Download

1 / 18
200 likes | 391 Vues
On the bias of Breadth First Search (BFS) and of other graph sampling techniques. Maciej Kurant (EPFL / UCI) Joint work with: Athina Markopoulou (UCI), Patrick Thiran (EPFL). 08 Sep 2010, ITC’22, Amsterdam, Netherlands. E. B. I. D. H. K. A. F. J. C. G.

E N D
On the bias of Breadth First Search (BFS)and of other graph sampling techniques Maciej Kurant (EPFL / UCI) Joint work with: Athina Markopoulou (UCI), Patrick Thiran (EPFL). 08 Sep 2010, ITC’22, Amsterdam, Netherlands
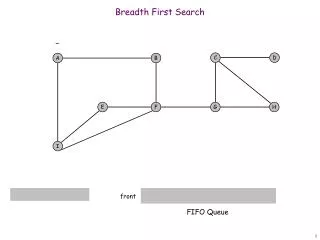
E B I D H K A F J C G Not feasible for huge online graphs! E.g., a full BFS of the friendship graph of would require 200TB of html traffic. Breadth First Search (BFS) D B A C F E I H G K J
E B I D H K A F J C G sampling budget BFS sample of a large graph D B A C F E I H G K J
Why sample with BFS? • BFS is a well known textbook technique • BFS sample is a nice looking graph • E.g.., BFS of a lattice is a lattice • We can study its topological characteristics, which is not possible with random walks • It is used in practice: • Y. Ahn, S. Han, H. Kwak, S. Moon, and H. Jeong, “Analysis of Topological Characteristics of Huge Online Social Networking Services,” in Proc. of WWW, 2007. • A. Mislove, M. Marcon, K. P. Gummadi, P. Druschel, and S. Bhattacharjee, “Measurement and Analysis of Online Social Networks,” in Proc. of IMC, 2007. • C. Wilson, B. Boe, A. Sala, K. P. Puttaswamy, and B. Y. Zhao, “User interactions in social networks and their implications,” in Proc. of EuroSys, 2009.
Our BFS samples of . qk - observed node degree distribution pk - real node degree distribution BFS sample size: 100K nodes Facebook size: 500M nodes Why?
? - real average node degree - real average squared node degree. Our Goal qk ( f ) = ? Graph traversals on RG(pk): BFS 0 This bias has been empirically observed in the past, but never formally analyzed.
‘stubs’ Graph model RG(pk) • Random graph RG(pk) with a given node degree distribution pk • Can be generated by configuration model: Example:|V| = 4 and pk: p1= p2= p3= p4 = 0.25
Approach 1: Brute force Generate all possible graphs, and ... No way!! Remedy: “The Principle of Deferred Decisions” So we can generate the graph ‘on the fly’, while exploring it!
Approach 2: The Principle of Deferred Decisions v ? u This does not scale! (because of dependencies between stubs) * we assumed that the generated graph is connected
Approach 3: Breaking the stub dependencies v1 v4 V2 3 1 1 2 4 1 3 2 v3 2 1 0 1 time t Originally proposed in: J. H. Kim, “Poisson cloning model for random graphs,” International Congress of Mathematicians (ICM), 2006 (preprint in 2004). Developped in: D. Achlioptas, A. Clauset, D. Kempe, and C. Moore, “On the bias of traceroute sampling: or, power-law degree distributions in regular graphs,” in STOC, 2005. (both in a different context)
Approach 3: Breaking the stub dependencies v1 v4 V2 3 1 1 2 4 1 3 2 v3 2 1 0 1 time t Originally proposed in: J. H. Kim, “Poisson cloning model for random graphs,” International Congress of Mathematicians (ICM), 2006 (preprint in 2004). Developped in: D. Achlioptas, A. Clauset, D. Kempe, and C. Moore, “On the bias of traceroute sampling: or, power-law degree distributions in regular graphs,” in STOC, 2005. (both in a different context)
Approach 3: Breaking the stub dependencies number of nodes of degree k f
Approach 3: Breaking the stub dependencies • The analysis is exactly the same for other graph traversal techniques: • BFS • DFS • Forest Fire • Snowball Sampling • Node sampling weighted by degrees • …
degree distribution corrected! Theory vs Simulations Simulations on a power law random graph with 10K nodes
What if the graph is not random? Random graph RG(pk): Purely random, given the degree distribution pk. Assortative RG(pk): Nodes of similar degree are more likely to connect.
Random Walk - real average node degree - real average squared node degree. Summary Graph traversals on RG(pk): MHRW, RWRW
Random Walk - real average node degree - real average squared node degree. Summary Graph traversals on RG(pk): MHRW, RWRW
For small sample size (for f→0), BFS has the same bias as RW. (also in our Facebook measurements) Random Walk For large sample size (for f→1), BFS becomes unbiased. - real average node degree - real average squared node degree. Summary Graph traversals on RG(pk): MHRW, RWRW This bias monotonically decreases with f. We found analytically the shape of this curve. Thank you!