Download
1 / 27
290 likes | 609 Vues
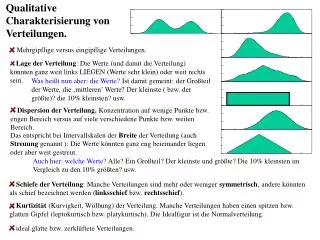
Qualitative Charakterisierung von Verteilungen. Mehrgipflige versus eingipflige Verteilungen. Lage der Verteilung : Die Werte (und damit die Verteilung) könnten ganz weit links LIEGEN (Werte sehr klein) oder weit rechts sein. .

E N D
Qualitative Charakterisierung von Verteilungen. • Mehrgipflige versus eingipflige Verteilungen. • Lage der Verteilung: Die Werte (und damit die Verteilung) könnten ganz weit links LIEGEN (Werte sehr klein) oder weit rechts sein. Was heißt nun aber: die Werte? Ist damit gemeint: der Großteil der Werte, die ‚mittleren’ Werte? Der kleinste ( bzw. der größte)? die 10% kleinsten? usw. • Dispersion der Verteilung. Konzentration auf wenige Punkte bzw. engen Bereich versus auf viele verschiedene Punkte bzw. weiten Bereich. Das entspricht bei Intervallskalen der Breite der Verteilung (auch Streuung genannt ): Die Werte könnten ganz eng beieinander liegen oder aber weit gestreut. Auch hier: welche Werte? Alle? Ein Großteil? Der kleinste und größte? Die 10% kleinsten im Vergleich zu den 10% größten? usw. • Schiefe der Verteilung: Manche Verteilungen sind mehr oder weniger symmetrisch, andere könnten als schief bezeichnet werden (linksschief bzw. rechtsschief). • Kurtizität (Kurvigkeit, Wölbung) der Verteilung. Manche Verteilungen haben einen spitzen bzw. glatten Gipfel (leptokurtisch bzw. platykurtisch). Die Idealfigur ist die Normalverteilung. • ideal glatte bzw. zerklüftete Verteilungen.
Quantitative Charakterisierung, Lage: Min, Max, Mode Sortierte Liste • Index Wert • x(i) • 21 • 21 • 21 • 21 • 21 • 21 • 22 • 22 • 22 • 22 • 23 • 23 • 24 • 24 • 24 • 30 f(x) f(IQ) Für den Modalwert gilt: f(mode(x)) = max (f(x)) x IQ Streifendiagramm, vertikal Anteil Normalverteilung für den IQ 0.8 f(x) 0.6 0.00100 0.4 0.00090 0.4 Dichtefunktion f(x), x=Alter 0.00080 0.3 0.00070 0.2 0.2 0.00060 0 0.00050 0.1 ledig verlobt getrennt 0.00040 0.00030 0 x 18 20 22 24 26 28 30 0.00020 0.00010 0 5000 0 1000 2000 3000 4000 Lagemaßzahl Beispiele: Minimum bzw. Maximum min(x)= x(1), max(x)= x(n). Mit x(1) und x(n) aus der sortierten Liste min(Alter) = 21 = x(1) max(Alter) = 30 = x(16) Modalwert(engl. Mode): mode(x) Der Modalwert ist der x-Wert mit größter Dichte. mode(Alter)= 21. Denn f(x) ist bei 21 am größten mode(Familienstand) = 0 (=ledig). Denn f(x) ist bei ‚ledig‘ am größten: 11/16. mode(IQ) = 100. Denn f(x) ist bei 100 am größten. Problem: Es kann auch mehrere Modalwerte geben (bimodale oder sogar multimodale Verteilungen) Zwei Lösungsstrategien: mode(Einkommen) = Intervall von 0 bis 100. • Modalwertmenge berichten. • Eindeutigkeitsstrategie: bzw. mode(Einkommen) = Intervallmittel = 50 • Bei Intervallen das Intervallmittel berechnen. • Sonst: Modalwert nur für unimodale Verteilungen als sinnvoll.
f(x) Anteilsverteilung x Wert Anteil Index f(x) xi p(xi) i 1 2 3 4 5 21 22 23 24 30 0.375 0.125 + 0.125 0.125 0.1875 0.0625 18 20 22 24 26 28 30 x Diese Idee kann auch auf andere Quantelungen ausgedehnt werden: Einteilung in 3 Teile, 4 Teile usw. 0.4 0.3 0.2 Perzentile heißen die 99 Werte, die eine Quantelung in 100 Teile ermöglichen: 1.Perzentil, 2. Perzentil usw. 0.1 0 Lagemaßzahl Quantitative Charakterisierung, Lage: Median und Co. Median(‚mittlerer Wert‘): med(x) ist der x-Wert, der die Verteilung in zwei Hälften teilt. Der Median med(x) ist hier = 100. Für diskrete Verteilungen präziser: med(x) ist der x-Wert, für den die beiden Forderungen gelten: 1. mindestensdie Hälfte aller Werte ist kleinergleich med(x) 2. mindestensdie Hälfte aller Werte ist größergleich med(x) Der Median med(x) ist hier = 22 Terzilesind die beiden x-Werte, die die Verteilung in drei Drittel teilt: 1. Terzil und 2. Terzil. Quartilesind die 3 x-Werte, die die Verteilung in 4 Viertel teilt: 1. Quartil und 2. Quartil (= Median) und 3. Quartil. Darüber hinaus gibt es: Quintile(5 Teile), Sextile(6 Teile), Septile(7 Teile), Oktile(8 Teile), Dezile(10 Teile) usw. Quantile: Diese ‚-ile‘ können unter dem Begriff Quantil zu bestimmten Quanten (= q) zusammengefasst werden. Beispiel: Das 1. Terzil ist das Quantil zum Quantum1/3. Das 2. Terzil ist das Quantil zum Quantum2/3. Beispiel: Das 1. Quartil ist das Quantil zum Quantum1/4. Das 3. Quartil ist das Quantil zum Quantum3/4.
