Morris-Pratt Algorithm
Morris-Pratt Algorithm. A linear pattern-matching algorithm , Technical Report 40, University of California, Berkeley, 1970. Advisor: Prof. R. C. T. Lee Speaker: C. W. Lu. Morris (Jr), J. H. , Pratt, V. R. Morris-Pratt algorithm.


Morris-Pratt Algorithm
E N D
Presentation Transcript
Morris-Pratt Algorithm A linear pattern-matching algorithm, Technical Report 40, University of California, Berkeley, 1970. Advisor: Prof. R. C. T. Lee Speaker: C. W. Lu Morris (Jr), J. H., Pratt, V. R.
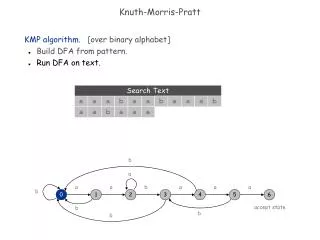
Morris-Pratt algorithm We are given a text T and a pattern P to find all occurrences of P in T and perform the comparisons from left to right. n : the length of T m : the length of P Example
The basic principle of MP Algorithm is step by step comparison. Initially, we compare T(1) with P(1). If T(1) ≠P(1), we move The pattern one step towards the right. Example
Suppose the following condition occurs, should we move pattern P only one step towards the right? The answer is no in this case as we may use Rule 1, the suffix of T to prefix of P rule. j i+j-1 j+m-1 1 n T b i m 1 P a Example
Rule 1: The Suffix of T to Prefix of P Rule For a window to have any chance to match a pattern, in some way, there must be a suffix of the window which is equal to a prefix of the pattern. T P
The Implication of Rule 1: Find the longest suffix v of the window which is equal to some prefix of P. Skip the pattern as follows: T v P v P v
Now, we know that a prefix U of T is equal to a prefix U of P. Thus, instead of finding the longest suffix of T equal to a prefix of P, We may simply find the longest suffix of U of P which is equal to a prefix of P. T U b P U a v Example
Example In this case, we can see the longest suffix of U which is equal to a prefix of P is CA. Thus, we may apply Rule 1 to move P as follows:
The MP Algorithm Assume that we have already found the largest prefix of T which is equal to a prefix of P. T U b P U a
The MP Algorithm Skip the pattern by using Rule 1. T ... v b P c a v v T ... v b P c v Given a substring U of T which is equal to a prefix of P, how do we know the longest suffix of U which is equal to some prefix of P? We do this by pre-processing.
Prefix Function • In preprocessing phase, we would construct a table, named Prefix. • Definition • For location i, let j be the largest j, if it exists, such that P(0,j-1) is a suffix of P(0,i), Prefix(i)=j. • If, for P(0,i), there is no prefix equal to a suffix, Prefix(i)=0.
2 16 4 3 6 8 6 15 9 5 8 1 2 12 7 10 14 11 4 7 5 1 0 3 0 1 4 3 0 0 1 0 13 2 a e a b b c b a b b b c b b a c c Example i • Note that, we move the pattern i-Prefix(i-1) steps when a mismatch occurs at location i. P Prefix
3 6 7 5 2 9 8 11 12 1 4 0 10 g 4 a a c a g c a 0 0 c c 5 1 3 2 1 g 0 0 1 a 0 a 0 How can we construct the Prefix Table Efficiently? • To compute Prefix(i), we look at Prefix(i-1). • In the following example, since Prefix(11)=4, we know that there exists a prefix of length 4 which is equal to a suffix with length 4 of P(0,11). Besides, P(4)=P(12). We may conclude that Prefix(12)=Prefix(11)+1=4+1=5. i P Prefix
3 6 7 2 8 5 10 1 4 0 9 c ? g g g c a 4 g 0 c 2 1 0 c 0 0 1 2 3 c g Another Case • Consider the following example. • Prefix(9)=4. But P(4)≠P(10). • Can we conclude that Prefix(10)=0? • No, we cannot. i P Prefix
5 10 4 9 2 1 0 7 3 6 8 3 0 g a g c g c g c 0 4 2 c 3 2 1 0 0 1 c g • There exists a shorter prefix with length 2 which is equal to a suffix of P(0, 9), and P(10)=P(2). We should conclude that Prefix(10)=2+1=3. i P Prefix
j i-1 • In other words, we may use the pointer idea expressed below: • It may be necessary to examine P(0, j) to see whether there exists a prefix of P(0, j) equal to a suffix of P(0, j). • Thus the Prefix function can be found recursively.
