Download

1 / 17
170 likes | 308 Vues
Reconnaissance de Yes/No à l’aide du HTK. Adapté d’un tutoriel du HTK par Nicolas Moreau. Étapes de la réalisation. Création de l’ensemble d’apprentissage : Chaque élément du vocabulaire est enregistré plusieurs fois, et étiqueté avec le mot correspondant

E N D
Reconnaissance de Yes/No à l’aide du HTK Adapté d’un tutoriel du HTK par Nicolas Moreau
Étapes de la réalisation • Création de l’ensemble d’apprentissage : Chaque élément du vocabulaire est enregistré plusieurs fois, et étiqueté avec le mot correspondant • Analyse acoustique : Les signaux enregistrés sont convertis en une série de vecteurs de traits. • Définition des modèles HMM : Un HMM est défini pour chaque élément du vocabulaire de la tâche de reconnaissance. • Entraînement des modèles HMM : Chacun est entraîné avec l’ensemble d’apprentissage correspondant. • Définition de la tâche de reconnaissance : La grammaire à suivre est définie. • Reconnaissance et évaluation de la performance sur un corpus de test.
Organisation de l’espace de travail • On crée la hiérarchie de répertoires suivante : • data/ : emmagasine les données d’apprentissage et de test (signaux acoustiques, étiquettes, etc.) dans deux sous-répertoires data/train/ et data/test/. • analysis/ : emmagasine les donnés de l’étape d’analyse acoustique. • training/ : emmagasine les fichiers concernant l’initialisation et l’apprentissage. • model/ : Emmagasine les modèles (HMMs). • def/ : emmagasine les fichier de définition de la tâche de reconnaisance. • test/ : emmagasine les fichier ayant trait à la validation (test).
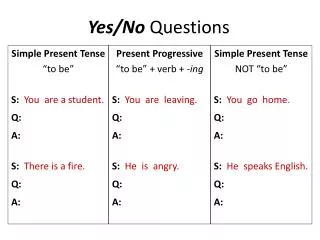
Création du corpus d’apprentissage • L’enregistrement et l’étiquetage sont accomplis à l’aide de l’outil HSLab (boutons rec, stop,mark et labelAs) : HSLab nom.sig Après l’étiquetage, on obtient un fichier texte .lab de la forme 4171250 9229375 sil 9229375 15043750 yes 15043750 20430625 sil • On recommence le processus avec des noms de fichiers différents pour chaque enregistrement (e.g. yes01.sig, yes01.lab, yes02.sig, yes02.lab, etc.)
Analyse acoustique • On utilise l’outil HCopy : • HCopy -A -D -C analysis.conf -S targetlist.txt analysis.conf : fichier de configuration pour l’extraction des coefficients acoustiques targetlist.txt : script spécifiant les noms et locations de chaque signal à traiter et du fichier de coefficients correspondant à générer.
MFCC_0_D_A = 12 MFCC + DC + 13 Delta + 13 Acceleration =39 coeff.
Définition structurelle des HMM • Il faut définir le nombre d’états, les fonctions d’observation et les probabilité de transition entre états : pas évident ! • Il faut définir 3 prototypes de HMM avec les options ~h "yes", ~h "no" and ~h "sil " dans les fichiers de description (hmm_yes, hmm_no, hmm_sil, )
Entraînement des HMM Elle comprend une phase d’initialisation et une phase d’entraînement pour chaque HMM
Entraînement des HMM • Initialisation 1: alignement temporel par algorithme de viterbi • HInit -A -D –T 1 -S trainlist.txt -M model/hmm0 \ -H model/proto/hmmfile -l label -L label_dir nameofhmm • nameofhmm : le nom du HMM à initialiser • hmmfile : fichier descriptif contenant le prototype du HMM • trainlist.txt : liste complète des fichiers .mfcc constituant le corpus d’apprentissage • label_dir : Répertoire des fichiers d’étiquetage (.lab) correspondant au corpus d’apprentissage • label : indique quel segment étiqueté doit être utilisé sans l’ensemble d’apprentissage (yes,no, ou sil, puisqu’on a utilisé ces noms pour étiqueter les HMMs) • model/hmm0 : Répertoire de sortie (doit exister) pour la description de HMM résultante. • La procédure doit être répétée pour chaque modèle (hmm_yes, hmm_no, hmm_sil).
