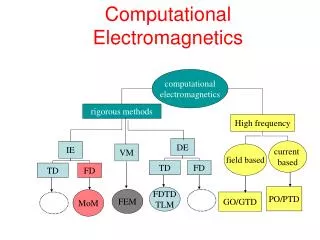
Computational Intelligence: Methods and Applications
In this lecture, we delve into non-parametric density modeling using histograms and Parzen windows. We explore how histograms provide a piecewise constant approximation without assuming specific functional forms and discuss the importance of bin size in these approximations. The lecture will cover the estimation of density using smoothing techniques, including kernel functions such as Gaussian, and the computation of cumulative distribution functions. Additionally, we highlight the significance of the smoothing parameter and its role in achieving a continuous density estimation, extending the discussion to multi-dimensional cases.


Computational Intelligence: Methods and Applications
E N D
Presentation Transcript
Computational Intelligence: Methods and Applications Lecture 28 Non-parametric density modeling Source: Włodzisław Duch; Dept. of Informatics,UMK; Google: W Duch
Density from histograms In 1-D or 2-D it is rather simple, histograms provide piecewise constant approximation – since we do not assume any particular functional dependence such estimation is called “nonparametric”. Histograms change, depending on the size of the bin Bithat measures frequency P(XBi). Smoothing histograms may be done by fitting some smooth functions, such as Gaussians. How good is this approximation?
Why histogram estimation works? Probability that a data point comes from some region R (belongs to some category, etc) is: We are given ndata points, what is the chance Pr that kof these points are from region R? If n=k=1, this Pr=P, in general Pr is the number of combinations in which k points could be selected out of n, multiplied by probability of selecting kpoints from R, i.e. Pk, and selecting n-k points not from R, i.e. (1-P)n-k, that is, the distribution is binomial: Expected k value: Expected variance: Since P(X) VRP = k/n, for a large number of samples n small variance of k/n is expected, therefore this is useful approximation to P(X).
Parzen windows 1D Density estimate using (for standardized data) a bin of size h (a window on the data) in each dimension. For 1D cumulative density function CP(x)=(# observation<x)/N Density is given as a derivative of this function, estimated as: For example, hyperrectangular windows with H(u)=1 for all |uj|<0.5, or hard sphere with 1 inside and 0 outside. Number of points inside: h is called a “smoothing“ parameter Density estimate: Kernel should be H(u)0 and should integrate to 1.
Parzen windows 1D Estimate density using (for standardized data) a bin of size h (a window on the data) in each dimension. For 1D cumulative density function is: P(x<a)=(# observation x<a)/n 1 (this is probability that x<a). Cumulative contributions from all points should sum up to 1, contribution from each interval [x-h/2, x+h/2] with a single observation xi inside is 1/n.For real data this is a stairway function. Density is given as a derivative of this function, but for such staircase data it will be discontinuous, a series of spikes for x=xi values corresponding to real observations.Numerical estimation of density at point x is calculated as:
Parzen 1D kernels We need continuous density estimation, not spikes. Introduce a kernel function indicating if variable is in [-1,+1] interval: Density may be now written as: Density in the window is constant=1, so integrating over each kernel: Integrating over all x gives therefore total probability=1. Smooth cumulative density for x a is then: This is equal to 1/n times the number of xia plus a fraction from the last interval[xi-h/2,a] if a < xi+h/2
Parzen windows dD The window moves with X which is in the middle, therefore density is smoothed. 1D generalizes to dD situations easily: Volume V=hdand the kernel (window) function: Typically hyperrectangular windows with H(u)=1 for all |uj|<1 are used, or hard sphere windows with 1 inside and 0 outside, or some other localized functions. Number of points inside: h is called a “smoothing“ parameter Density estimate: Any function with H(u)0 integrating to 1 may be used as a kernel.
Example with rectangles With large h strong smoothing is achieved (imagine window covering all data ...) Details are picked up when h is small, general shape when it is large. Use as H(u) a smooth function, such as Gaussian; if it is normalized than also the final density is normalized:
Example with Gaussians Dispersion h is also called here smoothing or regularization parameter. A. Webb, Chapter 3.5 has a good explanation of Parzen windows.
Idea Assume that P(X) is a combination of some smooth functions F(X); use an iterative algorithm that adapts the density to the incoming data. Estimate density P(X|C) for each class separately. Since calculation of parameters may be done on a network of independent processors, this leads to the basis set networks, such as the radial basis set networks. This may be used for function approximation, classification and discovery of logical rules by covering algorithms.
Computational Intelligence: Methods and Applications Lecture 29 Approximation theory, RBF and SFN networks Source: Włodzisław Duch; Dept. of Informatics,UMK; Google: W Duch
Basis set functions A combination of m functions may be used for discrimination or for density estimation. What type of functions are useful here? Most basis functions are composed of two functions F(X)=g(f(X)): f(X) activation, defining how to use input features, returning a scalar f.g(f) output, converting activation into a new, transformed feature. Example: multivariate Gaussian function, localized at R: Activation f. computes distance, output f. localizes it around zero.
