for a maximum of 20 requests and a per-request timeout of 10 seconds. The Connection header with keep-alive keyword must be sent on all requests and responses that wish to continue the persistence. The client sends requests as normal and the server responds as normal, except that all messages containing an entity body must have an accurate content-length (or, if HTTP/1.1 is used by the recipient, a chunked transfer encoding). • The persistent connection ends when either side closes the connection or after the receipt of a response which lacks the Keep-Alive keyword. • The server may close the connection immediately after responding to a request without a Keep-Alive keyword. A client can tell if the connection will close by looking for a Keep-Alive in the response.
Support for Virtual Hosts • To host several "virtual Web sites" on a single Web server under HTTP 1.0, you had to squander an IP address for each site. This is because the Web server has a way of knowing to which virtual host an incoming request is directed. With IP addresses becoming a scarce resource, this is clearly unacceptable. • HTTP 1.1 introduces a required Host header that the browser uses to tell the Web server which virtual host it wants to talk to. This allows you to host hundreds of virtual Web sites on top of a single IP address.
Document Enhancements • Document-Type Negotiation • HTTP 1.0 provides an underutilized mechanism that allows servers to pick and choose among various representations of a document for the type most preferred by the browser. The browser tells the server what MIME types it prefers, and the server picks the best-matching format. HTTP 1.1 extends this by allowing the browser to take an active role in the negotiation. When a browser first connects to a server, it can ask the server to list all available formats for a particular document so that it can pick the one it prefers. • Better Support for Collaborative Publishing • With HTTP 1.0, you create and delete documents on the server using PUT and DELETE, respectively. HTTP 1.1 enhances these methods by providing mechanisms to ensure that existing documents aren't accidentally clobbered when multiple users try to update them simultaneously. An optional PATCH method allows you to upload changes to a list of documents on the server. This method, familiar from the UNIX patch program, is a great way to conserve network bandwidth, particularly when dealing with very large files.
Persistent Connection or Pipelining • In the screen shot below you can see the multiple Gets that would normally require separate tCP port connections.