Vectorization of the 2D Wavelet Lifting Transform Using SIMD Extensions
C. U. M. Vectorization of the 2D Wavelet Lifting Transform Using SIMD Extensions. D. Chaver , C. Tenllado, L. Piñuel, M. Prieto, F. Tirado. Index. Motivation Experimental environment Lifting Transform Memory hierarchy exploitation SIMD optimization Conclusions Future work. Motivation.


Vectorization of the 2D Wavelet Lifting Transform Using SIMD Extensions
E N D
Presentation Transcript
C U M Vectorization of the 2D Wavelet Lifting Transform Using SIMD Extensions D. Chaver, C. Tenllado, L. Piñuel, M. Prieto, F. Tirado
Index Motivation Experimental environment Lifting Transform Memory hierarchy exploitation SIMD optimization Conclusions Future work
Motivation • Applications based on the Wavelet Transform: JPEG-2000 MPEG-4 • Usage of the lifting scheme • Study based on a modern general purpose microprocessor • Pentium 4 • Objectives: • Efficient exploitation of Memory Hierarchy • Use of the SIMD ISA extensions
Experimental Environment Platform Intel Pentium4 (2,4 GHz) DFI WT70-EC Motherboard Cache IL1 NA DL1 8 KB, 64 Byte/Line, Write-Through L2 512 KB, 128 Byte/Line Memory 1 GB RDRAM (PC800) Operating System RedHat Distribution 7.2 (Enigma) Intel ICC compiler GCC compiler Compiler
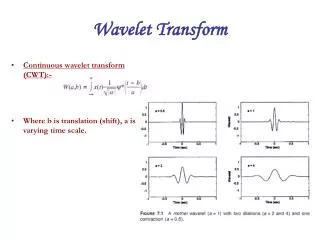
a 1/ β δ x x x x x + + x + + + + + + Lifting Transform Original element 1st step A A D D A D A D 1st 1st 1st 1st 1st 1st 1st 1st 2nd step
Lifting Transform Original element Approximation Horizontal Filtering (1D Lifting Transform) 1 Level N Levels Vertical Filtering (1D Lifting Transform)
2 1 2 1 Lifting Transform Horizontal Filtering Vertical Filtering
2 1 Memory Hierarchy Exploitation • Poor data locality of one component (canonical layouts) E.g. : column-major layout processing image rows (Horizontal Filtering) • Aggregation (loop tiling) • Poor data locality of the whole transform • Other layouts
2 1 2 1 Memory Hierarchy Exploitation Horizontal Filtering Vertical Filtering
2 1 Memory Hierarchy Exploitation Aggregation Horizontal Filtering IMAGE
Memory Hierarchy Exploitation INPLACE • Common implementation of the transform • Memory: Only requires the original matrix • For most applications needs post-processing MALLAT • Memory: requires 2 matrices • Stores the image in the expected order INPLACE-MALLAT • Memory: requires 2 matrices • Stores the image in the expected order Different studied schemes
Horizontal Filtering L H L H L H L H L L H H L L H H Vertical Filtering LL1 HL1 LL3 HL3 LH1 HH1 LH3 HH3 LL2 HL2 LL4 HL4 LH4 HH4 LH2 HH2 Transformed image ... ... LH1 LH2 LH3 LH4 LL1 LL2 LL3 LL4 HL1 LL1 LH1 LL2 LH2 LL3 HL1 HH1 HL2 HH2 Memory Hierarchy Exploitation O O O O MATRIX 1 INPLACE O O O O O O O O O O O O logical view physical view
Horizontal Filtering L L H H L L H H L L H H L L H H Vertical Filtering HL1 HL3 LL1 LL3 HL2 LL2 LL4 HL4 LH1 LH3 HH3 HH1 LH2 LH4 HH4 HH2 ... LH1 LH2 LH3 LH4 LL1 LL2 LL3 LL4 HL1 Transformed image Memory Hierarchy Exploitation O O O O MATRIX 1 MATRIX 2 MALLAT O O O O O O O O O O O O logical view physical view
Horizontal Filtering L H L H L H L H L L H H L L H H Vertical Filtering LL3 HL3 HL1 LL1 LL2 LL4 HL2 HL4 LH1 LH3 HH1 HH3 LH2 LH4 HH2 HH4 ... LL1 LL2 LL3 LL4 Transformed image (Matrix 1) ... LH1 LH2 LH3 LH4 HL1 Transformed image (Matrix 2) Memory Hierarchy Exploitation O O O O INPLACE- MALLAT O O O O MATRIX 2 MATRIX 1 O O O O O O O O logical view physical view
Memory Hierarchy Exploitation • Execution time breakdown for several sizes comparing both compilers. • I, IM and M denote inplace, inplace-mallat, and mallat strategies respectively. • Each bar shows the execution time of each level and the post-processing step.
