Processor Architectures and Program Mapping for Digital Signal Processors
Explore programmable DSP architectures, data types, and operations for real-time signal processing. Learn about DSP programming, code generation, and recent developments.


Processor Architectures and Program Mapping for Digital Signal Processors
E N D
Presentation Transcript
Processor Architectures and Program MappingProgrammable Digital Signal Processors 5kk10 TU/e Henk Corporaal Jef van Meerbergen Bart Mesman
real-time worst-case processing = need for more compute power • sec instr cycles sec • prog prog instr cycle CPI = 1 Topic 2: Programmable Digital Signal Processors • instruction level parallelism (ILP) • hardware support for loop control • attention for high level data types e.g. arrays, delaylines • (vs. scalars for CPUs) • difficult to compare architectures • e.g. DIT, DIF, radix 2/4, FFT loop unrolling, scaling, • shuffling, intialisation … can be included or forgotten • benchmarking (Berkeley Design Technology Inc (BDTi)) • (compare to SpecInt benchmarks for CPs) Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
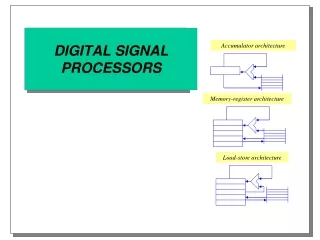
Outline • architectures for programmable DSPs • multiplier-accumulator • modified Harvard architecture • extension with an ALU (decision making) • controller architectures • examples: TI, Motorola, Philips • code generation • recent developments: VLIW (Very Long Instruction Word) • examples: C6 and TM Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Sum of products = basic operation for correlation, filtering, spectral analysis ... c(i) x(i) control linear expr. MPY (Booth, Wallace..) c(i) * x(i) clock P_reg PR ADDER ACR Goal = 1 cycle per iteration • position ACR (1 or 2) • adder/subtractor • extra pipelines • asymmetric inputs • multi-precision • Modifications • extra inputs/outputs Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
0.9 x 0.9 0.81 DSP data types • not every signal requires 32 bits • 2 types of DSP: floating point and integer • advantages FP: most specs are in FP • (conversion to int is time consuming since the behaviour • may change) • disadvantage FP: cost (area, speed, power) • wanted : type of output of an operation = type of input • (because both stored in RAM) • no problem for FP but for integer • integer multiplication doubles the number of bits: n * n => 2n • What about fractional numbers ? Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
DSP data types • integer and fractional numbers are a special case of fixed point • fix <p,q> (ART designer & SystemC) p q 1 0 1 -19/8 = -2.375 1 1 1 fix <8,3> 1 0 -24 23 22 2-2 21 20 2-1 2-3 Scale factor 1/8 negative weight 2’s complement quantization error Same alu handles fix <8,1>, fix <8,2>, fix <8,3>, ... if q=0 then integer e.g. int <8,0> if q=p-1 then fractional e.g. int <8,7> Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
DSP data types -19/8 1 1 1 0 1 1 Int <8,3> 1 0 Int <8,4> 97/16 1 0 1 0 0 1 0 0 -1843/128 1 1 1 0 1 1 1 0 0 0 1 1 1 0 1 0 Some processors (C54) have special instructions for fractional Numbers (and symmetric number domain –2n-1 … 2n-1) s x x x s y y y -------- s s z z z z z z s z z z z z z 0 => if FRCT = 1 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
DSP data types • continue (after multiplication) with msb only • represents the limit of the accuracy of the result • (can not be larger than the accuracy of the inputs) • more efficient solution • continue with msb + lsb • sum-of-product operations generate accumulative noise at 32nd • vs. 16th bit • Still overflow for addition = overflow bits • double precision accumulator • + extra overflow bits • + shift, round, truncate unit Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
c(i) x(i) control MPY (Booth, Wallace..) clock P_reg PR ADDER clock ACR P_reg SHIFT ROUND TRUNCATE Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
xQ xQ xQ x x x rounding value truncation magnitude truncation 1 1 1 . 1 1 -0.25 + 0 0 0 . 1 = 0 0 0 0 1 1 1 . 1 1 -0.25 = 1 1 1 -1 1 1 1 . 1 1 -0.25 + 0 0 1 . = 0 0 0 0 1 1 1 . 0 1 -0.75 + 0 0 0 . 1 = 1 1 1 -1 1 1 1 . 0 1 -0.75 = 1 1 1 -1 1 1 1 . 0 1 -0.75 + 0 0 1 . = 0 0 0 0 Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
zeroing saturation sawtooth Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Prog/data memory prog mem. data mem. prog mem. data mem. 1 data mem. 2 EXU EXU EXU Harvard Modified Harvard Von Neumann (sequencial) c(i) * x(i) Goal = 1 cycle per iteration Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Interrupt address Reset ACU_A ACU_B AR_A AR_B Stack +1 PC Program Memory DR_A DR_B IR Control Bus Rfile RAM_A RAM_B MAC Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
