Cache Memory
Cache Memory. 555-1212. Big is Slow. Consider looking up a telephone number. The more phone numbers stored, the slower the access. In your memory. In your personal organizer. In the personal directory. In the Phone book. Spatial Locality - You’re likely to call a lot of people you know


Cache Memory
E N D
Presentation Transcript
555-1212 Big is Slow • Consider looking up a telephone number • The more phone numbers stored, the slower the access • In your memory • In your personal organizer • In the personal directory • In the Phone book Spatial Locality - You’re likely to call a lot of people you know Temporal Locality - If you call somebody today, you’re more likely to call them tomorrow, too 7.1
Registers And so it is with Computers • Our system has two kinds of memory • Registers • Close to CPU • Small number of them • Fast • Main memory • Big • Slow (50ns) • “Far” from CPU CPU Store Load or I-Fetch Main Memory Assembly language programmers andcompilers manage all transitions betweenregisters and main memory 7.1
... ... IF RF M WB LW EX Memory Access Instruction Fetch The problem... Note: Access time is much faster in some memory modes, but basic access is around 50ns • DRAM Memory access takes around 50ns • At 100 MHz, that’s 5 cycles • At 200 MHz, that’s 10 cycles • At 300 MHz, that’s way too many cycles... • Don’t even get started talking about 1GHz • Since every instruction has to be fetched from memory, we lose big time • We lose double big time when executing a load or store 7.1
A hopeful thought • Static RAMs are much faster than DRAMs • 5-10 ns possible (instead of 50ns) • So, build memory out of SRAMs • SRAMs cost about 20 times as much as DRAM • Technology limitations cause the price difference • Access time gets worse if larger SRAM systems are needed (small is fast...) 7.1
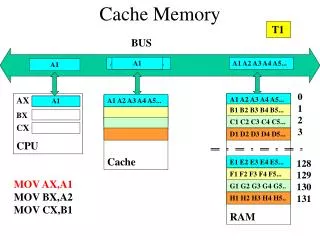
CPU Registers Store Load or I-Fetch SRAM Cache Main Memory (DRAM) A more hopeful thought • Remember the telephone directory? • Do the same thing with computer memory • Build a hierarchy of memories between the registers and main memory • Closer to CPU: Small and fast (frequently used) • Closer to Main Memory: Big and slow (more rarely used) The big question:What goes in the cache? 7.1
Locality p = A[i]; q = A[i+1] r = A[i] * A[i+3] - A[i+2] i= i+1; if (i<20) { z = i*i + 3*i -2; } q = A[i]; name = employee.name; rank = employee.rank; salary = employee.salary; Temporal locality Spatial Locality The program is very likelyto access the same dataagain and again over time The program is very likelyto access data that is closetogether 7.1
Main Memory Fragment 1000 5600 1004 3223 1008 23 1012 1122 1000 1016 5600 0 1016 1020 0 32324 1048 1024 2447 845 1028 1028 43 43 1032 976 1036 77554 1040 433 1044 7785 1048 2447 1052 775 1056 433 The Cache Cache 4 Most recently accessedMemory locations (exploitstemporal locality) Issues: How do we know what’s in the cache? What if the cache is full? 7.2
Goals for Cache Organization • Complete • Data may come from anywhere in main memory • Fast lookup • We have to look up data in the cache on every memory access • Exploits temporal locality • Stores only the most recently accessed data • Exploits spatial locality • Stores related data
6-bit Address Main Memory 00 00 00 5600 00 01 00 3223 00 10 00 23 Cache 00 11 00 1122 01 00 00 0 Valid Index Tag Data 01 01 00 32324 00 Y 00 5600 01 10 00 845 01 Y 11 775 01 11 00 43 10 Y 01 845 10 00 00 976 11 N 00 33234 10 01 00 77554 10 10 00 433 10 11 00 7785 11 00 00 2447 11 01 00 775 11 10 00 433 11 11 00 3649 Direct Mapping In a direct-mapped cache: -Each memory address corresponds to one location in the cache -There are many different memory locations for each cache entry (four in this case) Tag Index Always zero (words) 7.2