f [0]=0 • for ( i=1 ; i<m ; i++ ){ • t = f (i-1); /*t is the value of f(i-1)*/ • While(t>=0){ • if ( P(i) = P(t) ) { • f [i] = t + 1; • break; • } • else{ • if ( t != 0) • t = f [t-1]; /*recursive*/ • else{ • f [i] = 0; • break; • } • } • } • } Construct the Prefix Function f
1 6 10 7 5 0 3 9 4 6 2 8 7 2 3 4 10 9 0 8 5 1 c g c g c g c c 0 g g c c a c g g c g g c g 0 0 a Example: i P Prefix i P Prefix t = f[i-1] = f[0] = 0; ∵P[1] = c ≠ P[t] = P[0] = b ∴f [1] = 0.
5 6 0 4 8 5 9 10 7 3 1 7 6 3 4 2 1 0 10 9 8 2 c g c g g c 0 0 1 0 g 0 g c c 2 a c g c g c 1 c g g c 0 a g i P Prefix t = f[i-1] = f[0] = 0; ∵P[2] = c = P[t] = P[0] = c ∴f [2] = t + 1 = 1. i P Prefix t = f[i-1] = f[3] = 2; P[4] = a ≠ P[t] = P[2] = c, and t != 0; t = f[t-1] = f[1] = 0; ∵P[4] = a ≠ P[t] = P[2] = c ∴f [4] = 0.
5 6 8 9 5 10 6 4 1 2 0 7 7 4 0 3 2 1 10 9 8 3 c g g g g c 0 c 1 1 3 4 0 3 0 0 0 0 c 2 g 0 g c g 4 c g c c c 2 c g g 1 a 2 0 a 1 2 3 i P Prefix t = f[i-1] = f[8] = 3; ∵P[9] = g = P[t] = P[3] = g ∴f [9] = t + 1 = 4. i P Prefix t = f[i-1] = f[9] = 4; P[10] = c ≠ P[t] = P[4] = a, and t != 0; t = f[t-1] = f[3] = 2; ∵P[10] = c = P[t] = P[2] = c ∴f [10] = t + 1= 3.
Example 0 1 2 3 4 5 6 7 8 9 10 11 1 1 2 2 2 5 6 6 6 6 6 8 i Shift by 1 i - prefix(i-1)
Example 0 1 2 3 4 5 6 7 8 9 10 11 1 1 2 2 2 5 6 6 6 6 6 8 i Shift by 2 i - prefix(i-1)
Example 0 1 2 3 4 5 6 7 8 9 10 11 1 1 2 2 2 5 6 6 6 6 6 8 i Shift by 1 i - prefix(i-1)
Example Match! 0 1 2 3 4 5 6 7 8 9 10 11 1 1 2 2 2 5 6 6 6 6 6 8 i Shift by 8 i - prefix(i-1)
Time Complexity preprocessing phase in O(m) space and time complexity searching phase in O(n+m) time complexity
References AHO, A.V., HOPCROFT, J.E., ULLMAN, J.D., 1974, The design and analysis of computer algorithms, 2nd Edition, Chapter 9, pp. 317--361, Addison-Wesley Publishing Company. BEAUQUIER, D., BERSTEL, J., CHRÉTIENNE, P., 1992, Éléments d'algorithmique, Chapter 10, pp 337-377, Masson, Paris. CROCHEMORE, M., 1997. Off-line serial exact string searching, in Pattern Matching Algorithms, ed. A. Apostolico and Z. Galil, Chapter 1, pp 1-53, Oxford University Press. HANCART, C., 1992, Une analyse en moyenne de l'algorithme de Morris et Pratt et de ses raffinements, in Théorie des Automates et Applications, Actes des 2e Journées Franco-Belges, D. Krob ed., Rouen, France, 1991, PUR 176, Rouen, France, 99-110. HANCART, C., 1993. Analyse exacte et en moyenne d'algorithmes de recherche d'un motif dans un texte, Ph. D. Thesis, University Paris 7, France. MORRIS (Jr) J.H., PRATT V.R., 1970, A linear pattern-matching algorithm, Technical Report 40, University of California, Berkeley.