time loop 1 cycle/tap ? ci * xi filter loop i How updating the delayline ? x5 x4 x3 x2 x1 Z-1 Z-1 Z-1 Z-1 c5 c4 c3 c2 c1 * * * * * + y Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Solution 1: blockmove in memory • 2 possibilities • complete move after every output sample is calculated • read and write the data twice • move after read of every datum separately • write the data twice • need for a special instruction (TMS320) Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Solution 2: indirect adressing • use of a pointer to mark the begin of the delay line • update the pointer instead of moving the data • problem: trashing of the whole memory • solution: modulo addressing • need for a register to store the pointer Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
IIR filter pointer y1 y2 y1 y2 y3 y4 y5 y3 Z-1 Z-1 Z-1 Z-1 y4 c1 c2 c3 c4 * * * * y5 x + y memory map Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
pntr 1 pntr 1 2 filters x1 x1 x2 x2 x3 x3 modulo range 1 time loop x4 x4 x5 x5 for i = 1..itaps c(i) * x(i) modulo range pntr 2 y1 y1 for j = 1..jtaps d(j) * y(j) y2 y2 y3 y3 modulo range 2 y4 y4 y5 y5 2 memory segments => 1 segment Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
c5 y3 x3 z-1 z-1 c4 c2 x2 y2 z-1 z-1 c3 c1 x1 y1 Mapping strategy pntr 1 y1 y2 modulo range x1/y3 x2 x3 • Mapping strategy • define positions in Ram • constraint: vars that form a delay line in consecutive places • find a schedule • example : c1 => c2 => c3 => c4 => c5 • define ACU instructions Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
+ yo c7 c5 c3 c1 * * * * x8 x6 x4 x2 Z-1 Z-1 Z-1 Z-1 Z-1 Z-1 Z-1 x7 x5 x3 x1 c2 c6 c4 c8 * * * * + ye Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
ACU architecture and Instruction set A S Output reg A reg S Read_A A A S Read_S S A S incA A+1 A+1 S decA A-1 A-1 S Step A+S A+S S Inc_step S+1 A S+1 Modulo 16 10 000 23 10 111 mask =hold Modulo can be implemented as a mask operation if the size is 2k output to RAM Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
c5 y3 x3 z-1 z-1 c4 c2 x2 y2 z-1 z-1 c3 c1 x1 y1 Mapping example 16 pntr y1 17 y2 18 19 modulo range x1/y3 x2 20 x3 21 22 23 Assume initialisation A = pointer=17 S = -2 read_A 17 incA 18 incA 19 incA 20 incA 21 step 19 dec 18 prepare new pointer for next iteration Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Addressing modes • register ADD R4, R3 R[R4] = R[R4] + R[R3] • immediate ADD R4, #3 R[R4] = R[R4] + #3 • direct ADD R4, (100) R[R4] = R[R4] + Mem[100] • indirect ADD R4, (R3) R[R4] = R[R4] + Mem[R[R3]] • w. inc/dec ADD R4, (R3)± R[R4] = R[R4] + Mem[R[R3]] • R[R3] = R[R3] ± 1 • indexed ADD R4, (R3±R2) R[R4] = R[R4] + Mem[R[R3]] • R[R3] = R[R3] ± R[R2] • Remarks • direct = for static data • indirect = for arrays • inc/dec = for stepping through arrays e.g. xn • index = for stepping through arrays e.g. x2n Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Addressing modes: extra for DSP • 8 ARs (address or auxiliary register) available • extra indirect modes • circular *ARn ± % post inc/dec by 1 - circular • *ARn ± AR0 % post inc/dec by AR0 - circular • bit reverse *ARn ± AR0 B post inc/dec by AR0 - bit rev. Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Incorporation of an ALU • regular data-flow algorithms ==> MAC • filtering, correlation, windowing etc … • decision making ==> ALU • sorting filters (e.g. median filters) • interpolation (e.g. sqrt) • absolute value calculation • logarithmic conversion • finite field aritmetic (e.g. Galois field) • Viterbi • VLC, VLD • division Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Interrupt address Reset ACU_A ACU_B AR_A AR_B Stack +1 PC RAM_A RAM_B Program Memory DR_A DR_B IR MAC ALU Control Bus Rfile Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Bus-oriented instruction encoding ACU A B 00 ALU SY SX DX DY RF ACU A B 01 MULT SY SX DX DY RF ACU A B Imm. data DX DY RF 10 ACU A B 11 Next address BR Cond Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
first solution c(i) * x(i) Not shown coefficient RAM+ACU resources 6 clockcycles/sample limit pipelines in the controller time (cc) Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
ai a0 f f f f f for i = 0 to n bi = f(ai) ci = g(bi) di = h(ci) a1 g g g g g bi b0 ci-2 bi-1 ai for i = 2 to n bi = f(ai) ci-1 = g(bi-1) di-2 = h(ci-2) a2 h h h h h ci c0 b1 c1 di d0 b2 di-2 ci-1 bi c2 d1 d2 Loopfolding (software pipelining) Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Loopfolding (software pipelining) c(i) * x(i) Pre- and postamble 4 clockcycles /sample Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
hardware support for loop control c(i) * x(i) 1 clockcycles/sample repeat instruction and repeat block Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Outline • architectures for programmable DSPs • multiplier-accumulator • modified Harvard architecture • extension with an ALU (decision making) • controller architectures • examples: TI, Motorola, Philips • code generation • recent developments: VLIW (Very Long Instruction Word) • examples: C6 and TM Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
