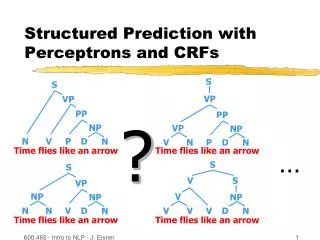
CRFs
CRFs. 米海涛 2007.03.22. Outline:. 1 、 Directed Graph HMM MEMM 2 、 Undirected Graph Conditional Random Fields 3 、 Comparison: HMM MEMM CRF. V2. V1. V4. V3. V5. 1 、 Directed Graph. Directed Graph


CRFs
E N D
Presentation Transcript
CRFs 米海涛 2007.03.22
Outline: • 1、Directed Graph • HMM • MEMM • 2、Undirected Graph • Conditional Random Fields • 3、Comparison: • HMM MEMM CRF
V2 V1 V4 V3 V5 1、Directed Graph • Directed Graph • Directed graph G = (V, E), here V is a set of nodes in G, and E is the edges between the nodes V. In V each Vi represents a random variable.
y1 y2 y3 y4 y5 x1 x2 x3 x4 x5 1.1 Hidden Markov Model • Generative model: Hidden Markov Model ( L.R. Rabiner. 1989) • Disadvantages strict independency assumption on observation; can not handle interaction features and long-distance dependency
y1 y2 y3 y4 y5 X 1.2 Maximum Entropy Markov Model • Discriminative models:MEMM ( Andrew McCallum, 2000) • Given training set X with label sequence Y: • Train a model θ that maximizes P(Y|X, θ) • For a new data sequence x, the predicted label y maximizes P(y|x, θ) • Notice the per-state normalization (Probability of moving from state s to s’ on observation x)
1.2 Maximum Entropy Markov Model • Bias in favor of paths that go through nodes of low entropy • most paths out of a node of high entropy have small probabilities
2.2 CRF • X is a random variable over data sequences to be labeled • Y is a random variable over corresponding label sequences
2.2 CRF • X is a random variable over data sequences to be labeled • Y is a random variable over corresponding label sequences
X y1 y2 y3 y4 y5 2.2 Example • First order CRFs
2.3 Parameter Estimation for CRFs • Parameter Estimation for CRFs • Maximum likelihood parameter estimation:
2.4 Parameter Estimation for CRFs • Learning Algorithm: • GIS • IIS • Quasi Newton Method • L-BFGS
Input Output 2.5 Example: Base Noun Phrase Recognition
y1 y2 y3 y1 y2 y3 y1 y2 y3 x1 x2 x3 X X 3 Comparison: • Graphical comparison among HMM, MEMM and CRF HMM MEMM CRF
y1 y2 y3 x1 x2 x3 HMM • Disadvantage: • Not practical to represent multiple interacting features or long-range dependencies of the observations • Very strict independence assumptions on the observations
y1 y2 y3 X MEMM • Conditional probability P(label sequence S | observation sequence O) rather than joint probability P(O, S) • Allow arbitrary, non-independent features on the observation sequence X • The probability of a transition between labels may depend on past and future observations • Relax strong independence assumptions in generative models
y1 y2 y3 X MEMM • The per-state normalization • Subject to Label Bias Problem • Bias toward states with fewer outgoing transitions
y1 y2 y3 X MEMM • Label Bias Example • P(1 and 2|ro) = P(2 | 1 and ro)P(1 | ro) = P(2 | 1 and o)P(1 | r) P(1 and 2|ri) = P(2 | 1 and ri)P(1 | ri) = P(2 | 1 and i)P(1 | r) • Since P(2 | 1 and x) = 1 for all x, P(1 and 2 | ro) = P(1 and 2 | ri), however, we expect P(1 and 2 | ri) to be greater than P(1 and 2 | ro). • Per-state normalization does not allow the required expectation
P=1 P=1 Label Bias Example P=0.75 • Given: “rib” 3 times, “rob” 1 times • Training: p(1|0, “r”)=0.75, p(4|0, “r”)=0.25 • Inference: P=0.25
CRF: • Given: “rib” 3 times, “rob” 1 times • Training: (constrains) • Init() • w(1|0, “r”)=3, w(2|1, “i”)=3, w(3|2, “b”)=3 • w(4|0, “r”)=1 , w(5|4, “o”)=1, w(3|5, “b”)=1 • Iterator() • L(0453|rib)=w(4|0, “r”)+w(5|4, “i”)+w(3|5, “b”)=1+0+1=2 • L(0123|rib)=3+3+3=9 > L(0453|rib)=1+0+1=2 right • L(0453|rob)=1+1+1=3 < L(0123|rob)=3+0+3=6 wrong • ……… • Final: • w(1|0, “r”)=3, w(2|1, “i”)=3, w(3|2, “b”)=2 • w(4|0, “r”)=2 , w(5|4, “o”)=2, w(3|5, “b”)=2 • L(0123|rib)=3+3+2=8 > L(0453|rib)=2+0+2=4 right • L(0453|rob)=2+2+2=6 > L(0123|rob)=3+0+2=5 right
CRF: • Given: “rib” 3 times, “rob” 1 times • Training: (constrains) • Iterator() • Final: • w(1|0, “r”)=3, w(2|1, “i”)=3, w(3|2, “b”)=2 • w(4|0, “r”)=2 , w(5|4, “o”)=2, w(3|5, “b”)=2 • L(0123|rib)=3+3+2=8 > L(0453|rib)=2+0+2=4 right • L(0453|rob)=2+2+2=6 > L(0123|rob)=3+0+2=5 right • P(0123|rob) = 5/(6+5) • P(0453|rob) = 6/(6+5) • Inference: • L(0453|rob)=2+2+2=6 > L(0123|rob)=3+0+2=5 • P(0453|rob) = 6/(6+5)
X y1 y2 y3 y4 y5 y6 Example • Second order CRFs
Example • Second-order CRFs • Features: • Edge feature type 1 : e1 • State feature type 1 : s1 • Edge feature type 2 : e2 • State feature type 2 : s2
y1 y2 y3 X CRF • CRFs have all the advantages of MEMMs without label bias problem • MEMM uses per-state exponential model for the conditional probabilities of next states given the current state • CRF has a single exponential model for the joint probability of the entire sequence of labels given the observation sequence