f(x) f(x) x Sortierte Liste Sortierte Liste Quantile zu Dieser x-Wert heißt Quantilzum Quantum q: q = ¾ • Index Wert • x(i) • 21 • 21 • 21 • 21 • 21 • 21 • 22 • 22 • 22 • 22 • 23 • 23 • 24 • 24 • 24 • 30 • Index Wert • x(i) • 21 • 21 • 21 • 21 • 21 • 21 • 22 • 22 • 22 • 22 • 23 • 23 • 24 • 24 • 24 • 30 18 20 22 24 26 28 30 x Auf Grund der sortierten Liste das Quantil berechnen: Gesucht: . Das Quantum q=1/3, n=16. z:=16*(1/3) = 5.3333. z ist keine ganze Zahl; daher muss [z]+1 berechnet werden: [5.3333]+1 = 6. Das Quantil ist daher das 6. aus der sortierten Liste: x(6) = 21. Für diskrete Verteilungen muss diese Definition präzisiert werden: für gelten die beiden Forderungen: 1. mindestensq aller Werte ist kleiner gleich , 2. mindestens(1-q) aller Werte ist größer gleich . Berechne z:= n*q Problem der Nichteindeutigkeit des Quantils wird nur durch die Konvention der Mittelwertbildung gelöst. Ist z eine ganze Zahl? nein 1.0 Gesucht: . Das Quantum q= ¾, n=16. z:=16*(¾) = 12. z ist eine ganze Zahl. Daher ist das Quantil =: (x(12) + x(13) )/2 = (23+24)/2 = 23.5. ~ 0.9 x = : x ( ) + [ z ] 1 q ja 0.8 x x + 0.7 ( ) ( ) ~ z z +1 : = x 0.4 0.6 q 2 0.5 Verteilungsfunktion für Alter 0.3 Die beiden Forderungen, mit der Verteilungs- und Dichte-funktion formuliert, lauten: q F( ) und F( ) f ( ) q So kann das Quantil auch mit Hilfe der Verteilungsfunktion graphisch bestimmt werden: • Starten von der Ordinate bei q. 0.4 F(x) 0.3 0.2 0.2 q = ¾ 0.1 0.1 0.0 0 q = 0.5 • An der Stelle,wo man auf dieFunktionF(x) stößt, ist auf der x-Achse (Abszisse)das Quantil zum Quantum q ablesbar. 18 20 22 24 26 28 30 x q =1/3 d.h. liegt dort auf der x-Achse, wo F(x) erstmals q überschreitet bzw. erreicht. Bis zu welchem x-Wert liegt ein gegebenes Quantum q (=Anteil) aller Werte? Quantile Bei diskreten Verteilungen [z] Die eckigen Klammern um die Zahl z bedeuten, dass die Dezimalstellen abgeschnitten werden sollen (diese Dezimalstellenabschneideregel heißt auch Floor-Function). Beispiele: [5.13] = 5, [2.4711] = 2, [0.61543] = 0
Quantile bei stetigen Verteilungen Kumulierte Anteilsverteilung q = 0.80 Graphisches Verfahren: • Starten von der Ordinate bei q. Klassen Index i Kum. Anteil F(oi) Klassen Grenzen Für stetige Verteilungen können Quantile einfacher definiert werden als für die diskreten. ist der x-Wert, für den gilt: ui oi q = ½ • An der Stelle,wo man auf dieFunktionF(x) stößt, ist auf der x-Achse (Abszisse)das Quantil zum Quantum q ablesbar. ( ( ) ) o u , , F F u o ) ) ( ( 1 2 3 4 5 0 100 500 1000 2000 100 500 1000 2000 5000 0.10 0.20 0.40 0.70 1.00 m m m m Klassen Breite bi q = ¼ ~ q= F( ) . x ~ ~ q = + Þ = - 100 400 500 1000 3000 q a b x x ( q a ) / b ( x , q ) q q ~ 1 = - + q x ( F ( u ) bu ) 625 1333 b q m m Berechnen für gruppierte Daten In der Anteilsverteilung den Index m finden, für den F(om) erstmalsq überschreitet (F(om) > q) bzw. erreicht (F(om) = q). ~ - o u = + - x u ( q F ( u )) m m q m m - F ( u ) F ( u ) - F ( o ) F ( u ) = m m b m m Gesucht: , daher ist q = 0.80. Index m = 5. Erst hier ist F(o5) > 0.80. u5= 2000. F(u5) = F(2000) = 0.70. Daher ist das Quantil = 2000 + (0.80-0.70)3000/ 0.30 = 3000. - o u Die in Klassen gruppierten Messwerte seien pro Klasse gleichverteilt im Intervall[ui,oi). Zudem sei der kumulierte Anteil in jeder Klasse F(oi) bekannt. Dann kann das Quantil wie folgt berechnet werden. F(x) m m Gesucht: , daher ist q = 0.50. Index m = 4. Erst hier ist F(o4) > 0.50. u4= 1000. F(u4) = F(1000) = 0.40. Daher ist der Median = 1000 + (0.50-0.40)1000/ 0.30 = 1333.3. F(om) = q ~ 1.0 1.0 1.0 x ~ > q q x q 0.9 0.9 0.9 x x x x x x x x x x Gesucht: , daher ist q = 0.25. Index m = 3. Erst hier ist F(o3) > 0.25. u3= 500. F(u3) = F(500) = 0.20. Daher ist das 1. Quartil = 500 + (0.25-0.20)500/ 0.20 = 625. Gesucht: , daher ist q = 0.25. Index m = 3. Erst hier ist F(o3) > 0.25. u3= 500. F(u3) = F(500) = 0.20. Daher ist das 1. Quartil = 500 + (0.25-0.20)500/ 0.20 = 625. ~ ~ ~ ~ ~ ~ ~ ~ ~ ~ 0.7 ¼ ½ .8 ¼ 0.7 ¼ ¼ .8 ½ - 0.8 0.8 0.8 ( q F ( u )) b ~ o u + m m + = u : + x m m 1 m q 0.7 0.7 0.7 - F ( o ) F ( u ) 2 m m ~ Begründung der Formel für das Quantil 0.6 0.6 0.6 : = x F(x) q 0.5 0.5 0.5 Für q muss festgestellt werden, welche Gerade benötigt wird. 0.4 0.4 0.4 Die Geradengleichung allgemein ist: y = a + bx. Die Gerade geht durch die Punkte und . q = 0.3 0.3 0.3 Gesucht: , daher ist q = 0.7. Index m = 4. Hier erreicht F(o4) nun 0.7; F(o4) = 0.7. o4= 2000. u5=2000. Daher ist das Quantil = (2000 + 2000)/2 = 2000. 0.2 0.2 0.2 a und b kann durch Einsetzen der Punkte in die Gleichung berechnet werden. = - bu , a F ( u ) m m 0.1 0.1 0.1 ~ x x x 0.0 0.0 0.0 Nun wird der Punkt in die Gleichung eingesetzt. 1000 1000 1000 2000 2000 2000 3000 3000 3000 4000 4000 4000 5000 5000 5000 0 0 0 q Weiteres Umformen und Einsetzen von a und b liefert die Formel: Jeder Klasse entspricht eine Gerade.
