Address Translation for Manycore Systems
150 likes | 177 Vues
This presentation discusses the challenges of scaling address translation in manycore systems and explores two coherence methods: shootdown and validation. Results from various simulations and future research directions are also highlighted.

Address Translation for Manycore Systems
E N D
Presentation Transcript
Address Translation for Manycore Systems Scott Beamer Henry Cook CS258 Final Presentation May 14th, 2008
ParLab Background • Parallel (manycore) is coming, how can we use this opportunity to accomplish high level computing goals? • productive, efficient, correct • Context: Mobile Consumer Device • Low power • Single socket • Bursty Workloads • Quality of Service and Response Time important
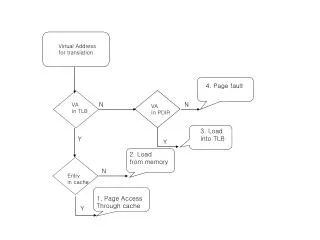
Problem Statement • Modern processors want translation (from VM to PM), how does this scale to parallel? • When a PTE that may be cached in many places is modified, the caches (TLBs) need be kept consistent • Differences from cache coherence problem • Invalidations are much less frequent • Translation can be performed anywhere • Removes it from the critical path • In ParLab, we are using partitions • Spatially dividing tiled cores to work on a single app • Shared L2 cache provided within a partition
Coherence Method: Shootdown • Use a conventional TLB per core • On a PTE modification, broadcast: • Interrupt all other processors • Force them flush relevant entries from their TLB’s • Modification cannot be completed until all processors comply and respond • Can work with any TLB/cache configuration, but synchronization costs are high • In modern SMP OS, software handler is responsible for shootdown
Coherence Method: Validation • Allows cached translations to get stale and fixes them at memory controller • Every TLB entry stores a timestamp for its translation • On a PTE modification, update a generation count associated with the page • On a memory access: • Translation timestamp is checked at memory controller • Outdated translations are fixed and the TLB with the outdated translation is updated • Only gets gain with virtual caches • Virtual cache could save energy because fewer TLB lookups are needed • On context switch virtual cache must be flushed • Other overhead as well
Better Schemes • Shared • Let several cores share a TLB • Could benefit from constructive interference • L2 is already shared, so TLB could be shared at that level • L1 would have to be virtual • Hierarchal • Add a second or third level TLB to reduce reload penalty • Hybrid
Methodology • Virtutech Simics system simulator • ISA functional simulator enhanced with memory hierarchy and TLB timing modules • Can measure latencies from memory access events, count coherence messages • 4, 8, 16, 32, 64, 128 SPARC processor systems • Running unmodified Solaris 10 • Measure behavior over 1B cycles • PARSEC • Princeton Application Repository for Shared Memory Computers
Results - Basic • Blackscholes, 128 entry
Future Work • Investigate the “32 problem” • Further explore design space • Complete validation scheme • Experiment across sharing levels • Experiment across levels of hierarchy • More applications • Several other PARSEC apps recently working • Multiple kernels at same time to show time multiplexing
Conclusion • TLB size most important observed factor so far • Application has some effect • Invalidation rate and type has less effect • TLB coherence network traffic insignificant • Shootdown not bad as a first pass