Knuth-Morris-Pratt Algorithm KNUTH D.E., MORRIS (Jr) J.H., PRATT V.R.,, Fast pattern matching in strings, SIAM Journal on Computing 6(1), 1977, pp.323-350.
Case 1: There exists a suffix of w which equals to a prefix of w. • In MP algorithm, it has two cases to move the pattern from left to right. T P Case 2: No suffix of w which equals to a prefix of w. T P
Case 1: There exists a suffix of w which equals to a prefix of w and z≠x. • KMP algorithm improves the MP algorithm, and it has two cases. T P Case 2: No suffix of w which equals to a prefix of w such that z≠ x. T P
5 1 6 1 7 8 -1 2 0 -1 11 12 16 10 13 9 1 0 1 3 4 14 -1 15 -1 1 0 -1 0 -1 -1 0 -1 4 c b a b c b b e a b b c b b a c a e a b c a b c b b b b a b c b c b a b a c c b c b a a c b … … c c b c a b a b a b b b c b e e b a a c b b i P T: P: Mismatch occurs at location 4 of P. Move P (4 - KMPtable[4]) = 4 - (-1) = 5 steps.
5 1 6 1 7 8 -1 2 0 -1 11 12 16 10 13 9 1 0 1 3 4 14 -1 15 -1 1 0 -1 0 -1 -1 0 -1 4 c b a b c b b e a b b c b b a c a e a b c a b c b b b b a b c b c b a b a c b b a b a a c b … … c c b c a b a b a b b b c b e e b a a c b b i P T: P: Mismatch occurs at location 4 of P. Move P (5 - KMPtable[5]) = 5 - 0 = 5 steps.
5 1 6 1 7 8 -1 2 0 -1 11 12 16 10 13 9 1 0 1 3 4 14 -1 15 -1 1 0 -1 0 -1 -1 0 -1 4 c b a b c b b e a b b c b b a c a e a b c a b c b b b b a b c b c b a b a c b b c b a a c b … … c c b c a b a b a b b b c b b e b a a c b b i P T: P: Mismatch occurs in position 8 of P. Move P (8 - KMPtable[8]) = 8 - 4 = 4 steps.
Example (MP Algorithm) (KMP Algorithm)
Time Complexity Preprocessing phase in O(m) space and time complexity. Searching phase in O(n+m) time complexity.
References • AHO, A.V., 1990, Algorithms for finding patterns in strings. in Handbook of Theoretical Computer Science, Volume A, Algorithms and complexity, J. van Leeuwen ed., Chapter 5, pp 255-300, Elsevier, Amsterdam. • AOE, J.-I., 1994, Computer algorithms: string pattern matching strategies, IEEE Computer Society Press. • BAASE, S., VAN GELDER, A., 1999, Computer Algorithms: Introduction to Design and Analysis, 3rd Edition, Chapter 11, Addison-Wesley Publishing Company. • BAEZA-YATES R., NAVARRO G., RIBEIRO-NETO B., 1999, Indexing and Searching, in Modern Information Retrieval, Chapter 8, pp 191-228, Addison-Wesley. • BEAUQUIER, D., BERSTEL, J., CHRÉTIENNE, P., 1992, Éléments d'algorithmique, Chapter 10, pp 337-377, Masson, Paris. • CORMEN, T.H., LEISERSON, C.E., RIVEST, R.L., 1990. Introduction to Algorithms, Chapter 34, pp 853-885, MIT Press. • CROCHEMORE, M., 1997. Off-line serial exact string searching, in Pattern Matching Algorithms, ed. A. Apostolico and Z. Galil, Chapter 1, pp 1-53, Oxford University Press. • CROCHEMORE, M., HANCART, C., 1999, Pattern Matching in Strings, in Algorithms and Theory of Computation Handbook, M.J. Atallah ed., Chapter 11, pp 11-1--11-28, CRC Press Inc., Boca Raton, FL. • CROCHEMORE, M., LECROQ, T., 1996, Pattern matching and text compression algorithms, in CRC Computer Science and Engineering Handbook, A. Tucker ed., Chapter 8, pp 162-202, CRC Press Inc., Boca Raton, FL. • CROCHEMORE, M., RYTTER, W., 1994, Text Algorithms, Oxford University Press. • GONNET, G.H., BAEZA-YATES, R.A., 1991. Handbook of Algorithms and Data Structures in Pascal and C, 2nd Edition, Chapter 7, pp. 251-288, Addison-Wesley Publishing Company.
