Download

1 / 30
300 likes | 431 Vues
This document explores the statistical significance of scores derived from various distributions, including Normal, Gamma, and Extreme Value Distributions (EVD). Specifically, it compares a target score of 330 against random database hits to determine its statistical viability using p-values and goodness-of-fit tests. The analysis illustrates how different distribution models behave in real-world applications, such as wind speed and DNA sequence alignment scores, and highlights the importance of choosing appropriate statistical models to understand variability in data effectively.

E N D
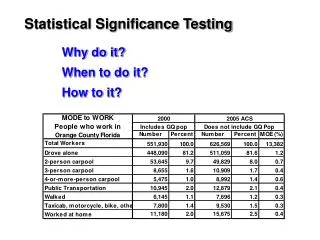
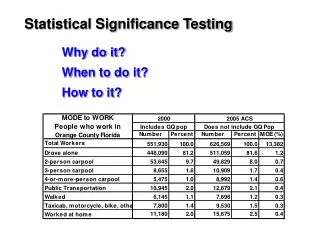
Compare target score with rest of scores The scores of unrelated (random) database hits number Score 330 lies here, way outside the heap of random scores scores
Fit a Normal (Gaussian) distribution m = -47.1 score s = 330 s = 20.8
p-value for Normal distribution The red area is the probability that a random N(-47.1,20.8) distributed variable has score > 0 Pr[s > 0] = 0.0117 > 1-pnorm(330,-47.1,20.8) 1.593339e-73
More distributions • Many more distribution functions for fitting • Gamma distribution • Extreme value distribution • Chi-square distribution • t distribution • Some software packages define hundreds of them
The Gamma function • is the continuation of the factorial n! to real numbers: • and is used in many distribution functions • Moreover,
Gamma distribution • density function, pdf: • expectation • variance • pgamma(x,alpha,1/lambda) • dgamma(x,alpha,1/lambda) • rgamma(n,x,alpha,1/lambda) Gamma a = 3, l = 1/4
a = 1 a = 1/3 a = 3 a = 1/5 a = 5 Shape parameter of Gamma distribution
Gamma distribution and Poisson process • The gamma distribution as limiting process: tiny probability p, many trials n for throwing a 1 in the unit interval [0,1]: l = np • How long does it take until the third 1? a = 3 • 0.11% chance of seeing three 1s in the indicated region 0 1 X
Extreme value distribution • cumulative distribution cdf • probability density pdf • No simple form for • expectation and variance Extreme Value m = 3, s = 4
Examples for Extreme Value Distribution EVD • 1) An example from meteorology: • Wind speed is measured daily at noon: • Normal distribution around average wind speed • Monthly maximum wind speed is recorded as well • The monthly maximum wind speed does not follow a normal distribution, it follows an EVD • 2) Scores of sequence alignments (local alignments) often follow an EVD
Scores for local alignment for DNA sequences 5000 scores mean m = 42.29 sd s = 7.62 Normal distribution N(42.29,7.62) does notfit!
p-value for EVD 0.84 • Probability of seeing a • value higher than 10? • Get it from the cumulative • distribution function (cdf): Extreme value m = 3, s = 4 1-pexval(10,3,4)
Extreme value fits much better m = 38.80 s = 6.14 EVD m = 42.29 s = 7.62 Normal p-value for score 90 EVD 0.00024 Normal 1.9e-10 Normal p-value is misleadingly small compared to EVD
c2 distribution • Standard normal random variables Xi, Xi~N(0,1), • The variable • has a cn2 distribution with n degrees of freedom • density • expectation • variance squared! pchisq(x,n) dchisq(x,n) rchisq(num,x,n)
n = 1 n = 2 n = 4 n = 6 n = 10 Shape of c2 distribution is actually Gamma function with a = n/2 and l = 1/2
t distribution • Z ~ N(0,1) independent of U ~ cn2 • then • has a t distribution with n degrees of freedom • density pt(x,n) dt(x,n) rt(num,x,n)
Shape of t distribution n = 10 N(0,1) • Approaches • normal N(0,1) • distribution • for large n • (n > 20 or 30) n = 3 n = 5 n = 1
Define scalable t distribution • Functions for t distribution in R accept only two • arguments x, the data vector, and n, the degrees of freedom. • pt(x,n) • Functions accepting a location parameter m and • and scaling paramter s • ptt <- function(x,m,s,n) pt((x-m)/s,n) • dtt <- function(x,m,s,n) dt((x-m)/s,n)/s • rtt <- function(sz,m,s,n) rt(sz,n)*s + m
Goodness of fit • So many possible distributions to fit? Which one is • the best. Assessing goodness of fit by • eye (very reliable!) • Kolmogorov-Smirnov test • Shapiro-Wilks test of normality
Assessment of fit by eye: histogram • 200 data points • seem to • follow a normal • distribution with • m = -0.017 • s = 1.45 • But something is • not quite right
Sample cumulative distribution function • At each sample • point the sample cdf • raises by 1/n • (n number of points) • Example: uniformly • distributed points
Assessment of fit by eye: CDFs • Normal • distribution • too wide, • probably an effect • induced by • too many • outliers • t distribution?
t distribution fits better: histogram t Normal • t distribution • with • m = -0.046 • s = 1.12 • n = 4.77 • real data • t(0,1,3) • generated
Formal tests for goodness of fit • Formal tests compare a data set with a suggested • distribution and produce a p-value • If the p-value is small (< 0.05 or < 0.01) it is unlikely that the distribution really fits the data • If the p-value is intermediate (say 0.1 < p < 0.7) there is no strong reason to reject a fit of the distribution, but there might be better ones • If the p-value is high (> 0.7) one might be more confident that the distribution is the right one
Kolmogorov-Smirnovtest • Measures the largest • difference D between • theoretical and • empirical cdf • If data points > 80, there • is a simple rule for • KS test: D
Kolmogorov-Smirnov test of goodness of fit in R • Normal distribution: • ks.test(x,"pnorm", -0.017, 1.45) • Result: p-value = 0.6226 • p-value: 62.3% chance to see such differences in the cdfs of the data and of the normal distribution • t distribution: • ks.test(x,”ptt”,0.046,1.12,4.77) • Result: p-value = 0.9951 • p-value: 99.5% chance to see such differences in the cdfs of the data and of the t distribution!
Shapiro-Wilk normality test in R • shapiro.test(x) • Result: p-value = 0.001027 • Almost no chance that the data come from a • normal distribution! • # generate 200 data points from N(0,1.5) • x <- rnorm(200,0,1.5) • shapiro.test(x) • Result: p-value = 0.2067 • Even normal data get a low p-value!
Conclusions • Problem: Separate interesting, significant signals (scores) from statistical background noise • Solution: Fit a distribution to the data and calculate • the p-value: • Fitting by Maximum Likelihood method • Assessing fit by Kolmogorov-Smirnov • p-value from the cumulative distribution function