Radial functions General form of multivariate Gaussian: This is a radial basis function (RBF), with Mahalanobis distance and Gaussian decay, a popular choice in neural networks and approximation theory. Radial functions are spherically symmetric in respect to some center. Some examples of RBF functions: Distance Inverse multiquadratic Multiquadratic Thin splines
G + r functions Multivariate Gaussian function and its contour. Distance function and its contour.
Multiquadratic and thin spline Multiquadratic and an inverse Thin spline function All these functions are useful in theory of function approximation.
Scalar product activation Radial functions are useful for density estimation and function approximation. For discrimination, creation of decision borders, activation function equal to linear combination of inputs is most useful: Note that this activation may be presented as The first term L is constant if the length of W and X is fixed. This is true for standardized data vectors; square of Euclidean distance is equivalent (up to a constant) to a scalar product ! If ||X||=1 replace W.X by ||W-X||2 and decision borders will still be linear, but using instead of Euclidean various other distance functions will lead to non-linear decision borders!
More basis set functions More sophisticated combinations of activation functions are useful, ex: This is a combination of distance-based activation with scalar product activaiton, allowing to achieve very flexible PDF/decision border shapes. Another interesting choice is separable activation function: Separable functions with Gaussian factors have radial form, but Gaussian is the only localized radial function that is also separable. The fi(X;q) factors may represent probabilities (like in the Naive Bayes method), estimated from histograms using Parzen windows, or may be modeled using some functional form or logical rule.
Output functions Gaussians and similar “bell shaped” functions are useful to localize output in some region of space. For discrimination weighted combination f(X;W)=W·X is filtered through a step function, or to create a gradual change through a function with sigmoidal shape (called “squashing f.”, such as the logistic function: Parameter b sets the slope of the sigmoidal function. Other commonly used function are: tangh(bf) (-1,+1), similar to logistic function; semi-linear function: first constant -1, then linear and then constant +1.
Convergence properties Multivariate Gaussians and weighted sigmoidal functions may approximate any function: such systems are universal approximators. The choice of functions determines the speed of convergence of the approximation and the number of functions need for approximation. The approximation error in d-dimensional spaces using weighted activation with sigmoidal functions does not depend on d. The rate of convergence with m functions is O(1/m) Polynomials, orthogonal polynomials etc need for reliable estimation a number of points that grows exponentially with d like making them useless for high-dimensional problems! The error convergence rate is: In 2-D we need 10 time more data points to achieve the same error as in 1D, but in 10-D we need 10G times more points!
Radial basis networks (RBF) RBF is a linear approximation in space of radial basis functions Such computations are frequently presented in a network form: inputs nodes: Xivalues; internal (hidden) nodes: functions; outgoing connections: Wicoefficients. output node: summation. Sometimes RBF networks are called “neural”, due to inspiration for their development.
RBF for approximation RBF networks may be used for function approximation, or classification with infinitely many classes. Function should pass through points: Approximation function should also be smooth to avoid high variance of the model, but not too smooth, to avoid high bias. Taking n identical functions centered at the data vectors: If matrix H is not too big and non-singular this will work; in practice many iterative schemes to solve the approximation problem have been devised. For classification Y(i)=0 or 1.
Separable Function Networks (SFN) For knowledge discovery and mixture of Naive Bayes models separable functions are preferred. Each function component is represented by a single node and if localized functions are used may represent some local conditions. Linear combination of these component functions: specifies the output; several outputs Fc are defined, for different classes, conclusions, class-conditional probability distributions etc.
SFN for logical rules If the component functions are rectangular: then the product function realized by the node is a hyperrectangle, and it may represent crisp logic rule: Conditions that cover whole data may be deleted.
SNF rules Final function is a sum of all rules for a given fact (class). The output weights are either: all Wj = 1, all rules are on equal footing; Wj ~Rule precision (confidence): a ratio of the number of vectors correctly covered by the rule over the number of all elements covered. This may additionally be multiplied by the coverage of the rule, or W may also be fitted to data to increase accuracy of predictions.
Rules with weighted conditions Instead of rectangular functions Gaussian, triangular or trapezoidal functions may be used to evaluate the degree (not always equivalent to probability) of a condition being fulfilled. For example, triangular functions A fuzzy rule based on “triangular membership functions” is a product of such functions (conditions): The conclusion is highly justified in areas where f() is large, shapes =>
RBFs and SFNs Many basis set expansions have been proposed in approximation theory. In some branches of science and engineering such expansions have been widely used, for example in computational chemistry. There is no particular reason why radial functions should be used, but all basis set expansions are mistakenly called now RBFs ... In practice Gaussian functions are used most often, and Gaussian approximators and classifiers have been used long before RBFs. Gaussian functions are also separable, so RBF=SFN for Gaussians. For other functions: SFNs have natural interpretation in terms of fuzzy logic membership functions and trains as neurofuzzy systems. SFNs can be used to extract logical (crisp and fuzzy) rules from data. SFNs may be treated as extension of Naive Bayes, with voting committees of NB models. SFNs may be used in combinatorial reasoning (see Lecture 31).
but remember ... that all this is just a poor approximation to Bayesian analysis. It allows to model situations where we have linguistic knowledge but no data – for Bayesians one may say that we guess prior distributions from rough descriptions and improve the results later by collecting real data. Example: RBF regression Neural Java tutorial: http://diwww.epfl.ch/mantra/tutorial/ Transfer function interactive tutorial.
