Generalizability, Reliability and Validity
Generalizability, Reliability and Validity. Elke Johanna de Buhr, PhD Tulane University. Your Research Proposal. I. Introduction A. Problem statement B. Research question(s) C. Hypothesis D. Definitions of terms II. Review of the relevant literature (the more complete, the better)


Generalizability, Reliability and Validity
E N D
Presentation Transcript
Generalizability, Reliability and Validity Elke Johanna de Buhr, PhD Tulane University
Your Research Proposal I. Introduction • A. Problemstatement • B. Research question(s) • C. Hypothesis • D. Definitions of terms II. Review of the relevant literature (the more complete, the better) • A. Importance of the question being asked • B. Current status of the topic • C. Relationship between the literature and the problem statement III. Method • A. Target population • B. Research design and sampling • C. Data collection plans • D. Proposed analysis of the data IV. Implications and limitations
Textbook Chapters and Other Sources • Course textbooks • USC Library Guides, Organizing Your Social Sciences Research Paper, http://libguides.usc.edu/writingguide • And other materials
Data Analysis Plan • Type of data • Qualitative and/or quanititative? Representative of larger population? Standardized vs. open-ended responses? • Type of comparison • Comparison between groups and/or over time? • Type of variable • Categorical and/or continuous? • Type of data analysis • Descriptive analysis and/or hypothesis testing?
Research Limitations • The limitations of the study are those characteristics of design or methodology that impacted or influenced the application or interpretation of the results of your study • They are the constraints on generalizability and utility of findings that are the result of the ways in which you chose to design the study and/or the method used to establish internal and external validity USC Library Guides
Generalizability • When a sample represents a population, the results of the study are said to be generalizable or have generalizability Salkind
SampleSelection • Sample size • Sampling frame • Sampleselection = sampling • Probabilitysampling • Nonprobabilitysampling
Sampling Methods • Census vs. Sampling • Census measures all units in a population • Sampling identifies and measures a subset of individuals within the population • Probability vs. Non-Probability Sampling • Probability sampling results in a sample that is representative of the target population • A non-probability sample is not representative of any population
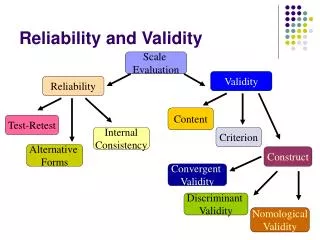
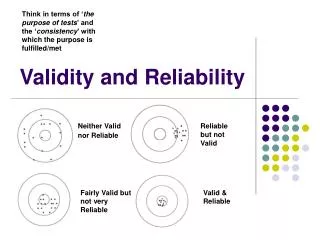
Reliability, Validity and Sensitivity • Reliability • Does the instrument yield consistent results? • Validity • Is the instrument appropriate for what needs to be measured? • Sensitivity • Indicators changing proportionally in response to actual changes in the condition or item being measured?
Reliability • The extent to which the measure produces the same results when used repeatedly to measure the same thing • Variation in results = measurement error • Unreliability in measures obscures real differences Rossi, Lipsey & Freeman
Measurement Errors • Systematic error (we do not measure what we think we measure) • Random error (inconsistencies from one measurement to the next)
Reliability (cont.) • How to verify? • Test-retest reliability: • Most straightforward but often problematic, esp. if measurement cannot be repeated before outcome might have changed • Internal consistency reliability: • Examining consistency between similar items on a multi-item measure • Ready-made measures: • Reliability information available from previous research Rossi, Lipsey & Freeman
Validity • The extent to which a measure measures what it is intended to measure • Usually difficult to test whether a particular measure is valid • However, it is important that an outcome measure is accepted as valid by stakeholders Rossi, Lipsey & Freeman
Validity (cont.) • How to verify? • Empirical demonstrations: • Comparison, often with another measure, that shows that the measure produces the results expected • Demonstration that results of the measure “predict” other characteristics expected to be related to the outcome • Other approaches: • Using data from more than one source, careful theoretical justification based on program impact theory, etc. Rossi, Lipsey & Freeman
Glossary of Threats to Internal Validity • INTERNAL VALIDITY: Any changes that are observed in the dependent variable are due to the effect of the independent variable. They are not due to some other independent variables (extraneous variables, alternative explanations, rival hypotheses). The extraneous variables need to be controlled for in order to be sure that any results are due to the treatment and thus the study is internally valid. • Threat of History: Study participants may have had outside learning experiences and enhanced their knowledge on a topic and thus score better when they are assessed after an intervention independent from the impact of the intervention. (No control group) • Threat of Maturation: Study participants may have matured in their ability to understand concepts and developed learning skills over time and thus score better when they are assessed after an intervention independent from the impact of the intervention. (No control group) • Threat of Mortality: Study participants may drop out and do not participate in all measures. Those that drop out are likely to differ from those that continue to participate. (No pretest) • Treat of Testing: Study participants might do better on the posttest compared to the pretest simply because they take the same test a second time. • Threat of Instrumentation: The posttest may have been revised or otherwise modified compared to the pretest and the two test are not comparable anymore. • John Henry Effect: Control group may try extra hard after not becoming part of the “chosen” group (compensatory rivalry). • Resentful Demoralization of Control Group: Opposite of John Henry Effect. Control group may be demoralized and perform below normal after not becoming part of the “chosen” group. • Compensatory Equalization: Control group may feel disadvantaged for not being part of the “chosen” group and receive extra resources to keep everybody happy. This can cloud the effect if the intervention. • Statistical Regression: Threat to validity in cases in which the researcher uses extreme groups as study participants that have been selected based on test scores. Due to the role that chance plays in test scores, the scores of students that score at the bottom of the normal curve are likely to go up, the scores of those that score at the top will go down if they are assessed a second time. • Differential Selection: Experimental and control group differ in its characteristics. This may influence the results. • Selection-Maturation Interaction: Combines the threats to validity described as differential selection and maturation. If experimental and control group differ in important respects, as for example age, differences in achievement might be due to this maturational characteristic rather than the treatment. • Experimental Treatment Diffusion: Close proximity of treatment and control group might result in treatment diffusion. This clouds the effect of the intervention.
Sensitivity • The extent to which the values of the measure change when there is a change or difference in the thing being measured • Outcome measures in program evaluation are sometimes insensitive because: • They include elements that the program could not reasonably be expected to change • They have been developed for a different (often diagnostic) purpose Rossi, Lipsey & Freeman
Example Margoluis & Salafsky
Sensitivity (cont.) • How to verify? • Previous research: • Identify research in which the measure was used successfully (need to be very similar programs, sample size needs to be sufficiently large ) • Known differences: • Apply the outcome measure to groups of known difference or situations of known change, and determine how responsive it is
Group Discussion • Implications and limitations • Generalizability • Reliability • Validity • Discussion of individual projects • Other questions/concerns