Source Coding
Source Coding. Source Coding. The purpose of source coding is to reduce the number of bits required to convey the information provided by the information source. For the file of the source data this means compression For the transmission, this is a bit rate reduction. Classification.
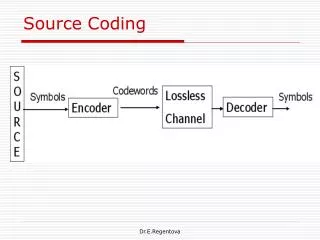

Source Coding
E N D
Presentation Transcript
Source Coding Dr.E.Regentova
Source Coding The purpose of source coding is to reduce the number of bits required to convey the information provided by the information source. • For the file of the source data this means compression • For the transmission, this is a bit rate reduction Dr.E.Regentova
Classification • There are two broad categories of data compression • Lossless compression, such as zip, gzip, gif • Lossy compression, such as mpeg, jpeg .. Dr.E.Regentova
Lossless Compression • An exact copy of the original data is obtained after decompression • Structured data can be compressed to 40-60% of their original size Dr.E.Regentova
Lossy Compression • Original information content is lost • Any data can be compressed significantly (e.g., 100 times) Dr.E.Regentova
What is information The color of the hat is red The color of the table is red The color of the lamp is red The book, hat, and a lamp are red Dr.E.Regentova
INFORMATION THEORY The area of information theory explores the information content of data We can predict the size of the content by modeling data Within a given model we can obtain lower bounds on the number of bits required to represent data Dr.E.Regentova
Modeling-1 Consider the following message of x1, x2,….x12 9,11,11,11,14,13,15,17,16,17,20,21 Using binary encoding scheme, we can store each of these numbers using 5 bits per symbol Dr.E.Regentova
Modeling Information-2 Original message 9,11,11,11,14,13,15,17,16,17,20,21 We can store instead the following 0,2,2,2,5,4,6,8,7,8,11,12 Each of these values represents the number n+9, thus, we can use 4 bits per number . Dr.E.Regentova
Modeling Information-3 Original: 9,11,11,11,14,13,15,17,16,17,20,21 Or, we can store instead the following 9,2,0,0,3,-1,2,2,-1,2,2,-1,1,3,1 The first number is stored as is. To encode xi, we use xi –x i-1. There are only 5 distinct values which can be encoded with 3 bits each Dr.E.Regentova
Probabilistic Modeling-1 An ensemble ‘X’ is a random variable x with a set of possible outcomes Ax ={a1,a2,…. aI}, having probabilities {p1,p2,…pI}, with P(x=aI)=Pi, Pi>=0 and ΣxєAx P(x)=1. A is called Alphabet Dr.E.Regentova
Probabilistic Modeling-2 Source outputs alphabet {1,2,3,4}. Each sample is modeled as a random variable with the probabilities P(1)= 8/15 P(2) = 4/15 P(3)= 2/15 P(4) = 1/15 Dr.E.Regentova
Probabilistic Modeling-3 If no compression takes place, then the simple code with the average 2 bit/symbol is as follows • 1 00 • 2 01 • 10 • 11 Dr.E.Regentova
Problem: Suppose the channel capacity is 1.75 b/sec Dr.E.Regentova
Variable Length Code-1 Intuition: Less bits for higher probability symbols P(1)= 8/15 P(2) = 4/15 P(3)= 2/15 P(4) = 1/15 • 1 0 • 2 10 • 110 • 111 Dr.E.Regentova
Variable Length Code-2 The expected number of bits per code sample (average length l ) is 1*p(1) + 2*p(2) +3*p(3)+3*p(3)= 5/3 That is 1.67. Thus, the channel will transmit the code perfectly. Dr.E.Regentova
Measure of Information Shannon defined a quantity: self-information associated with a symbol in a message. The self-information of a symbol a is given by the formula Dr.E.Regentova
Intuition The higher the probability that a symbol occurs the lower the information content. At the extreme if P(a)=1, then there is nothing learned when receiving an a, since that is the only possibility. Dr.E.Regentova
Entropy Shannon also defined a quantity: ENTROPY associated with a message, representing the average self information per symbol in the message expressed in radix b Dr.E.Regentova
Information Entropy is a measure of information (b/symbol) that gives a low bound for coding. Dr.E.Regentova
Entropy Coding-1 The noiseless source coding theorem (also called Shannon's first theorem) states that an instantaneous code can be found that encodes a source of entropy H(x) with an average number of bits per symbol B such that B=H(x) Assumption: all symbols are independent and identically distributed (iid) Dr.E.Regentova
Entropy Coding-3 P(1)= 8/15 P(2) = 4/15 P(3)= 2/15 P(4) = 1/15 H(x) = -8/15 *log(8/15)-4/15* log(4/15) – 2/15*log(2/15) –1/15 *log(1/15) = 1.5b/symbol Dr.E.Regentova