How to identify peptides
430 likes | 634 Vues
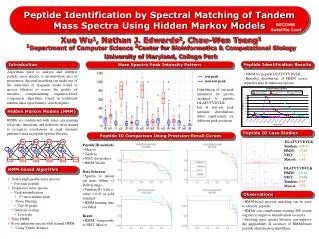
How to identify peptides. Gustavo de Souza IMM, OUS. October 2013. Peptide or Proteins?. Bottom-up Proteomics. 2DE-based approach. Peptide Mass Fingerprinting. MALDI (Matrix Assisted Laser Desorption Ionization). Peptide Mass Fingerprinting. Intensity. m/z. MS/MS. Ion Source. Mass

How to identify peptides
E N D
Presentation Transcript
How to identify peptides Gustavo de SouzaIMM, OUS October 2013
Peptide Mass Fingerprinting MALDI (Matrix Assisted Laser Desorption Ionization)
Peptide Mass Fingerprinting Intensity m/z
MS/MS Ion Source Mass Analyzer Mass Analyzer Mass Analyzer Detector Collision cell
MS/MS 899.013 899.013 899.013
Fragmentation Nomenclature for peptide sequence-ions: Collision-Induced Dissociation (CID): MHnn+* + N2 --> b + y Electron Capture Dissociation(ECD):MHnn++ e- --> MHn(n-1)+· --> c + z·
y y y y y y y 7 6 5 4 3 2 1 O O O O R R R R 2 4 6 8 H H H OH H N N N N 2 N N N N H H H H R R R R 1 3 5 7 O O O O b b b b b b b 1 2 3 4 5 6 7 Fragmentation Roepstorff-Fohlmann-Biemann-Nomenclature
Fragmentation 12 aa … … b ions y ions
MS/MS of a peptide y8 P y++13 VPTVDVSVVDLTVK y10 y6 y9 b5 y12 y11 y4 y5 y7 b6 b3 b10 y3 b4 b8 b7 P y13 b9 y2 b11 b12 b13
How to Identify MS/MS Stenn and Mann, 2004. Peptide Sequence Tags Autocorrelation Probability based match
Protein database (fasta) x x x How identification happen? Your data Step 1: which theoretical peptides has the same mass of the observed ion? Step 2: From those, whichone have the most similarfragmentationpattern?
High mass accuracy – what is it good for? All theoretical tryptic peptide masses from human IPI database Example Tryptic HSP-70 peptide: ELEEIVQPIISK, mass 1396.7813 Da Instrument LTQ QSTAR QSTAR LTQ-FT LTQ-FT LTQ-FT Mass Accuracy 500 20 ppm 10 ppm 2 ppm 1 ppm 0.5 ppm Calibration Ext. Ext. Int. Ext. Ext-SIM Int. # of tryptic peptides for m/z 1396.7813 344 52 33 11 9 3
The “Search Space” 2 mcl 1 mcl 0 mcl 1/2/3 1/2 2/3 2/3/4 4/5 3/4/5 1 3/4 4/5/6 3 5/6 2 4 5 1/2 2/3 1 6 3 2 4/5 4 3/4 5 5/6 6 1 3 2 4 5 6
Importance of Search Space Size Search tool does notidentifya peptide. It only reports the statiscally most suitable theoretical sequence related with the experimental data. If you increase the size of the database too much, or the size of the search space, false-positive rates also increase.
Defining FDRs Steen and Mann, 2004
MOWSE Chance that two peptides with different sequences but approximate Mr and sharing MS/MS similarities. More variables inserted during search Higher chance to get random events Higher MOWSE score threshold • Parameters that can modify the MOWSE calculation: • Database size; • MMD (measured mass deviation); • Number of PTMs choosen; • Data quality.
Probability Based Mowse Score Ions score is -10*Log(P), where P is the probability that the observed match is a random event.Individual ions scores > 7 indicate identity or extensive homology (p<0.05).Protein scores are derived from ions scores as a non-probabilistic basis for ranking protein hits. Example of MMD issue • Mycoplasma sp. sample (Munich 2006): • Database had ~ 700 entries; • Data accuracy had 0.7ppm average; • MMD used during search: 3 ppm.
Strategies to Visualize FDRs Peng et al (2003). Evaluation of multidimensional chromatography coupled with tandem mass spectrometry (LC/LC-MS/MS) for large-scale protein analysis: the yeast proteome. J Prot Res 2, 43-50. Reversed database sequence
How to Validate the Data Are there any Reversed hit protein with 2 peptides above MOWSE score? -No: All proteins identified with 2 peptides score higher than p<0.05 are good -Yes: Repeat mascot search with more stringent parameters. What about 1-hit wonders? (Proteins identified with only 1 peptide)
How to Validate the Data Basically, the idea is to ”play around” with the statistics to make your result more reliable.
Take home message • Data quality (mass accuracy) and a well-defined search space are key for reliable peptide identification • Reliable identification is an interplay between asking enough without asking too much (careful when trying to get “as many IDs as I can”!)
PTMs Gustavo de SouzaIMM, OUS October 2013
Complexity of Protein Samples in Eukaryotes Modifications are specificto a group of amino acids
What difference to expect at MS level? Larsen MR et al, 2006.
PTM abundance in a cell Total peptides in a sample Modified peptides Number of Peptides Abundance level Differences from 10e2 to 10e4
Stable vs. Labile PTMs Larsen MR et al, 2006.
Neutral loss Boersema PJ et al, 2009.
Identifying Labile PTMs Larsen MR et al, 2006.
HCD fragmentation Larsen MR et al, 2006.
Status of PTM coverage Lemeer and Heck, 2009.
Status of PTM coverage Derouiche A et al, 2012.
Take home message • Depending on PTM, identification can be very easy or very hard • Dependent on stability under fragmentation and abundance in the sample • ID improvement was mostly defined by instrumentationimprovements (sensitivity etc)