Median, Hinges und Eighths aus der EDA. 5 3 6 4 2 3 5 6 4 1 4 2 4 5 4 5 5 5 5 6 4 5 6 4 5 4 5 4 3 3 4 4 5 1 5 3 2 4 4 5 1 2 3 5 2 1 4 5 4 5 2 3 4 1 3 5 5 1 Berechnungsmethode 23 7 26 25 27 28 29 23 23 18 7 18 28 24 32 27 26 7 18 29 24 25 38 27 29 32 28 28 25 26 24 26 24 26 26 25 26 24 28 24 25 26 25 27 27 25 25 26 25 25 26 24 23 27 27 24 27 25 hu ho Zuerst wird die Tiefe für die Größen berechnet; das ist die Position in der sortierten Liste von vorne bzw. von hinten. Tiefe(Median)=(n+1)/2. Tiefe(Hinges)=([Tiefe(Median)]+1)/2.Tiefe(Eighths)=([Tiefe(Hinges)]+1)/2. Der Median(x) =x(Tiefe(Median)), falls Tiefe(Median) eine ganze Zahl ist, sonst ist der Median das Mittel der beiden Werte, zwischen denen die Dezimalzahl liegt. Mittel der beiden: 25.5 = Median Hinges Entsprechend erfolgt die Berechnung der beiden Hinges (hu, ho) und der beiden Eighths(eu, eo). hu hu ho ho Hinges Hinges Beispiel (9 Werte). Tiefe(Median)=(9+1)/2 = 5. Tiefe(Hinges)=([5]+1)/2 = 3.Tiefe(Eighths)=([3]+1)/2 = 2. Median(x) = 25. hu = 23 (3. von vorne), ho = 27 (3. von hinten), eu = 18 (2. von vorne), eo = 28 (2. von hinten). Beispiel (10 Werte). Tiefe(Median)=(10+1)/2 = 5.5. Tiefe(Hinges)=([5.5]+1)/2 = 3.Tiefe(Eighths)=([3]+1)/2 = 2. Median(x) = (25+26)/2. hu = 23 (3. von vorne), ho = 28 (3. von hinten), eu = 18 (2. von vorne), eo = 29 (2. von hinten). Mittel der beiden: 28.5 Mittel der beiden: 23.5 Beispiel (11 Werte). Tiefe(Median)=(11+1)/2 = 6. Tiefe(Hinges)=([6]+1)/2 = 3.5.Tiefe(Eighths)=([3.5]+1)/2 = (3+1)/2 = 2. Median(x) = 26. hu = 23.5 (Mittel des 3. und 4. von vorne), ho = 28.5 (Mittel des 3. und 4. von hinten), eu = 18 (2. von vorne), eo = 32 (2. von hinten). Beispiel: 9 sortierte Werte 7, 18, 23, 24, 25 ... . Man denke sich die UEen als Perlen, die auf eine Schnur aufgezogen sind. Hält man die Schnur an beiden Enden fest, fällt die Schnur so, dass unten die Medianperle hängt. Der Median ist dann 25. In der EDA (TUKEY, 1977 Exploratory Data Analysis) wurden innovativ ‚anschauliche‘ Begriffe und Konzepte eingeführt, die denen der ‚klassischen‘ Statistik ähnlich sind, aber etwas anders definiert sind. So entsprechen die ‚Hinges‘ (=Falten) fast dem 1. und 3. Quartil, die ‚Eighths‘ fast dem 1. und 7. Oktil, aber nicht bei jedem n. Durch Hochziehen der Medianperle entstehen Falten, bei der 3. Perle (von vorn bzw. hinten): die beiden Werte 23 und 27 sind die Hinges Beispiel: 10 Werte, zusätzlich 32. Hochziehen in der Mitte. Beispiel: 11 Werte, zusätzlich 38. Hochziehen der Medianperle. Der Prozess des Faltens könnte weiter fortgesetzt werden, indem die Hinges selbst hochgezogen werden. Das führt dann zu einer Art Achtelung der Perlenkette. Usw.
Lagemaß Arithmetisches Mittel Für Urliste: Arithmetisches Mittel des Alters (aus Urliste) = (22+24+...+23+21+21) / 16 = 362 / 16 = 22.625. n=16, es wird über 16 Werte gemittelt (ungewichtet). Für Verteilung: Arithmetisches Mittel des Alters (aus Verteilung) mit Anteilen (I=5): = 22.625. Mittel über 5 Werte (mit Anteilen als Gewichten). I I å å = = 1 x p x n x i i i i n = i 1 = i 1 Die Summe der Differenzen zum Mittelwert ist 0: Der Waagebalken habe kein Eigengewicht Beachte: _ X 22.625 ist translationsäquivariant bei linearen Transformationen: y = a + b x. Beispiel(4 x-Werte 0, 1, 2, 3): ist 1.5. Für jeden der n x-Werte werden die y-Werte gebildet: . Den y-Mittelwert erhält man aus mit der gleichen Transformation. = + y a bx i i D. h.: Werden alle einzelnen Werte linear transformiert, gilt dies auch für das arithm. Mittel: Beweis: = + y a b x 25 26 24 27 27 22 29 30 21 23 28 Das arithmetische Mittel (engl. Mean) wird auch als Mittel, Durchschnitt oder Schwerpunkt (engl. Centroid) bezeichnet bzw. etwas unpräzis einfach als der Mittelwert. Die Schwerpunkt-Eigenschaft bedeutet, dass die Summe der Differenzen zum Mittel 0 ist, was auch mit Hilfe einer Dezimalwaage demonstriert werden kann. Bei den Werten des Balken wird pro UE ein Gewicht gehängt. Balance ist beim Mittelwert als Haltepunkt gegeben. Alle Werte werden linear via y = 96 + 100 x (96 ist a, 100 ist b) transformiert: Die y-Werte sind 96, 196, 296, 396. Wie groß ist der Mittelwert? Statt nochmals neu den Mittelwert zu berechnen, kann der Mittelwert ebenfalls nach der Transformation berechnet werden: 96 + 100*1.5 = 246. Beispiel: Währungsumrechnungen sind lineare Transformationen mit a=0. Ist der Mittelwert in einer Währung bekannt, kann er direkt in eine andere Währung umgerechnet werden (ohne Kenntnis der Einzelwerte).