Entraînement des HMM • Initialisation 2: initialisation des moyenne et variances • HCompv -A -D –T 1 -S trainlist.txt -M model/hmm0flat \ • -H model/proto/hmmfile -f 0.01 nameofhmm • nameofhmm: le nom du HMM à initialiser • hmmfile: fichier descriptif contenant le prototype du HMM • trainlist.txt : liste complète des fichiers .mfcc constituant le corpus d’apprentissage • label_dir : Répertoire des fichiers d’étiquetage (.lab) correspondant au corpus d’apprentissage • label : indique quel segment étiqueté doit être utilisé sans l’ensemble d’apprentissage (yes,no, ou sil, puisqu’on a utilisé ces noms pour étiqueter les HMMs) • model/hmm0flat : Répertoire de sortie (doit exister) pour la description de HMM résultante, doit être différenet que celui de HInit. • La procédure doit être répétée pour chaque modèle (hmm_yes, hmm_no, hmm_sil) • Pas requis si Hinit utilisé, cependant génère un fichier vFloors qui contient les variances multipliées par un coefficient établi avec l’option –f (0.01 ci-dessus)
Entraînement des HMM • Entraînement • HRest -A -D -T 1 -S trainlist.txt -M model/hmmi -H vFloors \ • -H model/hmmi-1/hmmfile -l label -L label_dir nameofhmm • Nameofhmm, hmmfile, trainlist.txt, label_dir, label : comme avant • model/hmmi : Répertoire de sortie pour l’itération courante. • La procédure est répétée plusieurs fois pour chaque modèle (hmm_yes, hmm_no, hmm_sil). Le processus s’arrête lorsqu’une variable affichée à l’écran, change, devient constante
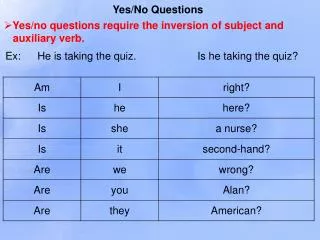
Définition de la tâche de reconnaissance • Sauvée dans un fichier gram.txt • $word : variable qui prend les valeurs yes ou no • { } : zéro ou plusieurs répétions du contenu • [ ] : zéro ou une répétition du contenu • Les HMM correspondant aux variables start_sil, end_sil, yes et no doivent être prédéfinis et la correspondance emmagasinée dans un fichier texte (le dictionnaire de tâche) • colonne gauche : variable • Colonne droite : HMM • Milieu : nom du résultat émis
Définition de la tâche de reconnaissance • Le fichier gram.txt doit être compilé pour générer un réseau de tâche HParse -A -D -T 1 gram.txt net.slf • Le système constitué du réseau de tâche, du dictionnaire de t6ache et des HMM associés est alors prêt pour faire de la reconnaissance de parole
La reconnaissance en temps différé • HVite -A -D -T 1 -H hmmsdef.mmf -i reco.mlf -w net.slf \ • dict.txt hmmlist.txt input.mfcc • input.mfcc: les données d’entrée à reconnaître • hmmlist.txt: liste des modèles à utiliser (yes, no, dil), un par ligne • dict.txt: dictionnaire de tâche • reco.mlf : fichier de sortie • hmmsdef.mmf : contient les définitions des HMM concaténées
La reconnaissance en temps réel • On peut aussi faire de la reconnaissance en direct ! HVite -A -D -T 1 -C directin.conf -g -H hmmsdef.mmf \ -w net.slf dict.txt hmmlist.txt • directin.conf : fichier de configuration de l’entrée audio • Pas de fichier préenregistré! À l’invite READY, on dit un mot au micro et en pressant une clé du clavier, la réponse est fournie.