Bioinformatics and High-Throughput DNA Sequencing at Boston College: A Graduate Student Orientation
On September 8, 2009, Gabor Marth presented an orientation for new biology graduate students at Boston College, focusing on bioinformatics in high-throughput DNA sequencing. He discussed the critical importance of understanding DNA sequence variations, which are pivotal in explaining phenotypic differences, inherited diseases, and ancestral human history. The seminar covered advanced sequencing technologies, data analysis pipelines, SNP and structural variation discovery, and the collaborative resources available for ongoing research at Boston College and beyond.


Bioinformatics and High-Throughput DNA Sequencing at Boston College: A Graduate Student Orientation
E N D
Presentation Transcript
Bioinformatics for high-throughput DNA sequencing Gabor Marth Boston College Biology New grad student orientation Boston College September 8, 2009
DNA sequence variations The Human Genome Project has determined a reference sequence of the human genome However, every individual is unique, and is different from others at millions of nucleotide locations
Why do we care about variations? underlie phenotypic differences cause inherited diseases allow tracking ancestral human history
Genome sequencing ~1 Mb ~100 Mb >100 Mb ~3,000 Mb
Next-gen sequencing – a revolution 100 Gb Illumina/Solexa, AB/SOLiD sequencers (10-30Gb in 25-100 bp reads) 10 Gb 1 Gb Roche/454 pyrosequencer (100-400 Mb in 200-450 bp reads) bases per machine run 100 Mb 10 Mb ABI capillary sequencer 1 Mb 10 bp 100 bp 1,000 bp read length
IND (ii) read mapping (iv) SV calling (iii) SNP and short INDEL calling IND (i) base calling (v) data viewing, hypothesis generation The re-sequencing informatics pipeline REF
… and they give you the picture on the box Read mappingis like a jigsaw puzzle… 2. Read mapping …you get the pieces… Big and Unique pieces are easier to place than others…
The MOSAIK read mapping program • Reads from repeats cannot be uniquely mapped back to their true region of origin Michael Strömberg (Wan-Ping Lee)
SNP discovery Marth et al. Nature Genetics 1999 Quinlan et al. in prep. (AmitIndap, Wen Fung Leong)
Navigation bar Fragment lengths in selected region Depth of coverage in selected region Structural variation discovery Stewart et al. in prep. (DenizKural, Jiantao Wu)
Sequence alignment viewers Huang et al. Genome Research 2008 (Derek Barnett)
Mutational profiling in deep 454 data Pichia stipitis reference sequence Image from JGI web site • Pichiastipitis is a yeast that efficiently converts xylose to ethanol (bio-fuel production) • one specific mutagenized strain had especially high conversion efficiency • goal was to determine where the mutations were that caused this phenotype • we analyzed 10 runs (~3 million reads) of 454 reads (~20x coverage of the 15MB genome) • found 39 mutations • informatics analysis in < 24 hours (including manual checking of all candidates) Smith et al. Genome Research 2008
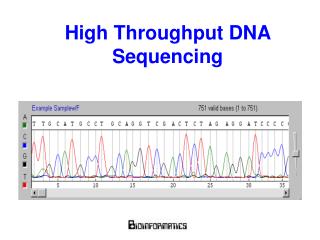
SNP calling in short-read coverage C. elegans reference genome (Bristol, N2 strain) Bristol, N2 strain (3 ½ machine runs) Pasadena, CB4858 (1 ½ machine runs) • goal was to evaluate the Solexa/Illumina technology for the complete resequencing of large model-organism genomes • 5 runs (~120 million) Illumina reads were collected by Washington Univ. • we found 45,000 SNP with very high validation rate SNP Hillier et al. Nature Methods 2008
1000 Genomes Project • data quality assessment • project design (# samples depth of read coverage) • read mapping • SNP calling • structural variation discovery
SV discovery in autism deletion amplification
Resources • computer cluster (72 servers) • 128 GB RAM server • ~200TB disk space • 2 R01 grants (NHGRI/NIH) • 1 R21 grant (NIAID/NIH) • a BC RIG grant • 2 RC2 grants (NHGRI/NIH) starting September 2009
Collaborations Genome Canada Baylor HGSC Wash. U. GSC UBC GSC UCSF UCLA UC Davis Cornell Pfizer NCBI @ NIH NCI @ NIH Marshfield Clinic
Graduate student rotations • Looking for new graduate students • Spots are available for all three rotations • Lots or projects • Caveat: you need to be able to program… • Check us out at: http://bioinformatics.bc.edu/marthlab/ • If you are interested, please talk to me