Entscheidungshilfe:Arithmetisches Mittel oder Median 0 0 500 500 1000 1000 Median Median 200 100 100 100 Mittel Mittel 200 Beispiel: Zuerst haben 5 Leute das gleiche Vermögen, dann nimmt einer jedem 100 weg. 120 Beispiel: 2 Einkommenslisten, unterscheiden sich in nur einem Wert 200 300 • Das Mindestskalenniveau für das arithmetische Mittel ist das Intervallskalenniveau, für den Median reicht das Ordinalskalenniveau. • Das arithmetische Mittel reagiert sensibel auf extreme Messwerte (Ausreißer), nicht aber der Median. Ohne Großverdiener: 100, 100, 100, 100, 200 Mit Großverdiener: 100, 100, 100, 100, 1100 Das arithm. Mittel eignet sich nicht als Indikator dafür, wie es den ‚meisten‘ Leuten geht. • Der Median reagiert sensibler auf interne Veränderungen als das arithmetische Mittel. Vor Putsch: 200, 200, 200, 200, 200 Nach Putsch: 100, 100, 100, 100, 600 Das arithm. Mittel bemerkt den ‚Putsch‘ nicht, der Median schon.
Arithmetisches Mittel (stetige Verteilung) Anteilsverteilung Klassen Index i Anteil pi Klassen Grenzen Berechnen der Klassenmitten: ui oi Produkt pi xi Klassen Mittexi 1 2 3 4 5 0 100 500 1000 2000 100 500 1000 2000 5000 0.10 0.10 0.20 0.30 0.30 Für Verteilung: I I 5 30 150 450 1050 50 300 750 1500 3500 å å = = 1 x p x n x i i i i n 1685 = = = Arithmetisches Mittel des Einkommens = i 1 i 1 x Allgemeiner Fall Der Mittelwert ist im stetigen Fall das Integral des Produktes der x-Werte mit der Dichtefunktion. ArithmetischesMittel: f(x) f(x) ist die Dichtefunktion der Verteilung für x f(x) Erläuterung x x Für eine Einteilung des Bereichs von a bis b in mehrere gleich breite (= x) Intervalle seien jeweils die Klassenmitten die x-Werte aus dem Bereich . Das arithmetische Mittel kann dann nach der üblichen Formel berechnet werden: Einteilung kann feiner gemacht werden, bis x mickrig klein ist: dx f(x) x Mittel = x x x x x Beispiel: Gleichverteilung f(x) = 1/(b-a), in x (a,b). Das unbestimmte Integral ist b hier , das bestimmte . ò 2 2 = - = 1 1 1 1 + x dx ( b a ) ( b a ) - - b a b a 2 2 a Der Mittelwert der Gleichverteilung ist daher die Mitte des Definitions-Intervalls. Spezialfall: Berechnen für gruppierte Daten Für gruppierte Daten kann die übliche Formel für den Mittelwert verwendet werden mit den Klassenmitten als x-Werten. Beispiel: Normalverteilung. Das Integral für das arithmetische Mittel ist immer der Symmetriepunkt. Im vorliegenden Fall also: 100.
Andere Mittelwerte: q-getrimmtes und q-winsorisiertes Mittel Sortierte Liste Für sortierte Liste: q-getrimmtes Mittel. • Index Wert • x(i) • 21 • 21 • 21 • 21 • 21 • 21 • 22 • 22 • 22 • 22 • 23 • 23 • 24 • 24 • 24 • 30 Beispiel:q-getrimmtes Mittel des Alters für q=0.10. Bei n=16 ist z=1.6. • Berechne z:= n*q. Beim getrimmten Mittel wird ein Quantum q der kleinsten Werte bzw. größten Werte eliminiert. [z]= 1 (Dezimalstellen abgeschnitten). • Wähle die Werte zwischen dem [z]. und dem (n-[z]+1). aus: x([z]+1) ,..., x(n-[z]) Daher sollen die alle Werte zwischen dem [z]. d.h. dem 1. und dem n-[z]+1. d.h. dem 16-1+1. = 16. Die Werte zwischen dem 1. und 16. sind die Werte vom 2. bis zum 15. Der Mittelwert über die verbleibenden Werte ist das q-getrimmte Mittel = 22.214 • Berechne den Mittelwert der ausgewählten Werte q-winsorisiertes Mittel. Für sortierte Liste: Beispiel:q-winsorisiertes Mittel des Alters für q=0.10. Bei n=16 ist z=1.6. • Wie oben z:= n*q. Bei diesem Mittel wird ein Quantum q der kleinsten Werte bzw. größten Werte durch weniger extreme ersetzt. [z]= 1 (Dezimalstellen abgeschnitten). • Ersetze den 1. bis zum [z]. durch den [z]+1. Wert. Der 1. bis 1. Wert soll durch den 2. ersetzt werden. • Ersetze den (n-[z]+1). bis zum n. durch den (n-[z]). Die Werte vom 16. bis zum 16. Sollen durch den 15. ersetzt werden. Der Mittelwert über die modifizierten Werte ist das q-winsorisierte Mittel = 22.25. • Berechne den Mittelwert dieser modifizierten Werte Diese Mittelwertbildungen solldie Anfälligkeit des arithmetischen Mittels für Ausreißerabschwächen. q ist der Anteil der fraglichen Ausreißer im oberen bzw. unteren Bereich und muss vorgängig festgelegt werden. 21 Das arithm. Mittel der restlichen Werte heißt das q-getrimmte Mittel. 24 Das arithm. Mittel der so modifizierten Werte ist das q-winsorisierte Mittel.
