Genome Analysis & Gene Prediction
350 likes | 621 Vues
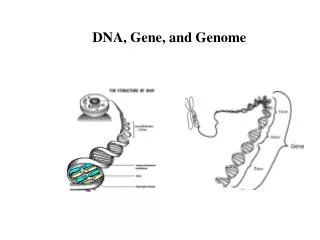
Genome Analysis & Gene Prediction. Overview about Genes. Gene : whole nucleic acid sequence necessary for the synthesis of a functional protein (or functional RNA) A human cell contains approximately 23,000 genes.

Genome Analysis & Gene Prediction
E N D
Presentation Transcript
Overview about Genes Gene : whole nucleic acid sequence necessary for the synthesis of a functional protein (or functional RNA) A human cell contains approximately 23,000 genes. • Some of these are expressed in all cells all the time. These so-called housekeeping genes are responsible for the routine metabolic functions (e.g. respiration) common to all cells. • Some are expressed all the time in only those cells that have differentiated in a particular way. For example, a liver cell expresses continuously the genes for the metabolizing enzymes. • Some are expressed only as conditions around and in the cell change. For example, the arrival of a hormone (due to environmental factors or others) may turn on (or off) certain genes in that cell.
How Gene Expression is Regulated? To Know about gene expression, first we look for the basic structure of a gene.
Terminology • Genome – entire genetic material of an individual • Transcriptome – set of transcribed sequences • Proteome – set of proteins encoded by the genome
Prokaryotic Gene Structure Promoter CDS Terminator UTR UTR Genomic DNA transcription mRNA translation protein
Eukaryotic Gene Structure 5’ - Promoter Exon1 Intron1 Exon2 Terminator – 3’ UTR UTR transcription Poly A translation protein
3 types of RNA polymerases are employed in transcription of genes: • RNA polymerase I transcribes rRNA • RNA polymerase II transcribes all genes coding for polypeptides • RNA polymerase III transcribes small cytoplasmatic RNA, such as tRNA.
Genomic DNA Genomic DNA …3’ 5’….
About Upstream region of a Gene Genomic DNA …3’ 5’…. Upstream
About Core Promoter • basal or core promoter located within about 40 base pairs (bp) of the transcription start site (TSS) • It is found in all protein-coding genes. This is in sharp contrast to the upstream promoter whose structure and associated binding factors differ from gene to gene. • It contains a sequence of TATA box (either canonical TATA box or TATA variant). It is bound by a large complex of some 50 different proteins, including - Transcription Factor IID (TFIID) which is a complex of • TATA-binding protein (TBP), which recognizes and binds to the TATA box • 14 other protein factors which bind to TBP — and each other — but not to the DNA. - Transcription Factor IIB (TFIIB) which binds both the DNA and pol II.
About Upstream Promoter/Regulatory Regions • an "upstream" promoter, which may extend over as many as 200 bp or farther upstream • It has three regions - Proximal region: insulators are possibly present in this region. Insulators are stretches of DNA (as few as 42 base pairs) and located between the • enhancer(s) and promoter or • silencer(s) and promoter of adjacent genes or clusters of adjacent genes. Their function is to prevent a gene from being influenced by the enhancer (or silencer) of its neighbors. - Central Region: Silencers are possibly present in this region. Silencers control regions of DNA that may be located thousands of base pairs away from the gene they control. However, when transcription factors (Silencers) bind to them, expression of the gene they control is repressed. - Distal Region: Enhancers may be present in this region. Enhancer bind to regions of DNA that are thousands of base pairs away from the gene they control. Binding increases the rate of transcription of the gene. Enhancers can be located upstream, downstream, or even within the gene they control.
About Primary Transcript Genomic DNA …3’ 5’…. TSS Exon Intron Exon Exon Intron Stop codon Start codon Donor site Acceptor site mRNA
About Primary Transcript Primary transcript consists of • Cap region: 5' cap is a specially altered nucleotide on the 5' end of precursor messenger RNA. • 5’-UTR: Regions of the gene outside of the CDS are called UTR’s (untranslated regions), and are mostly ignored by gene finders, though they are important for regulatory functions. • Coding sequence (CDS): CDS of a gene is delimited by four types of signals: start codons (ATG in eukaryotes), stop codons (usually TAG, TGA, or TAA), donor sites (usually GT), and acceptor sites (AG). • 3’-UTR: three prime untranslated region (3' UTR) is a particular section of messenger RNA (mRNA). • Poly-A tail: Polyadenylation is the addition of a poly(A) tail to an RNA molecule. The poly(A) tail consists of multiple adenosine monophosphates.
