Download

1 / 27
270 likes | 531 Vues
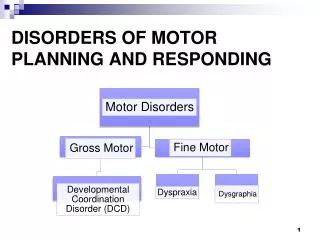
From Motor Babbling to Planning. Cornelius Weber Frankfurt Institute for Advanced Studies Johann Wolfgang Goethe University, Frankfurt, Germany Bio-Inspired Autonomous Systems Workshop 26 th - 28 th March 2008, Southampton. Reinforcement Learning: Trained Weights. actor units. value.

E N D
From Motor Babbling to Planning Cornelius Weber Frankfurt Institute for Advanced Studies Johann Wolfgang Goethe University, Frankfurt, Germany Bio-Inspired Autonomous Systems Workshop 26th - 28th March 2008, Southampton
Reinforcement Learning: Trained Weights actor units value fixed reactive system that always strives for the same goal
reinforcement learning does not use the exploration phase to learn a general model of the environment that would allow the agent to plan a route to any goal so let’s do this
Learning randomly move around the state space actor learn world models: ● associative model ● inverse model ● forward model state space
Learning: Associative Model weights to associate neighbouring states use these to find any possible routes between agent and goal
Learning: Inverse Model weights to “postdict” action given state pair use these to identify the action that leads to a desired state Sigma-Pi neuron model
Learning: Forward Model weights to predict state given state-action pair use these to predict the next state given the chosen action
Planning actor units goal agent
Discussion - reinforcement learning ... if no access to full state space - previous work ... AI-like planners assume links between states - noise ... wide “goal hills” will have flat slopes - shortest path ... not taken; how to define? - biological plausibility ... Sigma-Pi neurons; winner-take-all - to do: embedding ... learn state space from sensor input - to do: embedding ... let the goal be assigned naturally - to do: embedding ... hand-designed planning phases
Acknowledgments Collaborators: Jochen Triesch FIAS J-W-Goethe University Frankfurt Stefan Wermter University of Sunderland Mark Elshaw University of Sheffield