Quantitative Charakterisierung, Streuung EDA Beispiel Spannweite(engl.range) :=Maximum-Minimum. sp(x) := Max(x) –Min(x) sp(Alter) = 30-21 = 9. f(x) 18 20 22 24 26 28 30 x Sehr ‚sensibel‘ für einzelne Extremwerte. Für manche Verteilungen unbrauchbar! Quantilabstand Differenz zwischen symmetrischen Quantilen ~ ~ Für Alter: = 23.5 - 21= 2.5. h h x d x = - : ~ ~ ~ ~ 35 40 : : = = - - x x x x 21 23.5 - q q q d d 1 0.25 0.25 0.75 0.75 0.25 0.25 ~ für ein gegebenes Quantum q x EDA-Beispiel = 29-23 = 6. 0.75 h h e e H-Spread (Hingedifferenz) dh:= ho– hu EDA-Beispiel: hu=23.5. ho=28.5. eu= 18. eo= 32. 30 25 E-Spread (Eighthsdifferenz) de := eo– eu ~ ~ ~ ~ ~ 0.4 x x x x x 0.25 0.25 0.25 0.75 0.75 0.3 20 15 0.2 0.1 0 10 5 82.7 117.3 110.1 89.9 e e h h e e Streuungsmessung mit Hilfe derDifferenz zweier markanter Lagemaßzahlen Streuungsmaßzahl Beispiele: Für q = 0.25 ist d. 0.25 der Quartilabstand; für q = 0.10 ist d. 0.10 der Dezilabstand. Der halbe Quantilabstand heißt mittlerer Quantilabstand. dh=5, de =14 Alter
Quantitative Charakterisierung, Streuung Urliste: Verteilung: f(x) = + + + + = 6 3 4 2 1 1 0 1 2 8 1.375 16 16 16 16 16 Urliste: Median-Abweichung vom Median := Median der Distanzen aller Werte zum Median. ~ ~ x x ½ ½ ~ = : - MAD Median (| x x |) • Erstellen einer sortierten Listeder Abweichungen vom Median: i 0 . 5 = i 1, , n L 0.4 • Erstellen einer sortierten Liste der Abweichungen vom Median. D.h. 0, 0, 0, 0 4 Werte aus x=22. 0.3 1, 1, 1, 1, 1, 1, 4 Werte aus x=21, 2 Werte aus x=23 3 Werte aus x=24. 2, 2, 2, aus x=30. 8. engl.Median of Absolute Deviations = MAD. 0.2 0.1 18 20 22 24 26 28 30 x 0 Streuungsmessung mit Hilfe derAbweichungen aller Werte zu einer Lagemaßzahl Median Streuungsmaßzahl Beispiele: Mittlere Abweichung vom Median := arithmetisches Mittel der Distanzen aller Werte zum Median. Bei der Erstellung der sortierten Liste der Abweichungen vom Median ist die Verteilung hilfreich, weil da schon gleiche Werte zusammengefasst sind. • Für diese sortierte Liste den Median bestimmen. • Für die sortierte Liste den Median bestimmen: Der Median bei n=16 ist der Mittelwert des 8. und 9. Werts in der sortierten Liste: (1+1)/2 = 1=MAD.
Varianz: für Urliste: Varianz Quadratsummen für Verteilung: x f(x) =22.625 _ = 77.75 Andere Bezeichnungen der VarianzVar(x) Für die Stichprobe: 0.4 oder (um an das Merkmal zu erinnern) oder (falls durch n dividiert wird) oder (falls durch n-1 dividiert wird). Für die Population: oder (um an das Merkmal zu erinnern). 0.3 Wann und wozu durch n-1 dividieren? 0.2 • Wann: Nur in Stichproben, wenn das arithmetische Mittel auch auf Grund der Stichprobe berechnet wurde. In allen übrigen Fällen wird durch n dividiert. 0.1 18 20 22 24 26 28 30 x 0 Bei Division durch n bzw. in diskreten Populationsverteilungen kann die Varianz für die Verteilung etwas einfacher formuliert werden. Bei Division durch n. für Verteilung: Quantitative Charakterisierung, Streuung Streuungsmessung mit Hilfe derAbweichungen aller Werte zum Lagemaß Arithm. Mittel Var(x)=arithmetisches Mittel der quadrierten Distanzen aller Werte zum arithmetischen Mittel der Werte. Standardabweichung: Std(x) :=Wurzel aus der Varianz Für n* = n-1: Var(x) = 77.75 / 15 5.18 Für n* = n : Var(x) = 77.75 / 16 4.86 • Wozu: Die Division durch n-1 in Stichproben wird durchgeführt, wenn die Varianz der Population durch die Varianz in der Stichprobe ‚erwartungstreu‘ geschätzt werden soll.
Formeln zur Varianz 4-Väter-Beispiel: 4 x-Werte Alter: 42, 44, 46, 52 Sei y= -21+ 0.5*x. a= -21. b= 0.5. y 2 ( y ) - i Varianz einer Linearkombination 0 1 5 2 4 1 9 0 Var(a+bx)= b2*Var(x) x 2 ( x ) - i 42 44 52 46 16 4 36 0 -21 + ½ x • ¼ • (½)2 Var(x) = 56 / 3 Var(y) = 14 / 3 Verschiebungssatz. Beispiel: Alter, 16 Studenten. Mittelwert = 22.625. Berechne zuerst Summe der quadrierten Werte: Verschiebungssatz für sqx zur einfacheren Berechnung der Quadratsummen bei ‚krummen‘ Mittelwerten: Danach 16*quadrierter Mw. berechnen Differenz: sqx = 8268 – 8190.25 =77.75 , wie vorher! (Geschätzter) Standardfehler des arithmetischen Mittels Standardfehler des Altersmittelswerts bei einer Stichprobengröße von n=16 Std( ) = Std(x) / = Std(x) / 4. Standardfehler des arithmetischen Die Standardabweichung des arithm. Mittels ist kleiner als die der Werte selbst, und zwar um den Faktor . Mittels Varianz einer Linearkombination. Alle x-Werte werden mit der Linearkombination y = a + bx. transformiert. Wie groß ist die Varianz der transformierten Werte? • Dehnung (um b) wirkt sich quadratisch im quadratischen Konzept der Varianz aus. • ‚Breite‘ bleibt gleich bei Verschiebung um a. Zuerst Summe der quadrierten Werte bilden. Erst danach den Mittelwert (quadriert und mit n multipliziert) subtrahieren. Der Standardfehler ist die Standardabweichung der Verteilung aller denkbaren Mittelwerte, die man erhielte, wenn man etwa sehr viele Stichproben ziehen würde (jeweils mit gleichem n). Etwas exakter spricht man vom geschätztem Standardfehler, wenn die Std(x) selbst auf Grund der Stichprobe geschätzt wird.
