An Epsilon Range Join in a graphics processing unit
130 likes | 288 Vues
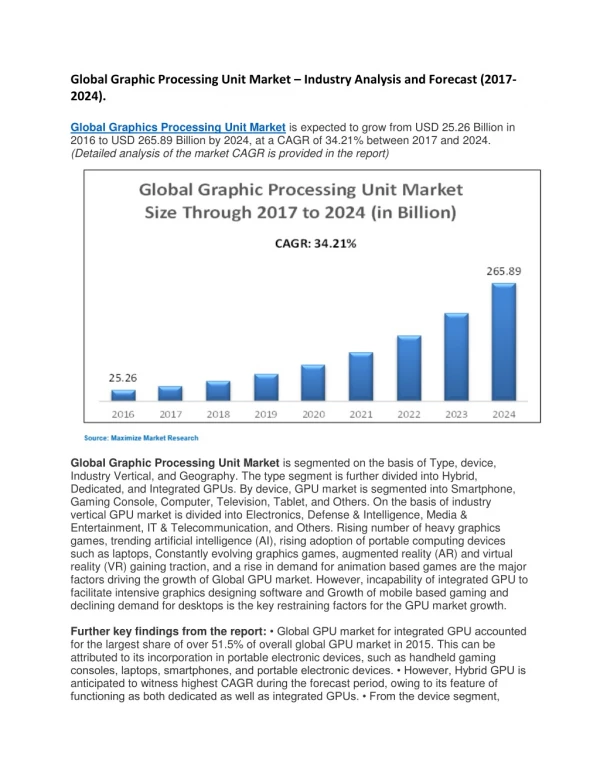
An Epsilon Range Join in a graphics processing unit. Project work of Timo Proescholdt. Motivation. Graphic processing units increasingly more powerfull Can we exploit this immense computing power to accelerate general purpose algorithms? Single instruction, multiple data concept

An Epsilon Range Join in a graphics processing unit
E N D
Presentation Transcript
An Epsilon Range Join in a graphics processing unit Project work of Timo Proescholdt
Motivation • Graphic processing units increasingly more powerfull • Can we exploit this immense computing power to accelerate general purpose algorithms? • Single instruction, multiple data concept • Bot Nvidia and ATI offer languages to write shader programs
Project definition “comparation of two implementations of a epsilon range join. One in plain c++, the other implemented in a shader language”
Epsilon Range Join? i For i in 0..Dataset.size For j in i+1..Dataset.size if Distance(j,i) < Epsilon addResult(i,j) end end end j
Steps undertaken • Plain C++ implementation • Selection of a shader language (brook) • Framework rather than language • CG based • Works with ATI and NVIDIA • Almost plain C programming • Identifying math-intensive and paralllel components and moving them to GPU kernel functions • Only computation intensive tasks in the GPU, controll remains on the CPU
The GPU as workhorse • Most computational intensive task is the calculation of the euclidian distance • N*N/2-N= N(N/2-1) = 208.059.600 invocations (demo datas N is 20400) • Highly parallel and independent from the rest of the results • Implemented a kernel function which calculates the euclidian distance between two given records
How to invoke the kernel function 208.059.600 times? • Call the kernel function with all the necessary data and an iterator, stating the number of invocations • Data is uploaded into the GPU memory • Function executed parallely • iterator argument embraces the number of the actual invocation as its value
Problem: a kernel function can only be invoked a ~4 millon times (and texture memory is limited to 2048x2048 textures) i Solution: • Split the whole data space into chunks(of size 2040) • Kernel funcion joins two of these chunks (2040^2 ~= 4 millon) • CPU controll function invokes kernel function for each chunk pair and assembles the total result from the partial results 2040 j N 2040 N
How to invoke the kernel function 208.059.600 times? • Data1 and Data2 contain the chunks to be joined • Entry point for Data1 is calculated from iterator( iterator / Data1.size ) • Entry point for Data2 is calculated from iterator ( iterator mod Data2.size ) • Calculate distance and write it to result void kernel workhorse( iterator, data1, data2, .. , result)
Results • GPU version of the algorithm outperforms the plain C++ version by the factor 5 • Runtime independent from the result • Hardware: 3,4 Ghz Pentium4, 7800 GX
Further work • Kernel function returns chunksize^2 sized array, independently from the actual size of the result set • Native CG version of the algorihm (brook runtime not performant) • Pack algorithm into a DLL which can be linked against • Make algoirthm work with non 2040 aligned input data
Thanks to.. • Peter Kunath • Prof. Dr. Christian Boehm • And you, for your pacience!