References • GOODRICH, M.T., TAMASSIA, R., 1998, Data Structures and Algorithms in JAVA, Chapter 11, pp 441-467, John Wiley & Sons. • GUSFIELD, D., 1997, Algorithms on strings, trees, and sequences: Computer Science and Computational Biology, Cambridge University Press. • HANCART, C., 1992, Une analyse en moyenne de l'algorithme de Morris et Pratt et de ses raffinements, in Théorie des Automates et Applications, Actes des 2e Journées Franco-Belges, D. Krob ed., Rouen, France, 1991, PUR 176, Rouen, France, 99-110. • HANCART, C., 1993. Analyse exacte et en moyenne d'algorithmes de recherche d'un motif dans un texte, Ph. D. Thesis, University Paris 7, France. • KNUTH D.E., MORRIS (Jr) J.H., PRATT V.R., 1977, Fast pattern matching in strings, SIAM Journal on Computing 6(1):323-350. • SEDGEWICK, R., 1988, Algorithms, Chapter 19, pp. 277-292, Addison-Wesley Publishing Company. • SEDGEWICK, R., 1988, Algorithms in C, Chapter 19, Addison-Wesley Publishing Company. • SEDGEWICK, R., FLAJOLET, P., 1996, An Introduction to the Analysis of Algorithms, Chapter ?, pp. ??-??, Addison-Wesley Publishing Company. • STEPHEN, G.A., 1994, String Searching Algorithms, World Scientific. • WATSON, B.W., 1995, Taxonomies and Toolkits of Regular Language Algorithms, Ph. D. Thesis, Eindhoven University of Technology, The Netherlands. • WIRTH, N., 1986, Algorithms & Data Structures, Chapter 1, pp. 17-72, Prentice-Hall.
Simon Algorithm String matching algorithms and automata SIMON I. 1st American Workshop on String Processing, pp 151-157(1993)
Case 1: There exists a suffix of w which equals to a prefix of w and z≠x. • KMP algorithm improves the MP algorithm, and it has two cases. T P Case 2: No suffix of w which equals to a prefix of w such that z≠ x. T P
Case 1:There exists a suffix of w which equals to a prefix of w and z = y • Simon algorithm improves KMP algorithm, and it has two cases. T P Case 2: No suffix of w which equals to a prefix of w such that z= y. T P
Example (MP Algorithm) (KMP Algorithm) (Simon Algorithm)
References • BEAUQUIER, D., BERSTEL, J., CHRÉTIENNE, P., 1992, Éléments d'algorithmique, Chapter 10, pp 337-377, Masson, Paris. • CROCHEMORE, M., 1997. Off-line serial exact string searching, in Pattern Matching Algorithms, ed. A. Apostolico and Z. Galil, Chapter 1, pp 1-53, Oxford University Press. • CROCHEMORE, M., HANCART, C., 1997. Automata for Matching Patterns, in Handbook of Formal Languages, Volume 2, Linear Modeling: Background and Application, G. Rozenberg and A. Salomaa ed., Chapter 9, pp 399-462, Springer-Verlag, Berlin. • CROCHEMORE, M., RYTTER, W., 1994, Text Algorithms, Oxford University Press. • HANCART, C., 1992, Une analyse en moyenne de l'algorithme de Morris et Pratt et de ses raffinements, in Théorie des Automates et Applications, Actes des 2e Journées Franco-Belges, D. Krob ed., Rouen, France, 1991, PUR 176, Rouen, France, 99-110. • HANCART, C., 1993, On Simon's string searching algorithm, Inf. Process. Lett. 47(2):95-99. • HANCART, C., 1993. Analyse exacte et en moyenne d'algorithmes de recherche d'un motif dans un texte, Ph. D. Thesis, University Paris 7, France. • SIMON I., 1993, String matching algorithms and automata, in in Proceedings of 1st American Workshop on String Processing, R.A. Baeza-Yates and N. Ziviani ed., pp 151-157, Universidade Federal de Minas Gerais, Brazil. • SIMON, I., 1994, String matching algorithms and automata, in Results and Trends in Theoretical Computer Science, Graz, Austria, Karhumäki, Maurer and Rozenberg ed., pp 386-395, Lecture Notes in Computer Science 814, Springer Verlag.