Geometrische Interpretation der Varianz Varianz als mittlere Fläche y 2 - ( y ) - y i i 3² 0 1 5 2 -2 -1 3 0 4 1 9 0 0 1 2 3 n sq å 2 y = - Var(y) : sq : ( y ) y = -2² y i - n 1 3 = i 1 -1² _ 14 y -2 -1 0 1 2 3 Std(y) = 2.1 Var(y) = 14/ 3 = 4.66. 0 1 2 3 4 5 3 -3 14/3 = Var(y) 3 d -3 Im ‚Einheiten-Raum‘ y1 Der Einfachheit wegen werden die 3 Koordinaten mit a, b und c bezeichnet. - y y Pro UE wird eine Achse verwendet. Bei n UEen ist daher ein n-dimensionaler Raum nötig. a y2 -3 b Für jeden Wert, der genau dem Mittel entspricht, kann die Dimension um 1 reduziert werden. _ _ _ - y - y - y 3 y3 c Der Nullpunkt stellt den Mittelwert dar. Auf jeder Achse werden als Werte die Differenzen zum Mittelwert eingetragen. e • Zuerst noch eine Hilfsebene einfügen. -2 • Mit dem braunen Dreieck kann d auf Grund von a und c berechnet werden: d2 = a2 + c2. -1 • Mit dem lila Dreieck kann e auf Grund von d und b berechnet werden: e2 = d2 + b2. Der quadrierteAbstand vom Nullpunkt zum Datenpunkt ist genau die Summe der quadrierten Abweichungen vom Mittelwert = Var(y) * (n-1) Das Ergebnis ist einDatenpunkt für die gesamte Stichprobe. 4-Väter-Beispiel: y-Werte 0, 1, 2, 5 Im ‚Variablen-Raum‘ Die Werte werden zentriert (d.h. arithmetisches Mittel wird subtrahiert) und auf dem Zahlenstrahl abgetragen. Die Abweichungen vom Mittelwert werden quadriert und können als Flächen-Quadrate dargestellt werden. Berechnung der Distanz: wiederholte Anwendung des Pythagoras-Satzes: Nun ist e schon die gesuchte Distanz, quadriert: e2 = d2 + b2 = a2 + c2 + b2.
Schiefe der Verteilung symmetrisch rechtsschief linksschief Beispiele für unterschiedliche Verteilungen: Schiefemaß xi ni xi ni xi ni 0 1 2 1 3 6 0 1 2 2 6 2 0 1 2 6 3 1 Anteil linksschief symmetrisch rechtsschief 0. 6 0. 5 0. 4 0. 3 0. 2 0. 1 0 * * * * * * - schiefe(x) = -0.71 schiefe(x) =0 schiefe(x) = 0.71 arithm. Mittel Median 0 0 0 1 1 1 2 2 2 Schiefemaß:schiefe(X) Bei linksschiefen Verteilungen ist das arithmetische Mittel links(kleiner) vom Median. Daher ist dann die Differenz arithmetisches Mittel minus Mediannegativ. Bei symmetrischer Verteilung ist diese Differenz 0 und bei rechtsschiefer Verteilung positiv. Die Division durch die Standardabweichung normiert den Schiefekoeffizient (siehe MOOD et al. 1974, S. 76)
Box-Plot (bzw. Box-and-Whisker Plot) Nun kann das Feld durch Zäune (engl. Fences)abgesteckt werden. Oberer äußerer Zaun Alter Box-Plot h-Spread *1.5 • Der obere innere Zaunliegt 1.5* h-Spread über dem oberen Hinge. Deruntere innere Zaunliegt 1.5* h-Spread unter dem unteren Hinge. Oberer innerer Zaun 35 40 h-Spread *1.5 Oberer Hinge ho Extremwerte-Markierung (Outlier, Ausreißer) 30 25 • Jeder Wert außerhalb der äußeren Zäunewird durch einen fetten Punkt markiert. Median Unterer Hinge hu h-Spread *1.5 15 20 Festlegung der (=Schnurrbart). Whiskers Unterer innerer Zaun Das sind die Linien (nach oben bzw. unten) bis zum extremsten Wert, der noch innerhalb des inneren Zauns liegt. h-Spread *1.5 5 10 Unterer äußerer Zaun Ad-Hoc-Beispiel mit n=11. Alters-Werte sortiert: 7, 18, 23, 24, 24.5, 25, 27, 28, 29, 32, 38. Median = 25. hu= 23.5; ho=28.5; h-Spread= ho- hu=5. Median als Querstrich eintragen. Hinges ebenfalls eintragen. Äußere Zäune= 8.5 bis 43.5 Bereiche: Innere Zäune = 16 bis 36. Hinges mit einer Box (daher Box-Plot)verbinden • Der obere äußere Zaunliegt 3* h-Spread über dem oberen Hinge. Deruntere äußere Zaunliegt 3* h-Spread unter dem unteren Hinge. Whisker h-Spread • Jeder Wert zwischen dem innere Zaunund äußerem Zaunwird durch einen Stern markiert. Whisker Die Zäune gehören nicht zum Boxplot.
Streuungsmaße für qualitative Merkmale Familienstand Alle bisher behandelten Streuungsmaße bauen auf der Breite der Verteilung auf. Das setzt für das Merkmal Intervallskalenniveau voraus. Anteil Anteil 0.60 0.60 0.40 0.40 Für ein qualitatives Merkmal kann untersucht werden, inwiefern die Anteilsmasse auf eine einzige Ausprägung bzw. einige wenige Ausprägungen konzentriert ist (geringe Streuung), oder auf mehrere Ausprägungen eher gleichmäßig verteilt ist (große Streuung). 0.20 0.20 0 0 ledig ledig verlobt verlobt getrennt getrennt Anteilsmasse konzentriert sich stark auf die Ausprägung‚ledig‘. Anteilsmasse ist eher gleichmäßig auf die Ausprägungen aufgeteilt. (geringe Streuung) (große Streuung) Modaldispersion Modaldispersion: md Der Anteil der Werte, die nicht in der Modal-Ausprägung liegen. Die Anteile sind md = = 0.625 Der größte Anteil ist Qualitative Varianz Qualitative Varianz: qv Daher md = = 0.3125 Familienstand Hier werden alle Anteile (quadratisch) berücksichtigt. qv = qv = = = 0.664 = = 0.461 Entropie(in bits) Entropie: h (bzw. mittlere Entropie) Potentiell minimale mittlere Länge von Informationen in Bits (bzw. Nits), wenn alle Teilinformationen (Ausprägungen des Merkmals) optimal codiert werden. h(x) = h(x) = 1.095 nits 0.777 nits Entropie(in nits) h(x)b =h(x) / ln(2)= 1.4427 h(x) 1.12 h(x)b = 1.4427 h(x) 1.58 Zur Entwicklung optimaler Codes im Sinne der Informationstheorie, später!