Hits and Misses • When the CPU reads from memory: • Calculate the index and tag • Is the data in the cache? Yes – a hit, you’re done! • Data not in cache? This is a miss. • Read the word from memory, give it to the CPU. • Update the cache so we won’t miss again. Write the data and tag for this memory location to the cache. (Exploits temporal locality) • The hitrateand miss rate are the fraction of memory accesses that are hits and misses • Typically, hit rates are around 95% • Many times instructions and data are considered separately when calculating hit/miss rates 7.2
2 1 0 31 12 11 Data Index V Tag 0 1 2 ... ... 1022 1023 A 1024-entry Direct-mapped Cache Memory Address Index 10 Byte offset 20 Tag One Block 20 32 Hit! Data 7.2
2 1 0 31 12 11 Index V Tag Data Tag- 20 bits Index- 10 bits 0 1 11153 2332232 1 1 4323 323 2 0 212 998 3 1 14 34238829 ... 1023 1 8941 1976 address = 0000 0000 0000 0000 11100000 00001100 byte offset=0 index = 3 tag = 14 address = 0000 0000 0000 0000 00110000 00000101 byte offset=1 tag = 3 index = 1 Example - 1024-entry Direct Mapped Cache 3 8764 Assume the cache has been used for awhile, so it’s not empty... LW $t3, 0x0000E00C($0) Hit: Data is 34238829 byte address LB $t3, 0x00003005($0) (let’s assume the word at mem[0x00003004] = 8764) Miss: load word from mem[0x00003004] and write into cache at index 1 7.2
Benchmark Instruction Data miss Combined miss rate rate miss rate So, how’d we do? Miss rates for DEC 3100 (MIPS machine) Separate 64KB Instruction/Data Caches (16K 1-word blocks) gcc 6.1% 2.1% 5.4% spice 1.2% 1.3% 1.2% Note: This isn’tjust the average 7.2
6-bit Address Main Memory 00 00 00 5600 00 01 00 3223 00 10 00 2 1 0 31 23 Cache Tag Index 00 11 00 1122 01 00 00 0 Valid Index Tag Data 01 01 00 32324 00 Y 00 5600 01 10 00 845 01 Y 11 775 01 11 00 43 10 Y 01 845 10 00 00 976 11 N 00 33234 10 01 00 77554 10 10 00 433 10 11 00 7785 11 00 00 2447 11 01 00 775 11 10 00 433 11 11 00 3649 Split depends oncache size Memory Address: Direct Mapping Review Each word has only one placeit can be in the cache: Index must match exactly Tag Index Always zero (words) 7.2
Data (1 word) V Tag Total Memory Requirements For a direct-mapped cache with 2nslots and 32-bit addresses One Slot: 32 bits 1 bit 32 - n - 2 bits byte offset index Total size of a direct-mapped cache with 2n blocks = 2n x (32 + (32 - n - 2) + 1) = 2n x (63 - n) bits Note: Small caches take more space per entry! Warning: Normally “cache size” refers only to the data portion and ignores the tags and valid bits. 7.2
Missed me, Missed me... • What to do on a hit: • Carry on... (Hits should take one cycle or less) • What to do on an instruction fetch miss: • Undo PC increment (PC <-- PC-4) • Do a memory read • Stall until memory returns the data • Update the cache (data, tag and valid) at index • Un-stall • What to do on a load miss • Same thing, except don’t mess with the PC 7.2
Missed me, Missed me... • What to do on a store (hit or miss) • Won’t do to just write it to the cache • The cache would have a different (newer) value than main memory • Simple Write-Through • Write both the cache and memory • Works correctly, but slowly • Buffered Write-Through • Write the cache • Buffer a write request to main memory • 1 to 10 buffer slots are typical 7.2
Types of misses • Cold miss: During initialization, when the cache is empty • Capacity miss: When the cache is full • Conflict miss: The cache is not full, but the data asks for a location that’s taken