Memory Hierarchy Exploitation CONCLUSIONS • The Mallat and Inplace-Mallat approaches outperform the Inplace approach for levels 2 and above • These 2 approaches have a noticeable slowdown for the 1st level: • Larger working set • More complex access pattern • The Inplace-Mallat version achieves the best execution time • ICC compiler outperforms GCC for Mallat and Inplace-Mallat, but not for the Inplace approach
SIMD Optimization • Objective: Extract the parallelism available on the Lifting Transform • Different strategies: Semi-automatic vectorization Hand-coded vectorization • Only the horizontal filtering of the transform can be semi-automatically vectorized (when using a column-major layout)
SIMD Optimization Automatic Vectorization (Intel C/C++ Compiler) • Inner loops • Simple array index manipulation • Iterate over contiguous memory locations • Global variables avoided • Pointer disambiguation if pointers are employed
a 1/ β δ x x x x x + + x + + + + + + SIMD Optimization Original element 1st step D A 1st 1st 2nd step
SIMD Optimization Horizontal filtering Vectorial Horizontal filtering a x + a a x + a + a Column-major layout +
SIMD Optimization Vertical filtering Vectorial Vertical filtering a x + a a x + a + a Column-major layout +
SIMD Optimization Horizontal Vectorial Filtering (semi-automatic) for(j=2,k=1;j<(#columns-4);j+=2,k++) { #pragma vector aligned for(i=0;i<#rows;i++) { /* 1st operation */ col3=col3 + alfa*( col4+ col2); /* 2nd operation */ col2=col2 + beta*( col3+ col1); /* 3rd operation */ col1=col1 + gama*( col2+ col0); /* 4th operation */ col0 =col0 + delt*( col1+ col-1); /* Last step */ detail = col1 *phi_inv; aprox = col0 *phi; } }
SIMD Optimization Hand-coded Vectorization • SIMD parallelism has to be explicitly expressed • Intrinsics allow more flexibility • Possibility to also vectorize the vertical filtering
SIMD Optimization Horizontal Vectorial Filtering (hand) /* 1st operation */ t2 = _mm_load_ps(col2); t4 = _mm_load_ps(col4); t3 = _mm_load_ps(col3); coeff = _mm_set_ps1(alfa); t4 = _mm_add_ps(t2,t4); t4 = _mm_mul_ps(t4,coeff); t3 = _mm_add_ps(t4,t3); _mm_store_ps(col3,t3); /* 2nd operation */ /* 3rd operation */ /* 4th operation */ /* Last step */ _mm_store_ps(detail,t1); _mm_store_ps(aprox,t0); a a x + a a + t2 t3 t4
SIMD Optimization • Execution time breakdown of the horizontal filtering (10242 pixels image). • I, IM and M denote inplace, inplace-mallat and mallat approaches. • S, A and H denote scalar, automatic-vectorized and hand-coded-vectorized.
SIMD Optimization CONCLUSIONS • Speedup between 4 and 6 depending on the strategy. The reason for such a high improvement is due not only to the vectorial computations, but also to a considerable reduction in the memory accesses. • The speedups achieved by the strategies with recursive layouts (i.e. inplace-mallat and mallat) are higher than the inplace version counterparts, since the computation on the latter can only be vectorized in the first level. • For ICC, both vectorization approaches (i.e. automatic and hand-tuned) produce similar speedups, which highlights the quality of the ICC vectorizer.
SIMD Optimization • Execution time breakdown of the whole transform (10242 pixels image). • I, IM and M denote inplace, inplace-mallat and mallat approaches. • S, A and H denote scalar, automatic-vectorized and hand-coded-vectorized.
SIMD Optimization CONCLUSIONS • Speedup between 1,5 and 2 depending on the strategy. • For ICC the shortest execution time is reached by the mallat version. • When using GCC both recursive-layout strategies obtain similar results.
SIMD Optimization • Speedup achieved by the different vectorial codes over the inplace-mallat and inplace. • We show the hand-coded ICC, the automatic ICC, and the hand-coded GCC.
SIMD Optimization CONCLUSIONS • The speedup grows with the image size since. • On average, the speedup is about 1.8 over the inplace-mallat scheme, growing to about 2 when considering it over the inplace strategy. • Focusing on the compilers, ICC clearly outperforms GCC by a significant 20-25% for all the image sizes
Conclusions • Scalar version: We have introduced a new scheme called Inplace-Mallat, that outperforms both the Inplace implementation and the Mallat scheme. • SIMD exploitation: Code modifications for the vectorial processing of the lifting algorithm. Two different methodologies with ICC compiler: semi-automatic and intrinsic-based vectorizations. Both provide similar results. • Speedup: Horizontal filtering about 4-6 (vectorization also reduces the pressure on the memory system). Whole transform around 2. • The vectorial Mallat approach outperforms the other schemes and exhibits a better scalability. • Most of our insights are compiler independent.
Future work • 4D layout for a lifting-based scheme • Measurements using other platforms • Intel Itanium • Intel Pentium-4 with hiperthreading • Parallelization using OpenMP (SMT) For additional information: http://www.dacya.ucm.es/dchaver