Überlegungen zur Entwicklung optimaler Binär-Codes 1 2 3 4 5 6 7 8 A B C D E F G H Die Entwicklung optimaler Binärcodes entspricht dem Finden einer optimalen Fragestrategie bei Unsicherheit, wobei jede Antwort nur binär (etwa: nein/ja; bzw. 0/1) sein darf. Beispiel: Anne und Bert spielen ‚Felderraten‘ auf dem PC. Der PC wählt zufällig (jedes Feldmit gleicher Chance) ein bestimmtes Feld auf einem Schachbrett. Anne soll erraten, welches Feld ausgewählt ist. Der PC antwortet auf Annes Fragen jeweils mit nein bzw. ja oder 0 bzw. 1. Bert macht das auch. Beide wiederholen das Spiel öfters. Gewinner ist, wer pro Spiel am wenigsten Fragen braucht. Welches ist hier die optimale Fragestrategie? z.B. für Suche von C8 1. Feld oberhalb der Mitte? 1. 2. Feld links der Mitte? 0. 3. Liegt es in Zeile A bzw. B? 0. 4. In Spalte 5 bzw. 6? 0. 5. In der Zeile C? 1. 6. Ist es in Spalte 7? 0. Antwortfolge: 100010. Daher muss es Feld C8 sein. * Bei I Ausprägungen sind ld(I) Fragen bei optimaler Fragestrategie erforderlich, wenn die Chancen aller Ausprägungen gleich sind. Es gilt auch: ld(I) = -ld(1/I) Wie viele Fragen dieser Art sind nötig?6. Mit 6 Fragen kann jedes der 64 Felder eindeutig identifiziert werden. Die 64 Felder entsprechen den Ausprägungen. Jede Frage kann 2 mögliche Antworten haben. Daher insgesamt 26= 64 mögliche Antwortsequenzen. Der Logarithmus von 64 zur Basis 2 löst die Aufgabe: 2 hoch x = 64. D.h. x = ld(64) = 6. Umgeformt: 6 = - ld(1/64). Bei ungleichen Anteilen sind andere Fragestrategien besser. z.B. Falls der PC fast immer das Feld C8 wählt, ist es wohl optimaler, zuerst zu fragen: Ist es Feld C8? Die optimale Strategie wird auf Grund der Anteile entwickelt. Nach Ausprägungen mit großem Anteil wird zuerst gefragt.
Überlegungen zur Entwicklung optimaler Binär-Codes, Forts. Erwartete Fragelänge(in bits) å I Fragenanzahl p i i = i 1 Fragestrategie in Form eines Flussdiagramms Durchschnittlich benötigte Anzahl ‚optimaler‘ 0 0 0 A? B? C? D 1 1 1 C A B Entropie(in bits) Fragen = å I = - h ( x ) : p ld ( p ) b i i = i 1 Die optimale Strategie wird auf Grund der Anteile entwickelt. Zuerst nach Ausprägungen mit dem größten Anteil fragen; danach die seltenen Fälle abklappern! 4-Buchstaben-Beispiel: Buchstaben A, B, C, D erraten. Anne weiß aus Erfahrung, dass der PC A in½, B in ¼, C in 1/8 und D in 1/8 der Fälle auswählt. Welche optimale Fragestrategie soll sie wählen? Vorschlag: Zuerst nach A fragen., weil der Anteil mit ½ am größten ist (Die Chance, nach der ersten Frage fertig zu sein ist groß). Falls nein nach B fragen (wegen ¼ Chance). Falls nein, nach C fragen. Optimal? Das Spiel werde nun sehr oft wiederholt. Mit Hilfe der Anteile als Gewichte kann nun die durchschnittlichbenötigte Fragenlänge berechnet werden : ½ mal 1, ¼mal 2, 1/8 mal 31/8 mal 3. Als gewichtetes arithmetische Mittel: ½* 1 +¼ * 2 + 1/8* 3 + 1/8*3= 14 / 8 Bei passenden Anteilen gilt:Fragenanzahl = ld(1/pi) = -ld(pi ) Das gewichtete arithmetische Mittel: ½ * 1 + ¼* 2 + 1/8 * 3 + 1/8 * 3. kann dann so ausgedrückt werden: - (½ * ld(½) + ¼ *ld(¼) + 1/8 *ld(1/8) + 1/8 *ld(1/8)) Übersetzen des Fragespiels in die Übermittlung von Nachrichten. Das Übertragen von Nachrichten ist kein kompetitives, sondern ein kooperatives ‚Spiel‘. Der Binärcode für alle Ausprägungen eines Merkmals (ein Alphabet, die Bezeichnung der 64 Schachfelder, die 4 Ausprägungen A B C D) optimal aufgebaut werden, damit zur Übertragung von Nachrichten (mit dem betrachteten Alphabet) möglichst wenig binäre Zeichen notwendig sind. Eine Antwortsequenz entspricht einem Binärcode, die Länge des Binärcodes (gemessen in bit) der Fragenanzahl. Die Antwortsequenz für eine einzelne Ausprägung entspricht dem Binärcode der Ausprägung (z.B. 100010 für C8 innerhalb des Schachalphabets, im 4-Buchstaben-Beispiel 1 für A , 01 für B, 001 für C und 000 für D). Übertragen vieler gleicher Ausprägungen in einer Nachricht als Packet. Wenn in Nachrichten oft mehrere gleiche Ausprägungen hintereinander übertragen werden müssen, kann ein Wiederholungsmodus (eine zahlenmäßige Information derart, dass z.B.100 gleiche Zeichen folgen usw.) eingebaut werden. So kann die (potentiell minimale) durchschnittliche Informationslänge auch kleiner als 1 Bit werden.
Rest Anteilsverteilung Klassen Index i Anteil pi Klassen Grenzen ui oi Sortierte Liste 1 2 3 4 5 0 100 500 1000 2000 100 500 1000 2000 5000 0.10 0.10 0.20 0.30 0.30 Klassen Mitte xi • Index Wert • x(i) • 21 • 21 • 21 • 21 • 21 • 21 • 22 • 22 • 22 • 22 • 23 • 23 • 24 • 24 • 24 • 30 .0010 .0009 .0008 100 400 500 1000 3000 .0007 .0006 .0005 .0004 f(x) .0003 .0002 .0001 0 1.0 0.9 0.8 0.7 0.6 F(x) 0.5 0.4 0.3 0 1000 2000 3000 4000 0.2 5000 0.1 x 0.0 1000 2000 3000 4000 5000 0
.0010 .0010 .0009 .0009 .0008 .0008 .0007 .0007 .0006 .0006 .0005 .0005 .0004 .0004 f(x) .0003 .0003 .0002 .0002 .0001 .0001 0 0 ~ x Das Verhältnis der Flächen ist gleich dem Verhältnis der Längen: q / s = p f(x) / m Daher: . s = q 0 0 1000 1000 2000 2000 3000 3000 4000 4000 5000 5000 q m / p m m ) F ( u m b b m m u m s
( ( ) ) u o , , F F u o ) ) ( ( m m m m .0010 .0009 .0008 ~ ~ = + Þ = - q a b x x ( q a ) / b ( x , q ) .0007 q q ~ 1 .0006 = - + q x ( F ( u ) bu ) b q m m .0005 ~ - .0004 o u = + - x u ( q F ( u )) m m .0003 q m m - F ( u ) F ( u ) - F ( o ) F ( u ) f(x) = m m b m m .0002 - o u F(x) m m .0001 0 1.0 1.0 ~ x q 0.9 0.9 x x Gesucht: , daher ist q = 0.25. Index m = 3. Erst hier ist F(o3) > 0.25. u3= 500. F(u3) = F(500) = 0.20. Daher ist das 1. Quartil = 500 + (0.25-0.20)500/ 0.20 = 625. ~ ~ ¼ ¼ 0.8 0.8 ~ ~ x x 0.25 0.75 0.7 0.7 Begründung der Formel für das Quantil 0.6 0.6 0.5 0.5 Für q muss festgestellt werden, welche Gerade benötigt wird. 0.4 0.4 Die Geradengleichung allgemein ist: y = a + bx. Die Gerade geht durch die Punkte und . q = 0.3 0.3 0 1000 2000 3000 4000 0.2 0.2 5000 a und b kann durch Einsetzen der Punkte in die Gleichung berechnet werden. = - bu , a F ( u ) m m 0.1 0.1 ~ x x 0.0 0.0 Nun wird der Punkt in die Gleichung eingesetzt. 1000 1000 2000 2000 3000 3000 4000 4000 5000 5000 0 0 q 625 2500 Weiteres Umformen und Einsetzen von a und b liefert die Formel: 3750 200 e e Jeder Klasse entspricht eine Gerade.