Computational Intelligence: Methods and Applications Lecture 30 Neurofuzzy system FSM and covering algorithms. Source: Włodzisław Duch; Dept. of Informatics,UMK; Google: W Duch
Training FSM network Parameters of the network nodes may be estimated using maximum likelihood Expectation Maximization learning. Computationally simpler iterative schemes have been proposed. An outline of the FSM (Feature Space Mapping) separable function network algorithm implemented in GhostMiner: • Select the type of functions and desired accuracy. • Initialize network parameters: find main clusters, their centers and dispersions; include cluster rotations. • Adaptation phase: read the training data, if error is made adapt the parameters of the network to reduce them - move the closest centers towards the data, increase dispersions. • Growth phase: if accuracy cannot be improved further add new nodes (functions) in areas where most errors occur. • Cleaning phase: remove functions with smallest coverage, retrain.
Example 1: Wine rules Select rectangular functions; default initialization is based on histograms, looking for clusters around maxima in each dimension; • Create simplest model, starting from low learning accuracy, 0.90. • FSM window shows the convergence and the number of neurons (logical rules for rectangular functions) created by the FSM system. • Different rules with similar accuracy (especially for low accuracy) exist, and the learning algorithm is stochastic (the data is presented in randomized order), so many rules sets are created.
Experiments with Wine rules Run FSM with different parameters and note how different set of rules are generated. FSM may discover new, simple rules, that trees will not find, for ex: if proline > 929.5 then class 1 (48 covered, 3 errors, but 2 corrected by other rules). if color < 3.792 then class 2 (63 cases, 60 correct, 3 errors) Trees generate hierarchical path; FSM covers the data samples with rectangular functions, minimizing the number of features used. FSM includes stochastic learning (samples are randomized). Weak: large variance for high accuracy models. Strong: many simple models may be generated, experts may like some more than the others.
Example 2: Pyrimidines QSAR – Qualitative Structure-Activity Relationship problem. Given a family of molecules try to predict their biological activity. Pyrimidine family has a common template: R3, R4, R5 are places where chemical groups are substituted.The site may be also empty. 9 features are given per chemical group: name, polarity, group name, polarity, size, hydrogen-bond donor, hydrogen bond acceptor, pi-donor, pi-acceptor, polarizability, and the sigma effect. For a single pyrimidine 27(=3*9)features are given; evaluation of relative activity strength requires pair-wise comparison A, B, True(AB) There were 54 features (columns), and 2788 pairs compared (rows).
Pyrimidine results Since ranking of activities is important an appropriate measure of success is the Spearman rank order correlation coefficient: d – distance in ranking pairs, n– number of pairs. 5xCV results LDA 0.65 CART tree 0.50 nodes FSM (Gauss) 0.770.02 (86) FSM (crisp) 0.770.03 (41) 41 nodes with rectangular functions, equivalent to 41 crisp logic rules. Perfect agreement gives +1, perfect disagreement -1, ex: True ranking: X1 X2 ... Xn, predicted ranks Xn Xn-1 .. X1 differences: di= (n-1), (n-2) ... 0 (or 1, for odd n) ... (n-2), (n-1) Sum of d2 is n(n2-1)/3, so rs=-1
Covering algorithms Many machine learning algorithms for learning rules try to cover as many “positive” examples as possible. WEKA contains one such algorithm, called PRISM. • For each class C • E = training data • Create a rule R: IF () THEN C (with empty conditions) • Until there are no more features or R covers all C cases • For each feature A and its possible subset of values (or an interval) consider adding a condition (A=v) or A [v,v’] • Select feature A and values v that maximize rule precision, N(C,R)/N(R) = number of samples from class C covered by R, divided by number of all samples covered by R (ties are broken by selecting largest N(C,R)). • Add to R: IF ( (A=v) ... ) THEN C • Remove samples covered by R from E
PRISM for Wine PRISM in the WEKA implementation cannot handle numerical attributes, so discretization is needed first: this is done automatically via Filtered Classifier approach. • Run PRISM on Wine data and note that: • PRISM has no parameters to play with! • Discretization determines complexity of the rules. • Perfect covering is achieved on whole data. • Rules frequently contain single condition, sometimes two, rarely more conditions. • Rules require manual simplification. • Large number of rules (>30) has been produced. • 10xCV accuracy is 86%, error is 7% and 7% of vectors remain unclassified: covering leaves gaps in the feature space.