Replacement Policy • Which data should be replaced on a capacity/conflict miss? • Random: simple, but not very useful • Least Recently Used (LRU): exploiting spatial locality • Least Frequently Used (LFU): better, but harder to implement
IF RF M WB EX Splitting up • It is common to use two separate caches for Instructions and for Data • All Instruction fetches use the I-cache • All data accesses (loads and stores) use the D-cache • This allows the CPU to access the I-cache at the same time it is accessing the D-cache • Still have to share a single memory Note: The hit rate will probably be lower than for a combined cache of the same total size. 7.2
Data V Tag CacheEntry Word 4 3 2 1 0 31 14 13 Address 10 2 2 18 Index Blockoffset Byteoffset Tag What about Spatial Locality? • Spatial locality says that physically close data is likely to be accessed close together • On a cache miss, don’t just grab the word needed, but also the words nearby • The easiest way to do this is to increase the block size 3 Word 2 Word 1 Word 0 One 4-word Block All words in the same block have the same index and tag Note: 22 = 4 7.2
32 KB / 4 Words/Block / 4 Bytes/Word --> 2K blocks 4 3 1 2 0 31 15 14 Data (4-word Blocks) Index V Tag 0 1 2 ... ... 2046 2047 Mux 0 1 2 3 32 32KByte/4-Word Block D.M. Cache 211=2K Tag Index Byte offset 11 Block offset 17 17 Hit! Data 7.2
Benchmark Block Size Instruction Data miss Combined (words) miss rate miss rate How Much Change? Miss rates for DEC 3100 (MIPS machine) Separate 64KB Instruction/Data Caches (16K 1-word blocks or 4K 4-word blocks) gcc 1 6.1% 2.1% 5.4% gcc 4 2.0% 1.7% 1.9% spice 1 1.2% 1.3% 1.2% spice 4 0.3% 0.6% 0.4% 7.2
Block with index 1000: tag word 3 word 2 word 0 word 1 V 1 3000 23 322 355 2 The issue of Writes Ö On a read miss, we read the entire block from memory into the cache On a write hit, we write one word into the block. The other words in theblock are unchanged. Ö On a write miss, we write one word into the block and update the tag. 4334 2420 Perform a write to a location with index 1000, tag 2420, word 1 (value 4334) The other words are still the old data (for tag 3000). Bad news! Solution 1: Don’t update the cache on a write miss. Write only to memory. Solution 2:On a write miss, first read the referenced block in (including the old value of the word being written), then write the new word into the cache and write-through to memory. 7.2
Choosing a block size • Large block sizes help with spatial locality, but... • It takes time to read the memory in • Larger block sizes increase the time for misses • It reduces the number of blocks in the cache • Number of blocks = cache size/block size • Need to find a middle ground • 16-64 bytes works nicely 7.2
V Tag Data V Tag Data 0: 1: 2 3: 4: 5: 6: 7: 8 9: 10: 11: 12: 13: 14: 15: Other Cache organizations Fully Associative Direct Mapped Index No Index Each address has only one possible location Address = Tag | Index | Block offset Address = Tag | Block offset 7.3
Fully Associative vs. Direct Mapped • Fully associative caches provide much greater flexibility • Nothing gets “thrown out” of the cache until it is completely full • Direct-mapped caches are more rigid • Any cached data goes directly where the index says to, even if the rest of the cache is empty • A problem, though... • Fully associative caches require a complete search through all the tags to see if there’s a hit • Direct-mapped caches only need to look one place 7.3