n sq å 2 y = - Var(y) : sq : ( y ) y = y i - n 1 3 = i 1 3 -3 3 3 -3 -2 -3 -1 Varianz -1 Quadratsummen für Verteilung:
1 2 3 4 5 6 7 8 A B C D E F G H Der Einfachheit wegen werden die 3 Koordinaten mit a, b und c bezeichnet. a b c • Zuerst noch Hilfsebene einfügen Berechnung der Distanz: wiederholte Anwendung des Pythagoras Satzes. Berechnung der Distanz: wiederholte Anwendung des Pythagoras Satzes.
Andere Mittelwerte, Geometrisches Mittel Für Urliste: Der Wachstumsfaktor des Gewinnsist hier das Verhältnis des jeweiligen Gewinns zum Vorjahresgewinn. Auf beiden Seiten Logarithmieren liefert: Das ergibt 3 Wachstumsfaktoren: x1=400/200=2, x2 =0.75, x3 =1. 1.14 (etwas anders formuliert: das ist ein durchschnittliches Wachstum von14 %). Aus dem Logarithmus einer Zahl kann mit Hilfe des Potenzierens der Basis die Zahl selbst berechnet werden: Die Formel gilt für jede Art von Logarithmus, hier wird der zur Basis e verwendet (natürlicher Logarithmus): 1.14 Das geometrische Mittel ist die n-te Wurzel aus dem Produkt aller Werte. Beispiel (Eine Firma habe seit 4 Jahren des Bestehens folgende Gewinne: 200, 400, 300, 300). An die Stelle des Addierens tritt das Multiplizieren. Statt durch n zu divi-dieren, wird die n-te Wurzel gezogen. Das arithmetische Mittel der logarithmierten Werte ist der Logarithmus des geometrischen Mittels. Bei Wachstumsfaktoren liefert das geometrische Mittel die adäquate Berechnung des Endwerts aus dem Anfangswert. Wendet man den durchschnittlichen Wachstumsfaktor pro Jahr seit Beginn an: 200*1.14*1.14*1.14 =300. Der tatsächliche Gewinn am Ende kann damit vom Anfang her mit Hilfe des durchschnittlichen Wachstums berechnet werden. Das arithm. Mittel der Wachstumsfaktoren = 1.25 (=25% Wachstum; etwas größer). Wendet man dies als durchschnittliches Wachstum über die Jahre an wie vorher, erhält man: 200*1.25*1.25*1.25 =390.625 (Wohl etwas zu optimistisch). Voraussetzungen und Eigenschaftendes geometrischen Mittels • Das Merkmal muss mindestens Verhältnisskalenniveau haben. Die Werte sollten positiv sein. • Generell ist das geometrische Mittel ist kleiner (bzw. gleich) als das arithmetische. • Wenn über Wachstumsfaktoren gemittelt wird, sollte statt des arithmetischen auf jeden Fall das geometrischeMittel verwendet werden.
Verteilungscharakterisierung durch Funktionen der Anteile Logit. Der Logit ist der natürliche Logarithmus der Odds. Logits Die Verhältnisse werden logarithmiert; so werden die ‚multiplikativen‘ Verhältnisangaben ‚additiv‘. Logitj(pi ) := ln( pi/pj) = ln(pi)-ln(pj). mit j als Index für die Referenzausprägung Odds oddsj(pi ) := pi : pj = pi/pj mit j als Index für die Referenzausprägung Verhältnisangaben (engl.Odds), beim Wetten als Angabe zur Charakterisierung der Chancen Beispiel: Bei Sex unter den ersten 16 ist der ‚männlich‘-Anteil =14/16, der ‚weiblich‘-Anteil=2/16. Als Verhältnis 14 : 2 bzw. 7:1 mit ‚weiblich‘ als Referenzkategorie. bzw. (1/7) : 1 mit ‚männlich‘ als Referenzkategorie bzw. 0.1428 : 1 Als Darstellung interessiert das Verhältnis der Anteile (Häufigkeiten) zueinander bzw. zu einer ‚Referenz‘-Ausprägung. Beispiel: Nach MENDEL sollten 4 Erbsensorten bei einem Kreuzungsexperiment im Verhältnis 9 : 3 : 3 : 1 stehen (Angaben als Odds). Die Häufigkeiten beim MENDEL’schen Experiment waren: 315, 108, 101, 32. Mit der 4. Ausprägung als Referenz-kategorie lauten die realisierten Odds: 9.8 : 3.375 : 3.156 : 1 Beispiel: Logit für den ‚männlich‘-Anteil logit(14/16) =ln(7) = 1.96. Der Logit für den ‚weiblich‘- Anteil logit(14/16)=ln(1/7) = -1.96. Durch das Logarithmieren erhält man bei zwei Ausprägungen den gleichen Wert (einmal positiv, einmal negativ). Die Wahl der Referenzausprägung ist dadurch nicht mehr so wichtig. Bei den Odds versucht man, die Referenzausprägung so zu wählen, dass möglichst als Verhältnis Werte größer als 1 resultieren (bei Odds für Teilgruppen schwer realisierbar).





