About Intron and Exon • Intron: It is derived from the term intragenic region, i.e. a region inside a gene. these are sometimes called intervening sequences which refer to any of several families of internal nucleic acid sequences that are not present in the final gene product • Exon: these sequences are present in the mature form of an RNA molecule after removing of introns. The mature RNA molecule can be a messenger RNA or a functional form of a non-coding RNA such as rRNA or tRNA.
More about Exon • Three types of exons are defined: • initial exons extend from a start codon to the first donor site; • internal exons extend from one acceptor site to the next donor site; • final exons extend from the last acceptor site to the stop codon; • singleexons(which occur only in intronless genes) extend from the start codon to the stop codon.
Gene Prediction • Analysis by sequence similarity can only reliably identify about 30% of the protein coding genes in a genome • 50-80% of new genes that are identified having partial, marginal, or unidentified homolog • Frequently expressed genes tend to be more easily identifiable by homology than rarely expressed genes
Gene finding is species-specific • Codon usage patterns vary by species • Functional regions (promoters, translation initiation sites, termination signals) vary by species • Common repeat sequences are species-specific • Gene finding programs rely on this information to identify coding regions
Protein Coding Gene • ab initio using computational methods is the most suited to protein-coding genes • Protein-coding genes have recognizable features • open reading frames (ORFs) • codon bias • known transcription and translational start and stop motifs (promoters, 3’ poly-A sites) • splice consensus sequences at intron-exon boundaries
ab initio gene discovery • Protein-coding genes have recognizable features • We can design software to scan the genome and identify these features • Some of these programs work quite well, especially in bacteria and simpler eukaryotes with smaller and more compact genomes • It’s a lot harder for the higher eukaryotes where there are a lot of long introns, genes can be found within introns of other genes, etc.
ab initio gene discovery—Validating predictions and refining gene models Standard types of evidence for validation of predictions include: • match to previously annotated cDNA • match to EST from same organism • similarity of nucleotide or conceptually translated protein sequence to sequences in GenBank • protein structure prediction match to a PFAM domain • associated with recognized promoter sequences, ie TATA box, CpG island • known phenotype from mutation of the locus
Finding Non–protein Coding Genes • Non-protein coding genes (tRNA, rRNA, snoRNA, siRNA, miRNA, various other ncRNAs) are harder to find than protein-coding genes. Because • often not poly-A tailed—don’t end up in cDNA libraries • no ORF • constraint on sequence divergence at nucleotide not protein level, so homology is harder to detect
Finding Non–protein Coding Genes To find out, Non-protein coding genes, we have identify….. • secondary structure • homology, especially alignment of related species • experimentally • isolation through non-polyA dependent cloning methods • microarrays
ab initio gene discovery—approaches • Most gene-discovery programs makes use of some form of machine learning algorithm. A machine learning algorithm requires a training set of input data that the computer uses to “learn” how to find a pattern. • Two common machine learning approaches used in gene discovery (and many other bioinformatics applications) are • Dynamic programming model • Artificial neural networks(ANNs) and • Hidden Markov models(HMMs)
Control of Gene Expression—Transcription Factors • Transcription factors (TFs) are proteins that bind to the DNA and help to control gene expression. The sequences to which they bind are transcription factor binding sites (TFBSs), which are a type of cis-regulatory sequence • Most transcription factors can bind to a range of similar sequences. These can be found in either of two ways, as a consensus sequence, or as a position weight matrix (PWM). • Once we know the binding site, we can search the genome to find all of the (predicted) binding sites
Evidence based Approaches • Comparative or similarity based gene prediction • Combine gene models with alignment to known ESTs & protein sequences
Gene Prediction Tools • SNAP • TwinScan • Gnomon (NCBI) • GeneWise • Jigsaw • GLEAN • Grail • BLAST • FASTAX • BLAT • WABA • MZEF, • MZEF-SPC • FGENESH
Genome Annotation-Much work remains • Despite good progress in identifying both protein coding and non-protein coding genes, much work remains to be done before even the best-studied genomes are fully annotated. • For the higher eukaryotes, only a tiny percentage of features such as TFBSs and other non-gene features have so far been indentified.
References • http://users.rcn.com/jkimball.ma.ultranet/BiologyPages/P/Promoter.html