Download

1 / 45
460 likes | 592 Vues
Tanzeem Choudhury Intel Research / Affiliate Faculty CSE Dieter Fox Henry Kautz CSE James Kitts Sociology. Creating Dynamic Social Network Models from Sensor Data. What are we doing? Why are we doing it? How are we doing it?. Social Network Analysis.

E N D
Tanzeem ChoudhuryIntel Research / Affiliate Faculty CSE Dieter Fox Henry KautzCSE James KittsSociology Creating Dynamic Social Network Models from Sensor Data
What are we doing? • Why are we doing it? • How are we doing it?
Social Network Analysis • Work across the social & physical sciences is increasingly studying the structure of human interaction • 1967 – Stanley Milgram – 6 degrees of separation • 1973 – Mark Granovetter – strength of weak ties • 1977 –International Network for Social Network Analysis • 1992 – Ronald Burt – structural holes: the social structure of competition • 1998 – Watts & Strogatz – small world graphs
Social Networks • Social networks are naturally represented and analyzed as graphs
Example Network Properties • Degree of a node • Eigenvector centrality • global importance of a node • Average clustering coefficient • degree to which graph decomposes into cliques • Structural holes • opportunities for gain by bridging disconnected subgraphs
Applications • Many practical applications • Business – discovering organizational bottlenecks • Health – modeling spread of communicable diseases • Architecture & urban planning – designing spaces that support human interaction • Education – understanding impact of peer group on educational advancement • Much recent theory on finding random graph models that fit empirical data
The Data Problem • Traditionally data comes from manual surveys of people’s recollections • Very hard to gather • Questionable accuracy • Few published data sets • Almost no longitudinal (dynamic) data • 1990’s – social network studies based on electronic communication
Social Network Analysis of Email • Science, 6 Jan 2006
Limits of E-Data • Email data is cheap and accurate, but misses • Face-to-face speech – the vast majority of human interaction, especially complex communication • The physical context of communication – useless for studying the relationship between environment and interaction • Can we gather data on face to face communication automatically?
Research Goal Demonstrate that we can… Model social network dynamics by gathering large amounts of rich face-to-face interaction data automatically using wearable sensors combined with statistical machine learning techniques Find simple and robust measures derived from sensor data that are indicative of people’s roles and relationships that capture theconnections between physical environment and network dynamics
Questions we want to investigate: Changes in social networks over time: How do interaction patterns dynamically relate to structural position in the network? Why do people sharing relationships tend to be similar? Can one predict formation or break-up of communities? Effect of location on social networks What are the spatio-temporal distributions of interactions? How do locations serve as hubs and bridges? Can we predict the popularity of a particular location?
Other Applications of such Data • Research on emotional content of speech • Need for “natural” data • Medical applications • Speaking rate is an indicator of mental activity • Overly-rapid speech symptom of mania • Asperger’s syndrome: abnormal conversational dynamics • Meeting understanding • Interruptions indicate status & dominance
Support • Human and Social Dynamics – one of five new priority areas for NSF • $800K award to UW / Intel / Georgia Tech team • Intel at no-cost • Intel Research donating hardware and internships • Leveraging work on sensors & localization from other NSF & DARPA projects
Procedure • Test group • 32 first-year incoming CSE graduate students • Units worn 5 working days each month • Collect data over one year • Units record • Wi-Fi signal strength, to determine location • Audio features adequate to determine when conversation is occurring • Subjects answer short monthly survey • Selective ground truth on # of interactions • Research interests • All data stored securely • Indexed by code number assigned to each subject
Privacy • UW Human Subjects Division approved procedures after 6 months of review and revisions • Major concern was privacy, addressed by • Procedure for recording audio features without recording conversational content • Procedures for handling data afterwards
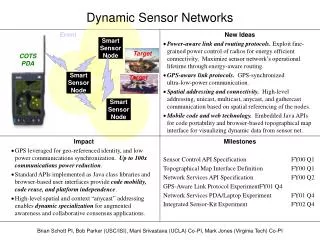
Data Collection Intel Multi-Modal Sensor Board Coded Database codeidentifier audiofeatures Real-time audio feature extraction WiFistrength
Data Collection • Multi-sensor board sends sensor data stream to iPAQ • iPAQ computes audio features and WiFi node identifiers and signal strength • iPAQ writes audio and WiFi features to SD card • Each day, subject uploads data using his or her code number to the coded data base
Speech Detection • From the audio signal, we want to extract features that can be used to determine • Speech segments • Number of different participants (but not identity of participants) • Turn-taking style • Rate of conversation (fast versus slow speech) • But the features must not allow the audio to be reconstructed!
