Sample Integrated Fourier Transform(SIFT) With High-Performance ASIC Implementation
Sample Integrated Fourier Transform(SIFT) With High-Performance ASIC Implementation. Contents. Fast Fourier Transform Overview SIFT: An Alternative Approach SIFT: Architecture and Implementation Future Design: 1024-Point SIFT Conclusion. Fast Fourier Transform Overview.


Sample Integrated Fourier Transform(SIFT) With High-Performance ASIC Implementation
E N D
Presentation Transcript
Sample Integrated Fourier Transform(SIFT) With High-Performance ASIC Implementation
Contents • Fast Fourier Transform Overview • SIFT: An Alternative Approach • SIFT: Architecture and Implementation • Future Design: 1024-Point SIFT • Conclusion
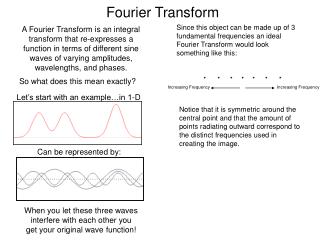
Fast Fourier Transform (FFT) • Computes the Discrete Fourier Transform (DFT) • Requires that N = 2m • The DFT definition equations are:
FFT Butterfly • Butterfly treats one N-point signal as N-single-point signals • Interlaced decomposition: separation into odd and even groups • Decomposition is a reordering of the samples • It is accomplished by a bit reversal algorithm • Ex: sample (0011) exchanged with sample (1100) • Requires log2(N) stages for the decomposition • Ex: A 16 point requires 4 stages
FFT BUTTERFLY + 2 point output 2 point input xS + The basic element of the FFT butterfly.
PROPERTIES OF THE BUTTERFLY • General • FFT butterfly algorithm samples contribute dependently • FFT butterfly requires all samples to begin execution • FFT butterfly reduces the number of multiplies to N x log(N) • FFT Butterfly is a batch process (all samples before execution)
FFT BUTTERFLY PIPELINE 0 T 2T 3T load S1 exe S1 load S2 exe S2 S1, S2 are N-point samples • FFT Butterfly: • Has a Latency of T • Requires Memory to Store Samples • Requires Complex Addressing Scheme
PROPERTIES OF SIFT • Sample contributions compute Independently • Each sample is processed Transactionally • Coefficients are all updated from each sample
ADVANTAGES OF SIFT • Less memory: • After a sample is used, it is not stored • Processing is Transactional • Less Hardware: • • Storing • • Addressing • • Processing
SIFT PIPELINE S1 SN S(N+1) S(2N) 0 T T+1 2T 3T exe Emit Clear exe Emit Clear • Continuous Execution • Low Latency • No Stored Samples
SIFT Pipeline vs. FFT Butterfly Pipeline 0 T 2T 3T 4T FFT Butterfly pipeline load S1 exe S1 load S3 exe S3 load S2 exe S2 load S4 SIFT pipeline exe S1 exe S2 exe S3 exe S4 S1, S2, S3, S4 are N-point samples
There are N/4 - 1 absolute values (other than 0 and 1.)
Basic SIFT Architecture CLOCK STATUS SAMPLE (A) (A x S) (M) (M+A x S) COEFFICIENT (ACC / OUT) RESET
64-Point SIFT • Key factors achieved in SIFT implementation • Silicon Savings • Power Savings • High Speed
Silicon Savings Butterfly FFT SIFT Buffer P P M C M Cache, Buffer and Coefficient Memory with Addressing Only Coefficient Memory is Required
Silicon Savings Aspect Generator Structure Example Encoder 0 Aspect + 1 Clock Sample # Encoder Reset Sample [ ] 0 0 Sequence [ ] 1 1 Forward/Inverse
High Speed • Four-stage pipelined architecture • Continuous execution • High speed SRAM • Simple Gated Aspect Generation • Low Latency Set Aspect Multiply Add Store
Low Power • Fully Static and Synchronous Design • Coefficient Memory Only • No Bus or Addressing System
Performance # of Area Clock Power Execution Time channels (mm2) (MHz) (mW) (micro-second) 10.21 330 8 12.28 20.32 330 8 24.57 40.55 300 9.6 54.07 8 1.01 300 9.6 108.14 161.93 300 9.6 216.28 Technology: 0.18um CMOS, Vdd = 1.8V, Temp = 25C
64-Point Benchmarks CMOS Algorithm Area Frequency Exec Time Latency Power process mm2(MHz) (mili-second) (unit) (mW) TI C54X0.18 Butterfly 144 160 0.01045 1 96 SIFT0.18 SIFT .21 330 0.01228 0 8
Future Design: A 1024-Point SIFT
1024-Point SIFT • 32-point SIFT used as building block • 1 each - 15 bit system counter • 64-multiply/add elements in two sets of 32 • 2 each - 32 segment, 32 word by 24 bit coefficient • memory locations, duplex segments • 1 each - logic to interleave input/output locations
A 1024-Point SIFT Block Diagram Clock Input Stream Output Stream Steering Logic to interleave inputs Single Common Counter 32 cores by 32 deep Interleaved Transform Units with swap-set coefficients FRONT END 32 cores by 32 deep Interleaved Transform Units with swap-set coefficients BACK END
A 1024-Point SIFT Target Performance Execute Time 3.2 microsecond Latency 3.2 microseconds Parallelism 64 MAC per cycle (20.48 GMAC/S sustained rate) Size 25mm2 for 8 bits 49 mm2 for 16 bits Power 250mW 1W Efficiency 89 GMAC/S/W 20 GMAC/S/W Pins 28 pins 44 pins
Benchmarks 1024-Point Complex Input FFT Part NameTi C54x ADSP-2192 DSP24 DFT1024 Algorithm Butterfly Butterfly Butterfly SIFT CMOS process (um) 0.18 NA 0.5 0.18 Frequency (MHz) 160 160 100 320 Exec. Time (micro-s) 263 151 22 3.2 Latency (micro-s) 263 151 22 3.2 Power (mw) 96 NA 3000 500 Area (mm2) 144 400 289 49
Conclusions • SIFT is introduced as an alternative to FFT • SIFT designs presented with simulation results • Low Latency • Low Power • High Speed