TMS320C5000 T register E D P C D T B A T C B A C D A D Sign ctr Sign ctr A(40) B(40) Sign ctr Sign ctr Sign ctr Multiplier (17*17) MUX A ALU (40) M U A B B 0 A B Barrer shifter fractional MUX MUX COMP Adder (40) MSW/LSW select TRN ZERO SAT ROUND TC Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Address bus 16 bits Motorola 56K family EXTERNAL ADRESS SWITCH P Address Y Address X Address 2,048-by-24-bit PROGRAM MEMORY ROM X memory 256-by-24-bit RAM 256-by-24-bit ROM Address ALU Y memory 256-by-24-bit RAM 256-by-24-bit ROM INTERNAL DATA-BUS SWITCH X-DATA EXTERNAL DATA-BUS SWITCH 24 BITS Y DATA DATA BUS P DATA GLOBAL DATA ON CHIP PERIPHERALS, HOST, SYNCHRONOUS SERIAL INTERFACE SERIAL COMMU- NICATIONS INTERFACE, PROGRAMMED I/O, BUS CONTROL DATA ALU 24-by-24 bit MULTIPLIER- ACCUMULATOR PRODUCING 56 BIT RESULT 24 BITS PROGRAM CONTROLLER I/O PORTS 2 BITS 3 BITS 7 BITS CLOCK INTERRUPT Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
X Y Two address Compution units X data memory Y data memory 16 bit bus 16 bit bus Two 16-by-16 bit multipliers Program control unit Y0 Y0 Y1 Y1 X X PO P1 scale scale 96-bit instructions Program memory (Z data) Instruction decoder Two 40 bit arithmic- logic units shift Saturation Saturation Four 40 bit accumulators 16-bit bus Saturation/scale R.E.A.L. X data Buses for Y data Z data Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
RD16021 DSP Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Instruction cycle counts for BDTi benchmarks 16 taps 40 samples 8 biquads Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Outline • architectures for programmable DSPs • multiplier-accumulator • modified Harvard architecture • extension with an ALU (decision making) • controller architectures • examples: TI, Motorola, Philips • code generation • recent developments: VLIW (Very Long Instruction Word) Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
source lexical analysis syntax analysis Front end semantic analysis Intermediate machine independent representation Code selection Register allocation Code generation scheduling 1 instr = // ops order of instr code Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Intermediate machine independent representation BBi BBk BBj a b c d * c + t1 := a * b t2 := c + d t3 := t1 + c out := t2 * t3 t1 t2 + t3 * Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Intermediate representation RTP match & cover Code selection Register transfer pattern (RTP) for a given datapath is any RT operation ( read - combinatorial logic - write) which can be executed on the datapath. [Leupers] • Notation ar := ar | ax + ay | af means ar := ar + ay or • ar := ar + af or • ar := ax + ay or • ar := ax + af Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Code selection example d memory p memory ADSP [Analog Devices] ax ay af mx my mf x y x y + - * MAC ALU + - ar mr Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Examples of RTPs on the ADSP-210 datapath ar | mr | mx my | mf ar | mr | mx my | mf mr * mr * + - mr | mf mr | mf ar | mr | mx my | mf mr | ar | ax ay | af mr | ar | ax ay | af * + - mr | mf ar | af ar | af Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Example of code selection = covering of intermediate representation with RTPs mx := dmem my := pmem ax := dmem ay := pmem a b c d mr := dmem * c + ar := ax + ay 3: t1 t2 + 2: Mr := mr + (mx * my) t3 * 1: my := ar mr = mr * my Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
Problems • local decisions which have a global impact • phase coupling: example • asap schedule • maximal freedom for scheduling • code selection during scheduling • register allocation comes afterwards • can lead to infeasible solutions Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
1 3 2 Move 4 (c) phase coupling: example 1 1 R2 R3 3 2 alu1 R1 alu2 4 (a) (b) Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
phase coupling: example 2 [Mesman] Pu Pu if u and v share the same register Pv Pv u u v v Cu Cu Cv Cv Example of coupling between scheduling and register allocation Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
phase coupling: discussion [Mesman] application Traditional code generation (heuristic) feasible space constraints OK ? no design space seen by code generator yes Phase coupling is difficult because of many constraints originating from irregular interconnect, special purpose registers and non-orthogonal microcode. Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman
phase coupling: discussion It is very difficult and almost impossible to develop robust and efficient DSP compilers. Current DSP practice = programming in assembler Solution: 1. Solve code generation for DSPs 2. Step back and rethink the architecture develop an architecture which is still efficient but also a good model for building a compiler Efficiency = exploit instruction level parallelism (ILP) compilation = systematic positioning of registers and regular interconnect = VLIW = Very Long Instruction Word Processor Architectures and Program Mapping H. Corporaal, J. van Meerbergen, and B. Mesman