vocal tract filter Speech Production The source-filter Model Fundamental frequency (F0/pitch) and formant frequencies (F1, F2 …) are the most important components for speech synthesis
Speech Production • Voiced sounds: Fundamental frequency (i.e. harmonic structure) and energy in lower frequency component • Un-voiced sounds: No fundamental frequency and energy focused in higher frequencies • Our approach: Detect speech by reliably detecting voiced regions • We do not extract or store any formant information. At least three formants are required to produce intelligible speech* * 1. Donovan, R. (1996). Trainable Speech Synthesis. PhD Thesis. Cambridge University 2. O’Saughnessy, D. (1987). Speech Communication – Human and Machine, Addison-Wesley.
Speech Features Computed • Spectral entropy • Relative spectral entropy • Total energy • Energy below 2kHz (low frequencies) • Autocorrelation peak values and number of peaks • High order MEL frequency cepstral coefficients
Features used: Autocorrelation (a) (b) Autocorrelation of (a) un-voiced frame and (b) voiced frame. Voiced chunks have higher non-initial autocorrelation peak and fewer number of peaks
Spectral entropy: 4.21 Spectral entropy: 3.74 Features used: Spectral Entropy FFT magnitude of (a) un-voiced frame and (b) voiced frame. Voiced chunks have lower entropy than un-voiced chunks, because voiced chunks have more structure
Features used: Energy Energy in voiced chunks is concentrated in the lower frequencies Higher order MEL cepstral coefficients contain pitch (F0) information. The lower order coefficients are NOT stored
Multi-Person Conversation Model Group State Gt Who is holding the floor (main speaker) 1-N: instrumented subjects N+1: silence N+2: any unmiked speaker
Multi-Person Conversation Model Individual State Mit True if subject i is speaking P(M|G) set so as to disfavor people talking simultaneously U true if unmiked subject speaking
Multi-Person Conversation Model Voicing States Vit True if sound from mike i is a human voice P(Vit | Mit) = 1 P(Vit | not Mit) = 0.5 AVt is logical OR of voicing nodes
Multi-Person Conversation Model Observations Oit Acoustic features from mike i that are useful for detecting speech P(O|V) is a 3D Gaussian with covariance matrix, learned from speaker-independent data
Multi-Person Conversation Model Energy Ei,jt 2D variable containing log energies of mikes i and j Associates voiced regions with speaker If i talks at t, then energy of mike i should be higher than mike j
Multi-Person Conversation Model Entropy Het Entropy of the log energy distribution across all N microphones When an unmiked subject speaks, entropy across microphones will be low
Analyzing Results of DBN Inference • Compute # of conversations between subjects • Create weighted graph • Visualize with multi-dimensional scaling
Modeling Influence • Goal: model influence of subject j on subject i’s conversational style • Formally: • P(Si,t | Si,t-1) = self transition probability (probability of continuing to speak or remain silent) • Question: for a particular conversation, how much of P(Si,t | Si,t-1, Sj,t-1) is explained byP(Sj,t | Sj,t-1)? • Create mixed-memory Markov chain model, infer parameters;
GISTS • Inferring what a conversation is about (“gist”) • Apply speech recognition • Use OpenMind commonsense knowledge database to associate words with classes of events (“buying lunch”) • Use simple Naïve Bayes “bag of words” to infer gist and select key words • Improve by conditioning on location
Next Step: Locations • Wi-Fi signal strength can be used to determine the approximate location of each speech event • 5 meter accuracy • Location computation done off-line • Raw locations are converted to nodes in a coarse topological map before further analysis
Topological Location Map • Nodes in map are identified by area types • Hallway • Breakout area • Meeting room • Faculty office • Student office • Detected conversations are associated with their area type
Goal: Social Network Model • Goal: Dynamic Social Network Model • People, Places, Conversations, Time • Nodes • Subjects (wearing sensors, have given consent) • Places (e.g., particular break out area) • Instances of conversations • Edges • Between subjects and conversations • Between places and conversations • Replicate over data collection sessions (as in a DBN) • Compute influences between sessions: E.g., if A-B and B-C are strong a t, then A-C is likely to be strong at t+1