V Tag Data V Tag Data 0: 0: 1: 1: 2: 3: 2: 4: 5: 3: 6: 7: A Compromise 4-Way set associative 2-Way set associative Each address has four possible locations with the same index Each address has two possible locations with the same index One fewer index bit: 1/2 the indexes Two fewer index bits: 1/4 the indexes Address = Tag | Index | Block offset Address = Tag | Index | Block offset 7.3
Example: ARM processor cache • 4 Kbyte Direct mapped cache • Source: ARM system’s developer’s guide
Example: ARM processor cache • 4 Kbyte 4-way set associative cache • Source: ARM system developer’s guide
Index Index Index V Tag Data V Tag Data V Tag Data 000: 0 0 0 00: 001: 0 0 0 0: 010: 0 0 0 01: 011: 0 0 0 100: 0 0 0 10: 101: 0 0 0 1: 110: 0 0 0 11: 111: 0 0 0 Byte offset (2 bits)Block offset (2 bits)Index (1-3 bits)Tag (3-5 bits) Set Associative Example 0100111000 0100111000 0100111000 Miss Miss Miss Miss Miss Miss 1100110100 1100110100 1100110100 Miss Hit Hit 0100111100 0100111100 0100111100 Miss Miss Miss 0110110000 0110110000 0110110000 1100111000 Miss 1100111000 Miss 1100111000 Hit - 010 011 110 110 010 1 - 01001 1 - 11001 1 - 01101 - 0100 1100 1 1 - 1100 0110 1 Direct-Mapped 2-Way Set Assoc. 4-Way Set Assoc. 7.3
New Performance Numbers Miss rates for DEC 3100 (MIPS machine) Separate 64KB Instruction/Data Caches (4K 4-word blocks) Benchmark Associativity Instruction Data miss Combined rate miss rate gcc Direct 2.0% 1.7% 1.9% gcc 2-way 1.6% 1.4% 1.5% gcc 4-way 1.6% 1.4% 1.5% spice Direct 0.3% 0.6% 0.4% spice 2-way 0.3% 0.6% 0.4% spice 4-way 0.3% 0.6% 0.4% 7.3
Example • Assuming a memory access time of 40 ns and a cache access time of 4 ns, estimate the average access time with a • Hit rate of 90% • Hit rate of 95% • Hit rate of 99%
Example 2 • Assuming a memory access time of 40 ns and a cache access time of 4 ns calculate the hit rate required for an average access time of 5 ns
Example 3 (A) Calculate the cache size, block size and total RAM size for a cache in a 32-bit address bus system assuming: • A 2-bit block offset and a 6-bit index and direct-mapped cache • A 3-bit block offset and a 20-bit tag and a 4-way set associative cache (B) Assuming a 32-bit memory address bus with a main memory access time of 40 ns and a assuming a direct-mapped cache access time of 4 ns, a cache size of 1 KB and a block size of 4 words i) Indicate whether each access in the following address access sequence is a hit or a miss and what kind ii) calculate the access times. The replacement policy is Least Recently Used (LRU). • Lw $4, 0x732A2120($0) • Lb $5, 0x732A2130($0) • Lb $6, 0xA32A232E($0) • Lb $6, 0x732A2320($0) • Lb $6, 0x923B2120($0) • Lb $6, 0x923B2121($0) • Lb $6, 0x532C2122($0) • Lb $6, 0xA32A2123($0) • Lw $4, 0x732A2120($0) • Lb $5, 0x532C2130($0) iii) Calculate the cache hit rate after the above accesses (C) Repeat for a 2-way associative cache (D) Again for a 4-way associative cache
Example 4 Calculate the tag and index fields for a cache in a 32-bit address bus system assuming: • 1 MByte cache size, block size 16, direct mapped cache • 8 KByte cache size, block size 4, 4-way set associative cache Calculate the total RAM required for the implementation of the two caches
Example 5 • Assuming a main memory access time of 40 ns a L1 cache access time of 4 ns and a L2 cache access time of 10 ns: • Calculate the average access time assuming L1 hit rate 95% and combined L1-L2 hit rate 98% • Calculate the required L1-L2 combined hit rate required for an average access time of 4.5 ns assuming L1 hit rate 95%
Example • For the 4KByte, direct-mapped cache with block size 4 shown, show the cache contents after the following accesses • Lw $4, 0x52134120($0) • Lb $5, 0x732A2130($0) • Lb $6, 0xA32A232E($0) • Lb $6, 0x245A2310($0) • Lb $6, 0x923B2120($0)