Download

1 / 18
180 likes | 201 Vues
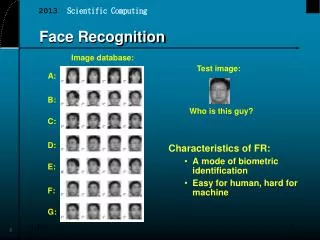
Obtaining Data for Face Recognition from the web. By Tal blum Advisor: Henry Schneiderman. Sample Images. Overview. System Purpose Collecting Data methods System Structure Problems Numbers & Statistics. System Purpose. Collecting face images from the www for:

E N D
Obtaining Data for Face Recognition from the web By Tal blum Advisor: Henry Schneiderman
Overview • System Purpose • Collecting Data methods • System Structure • Problems • Numbers & Statistics
System Purpose Collecting face images from the www for: • Data for face recognition purposes • A system that people can submit images to and it will tell you who are the celebrities they most resemble. • Goal: to collect images of 1000 people with at least 50 images for each
Collection Vs. Web Collecting • Cost • Data size • Aging • Controlled Setting • Limited backgrounds, poses, lightings, etc. • Duplicates • Metadata • Alignment • Tagging Errors • Authorization
System Overview Cleaning/Refinement/ remove duplicates Names Files Spidering Names Files URLs html text Names Extraction Download Images Images Face images Manual Tagging remove duplicates remove faceless
Names Extraction • Sources: • Web Directories • Types: Actors, Politicians, Sports players, singers … • Infomedia project • Extract names from html • Result: Names Files • Cleaning • Duplicates Removed • Refinement
Spidering • 5 different image search engine: • Altavista, Yahoo-news, Yahoo, Picsearch, Alltheweb • Different Interface • Different results quality • Limited availability • Query refinement • Quoted names
Downloading • Gets the URLs and downloads them • Only about 2/3 of the URLs were downloaded • Work in the background http://news.bbc.co.uk/media/images/38378000/jpg/_38941_bushap150.jpg
remove duplicatesremove faceless • Uses simple heuristics to compare files • Uses Schneiderman's face detection algorithm to find faces in the images
Manual Tagging • Decide who is the person by that name • Choose between several people in the image • Add additional metadata s.a. age race, gender … • Problems: unrelated images & multiple people by the same name • Possible classification errors • Go over millions of images
Problems - Name Duplicates • Example: • George Bush, • President George Bush, • George W. Bush • Another example: • Wham (a band) • George Michael
Problems - Name Duplicates • Solution: Detect duplicates on 3 levels • Names – automatic, manual • URLs • By Recognition errors • Approaches • Semi-automatic • Fully-automatic
Numbers & Statistics • We collected 36000 people names • For each we spidered up to 1000 URLs • On average only 1/3 of the URLs reach the manual stage. • So far we run the system on 9500 people • Total # of URLs 1,500,000 • 1,000,000 image files consisting of 60GB. • An average of 157 URLs for person or 182 for person not including people with no URLs
More Information • Contacts: Tal Blum tblum@cmu.edu Henry Schneiderman hws@cs.cmu.edu Acknowledgement to David Fields