TILECAL ReadOut System
300 likes | 431 Vues
TILECAL ReadOut System. Diseño de un sistema de adquisición de datos entre los niveles 1 y 2 de trigger para el calorímetro hadrónico de ATLAS en LHC. Jose Castelo, Esteban Fullana XXIX Reuniones Bienales de Física y Química Madrid, 9 de Julio 2003. Sumario.

TILECAL ReadOut System
E N D
Presentation Transcript
TILECAL ReadOut System Diseño de un sistema de adquisición de datos entre los niveles 1 y 2 de trigger para el calorímetro hadrónico de ATLAS en LHC Jose Castelo, Esteban Fullana XXIX Reuniones Bienales de Física y Química Madrid, 9 de Julio 2003
Sumario • Introducción al sistema de adquisición RoD del calorímetro hadrónico tilecal
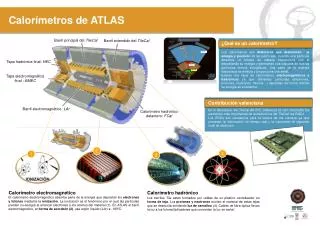
ATLAS TDAQ: Sistema de disparo y adquisición de datos • Decisión de LVL1 es tomada con los datos del calorímetro (basta granularidad) y los datos de trigger de las cámaras de muones. El “buffering” de eventos se hace en la electrónica dentro del detector (FEB). • Decisión de LVL2 se realiza teniendo en cuenta Regiones de Interés ROIs (hasta un 4% del evento completo) con granularidad total y combinando información de todos los detectores. El “buffering” se realiza en RoBs. • El EF refina la selección, puede realizar la reconstrucción de eventos con granularidad total. El “buffering” se hace en EB y EF. RODs
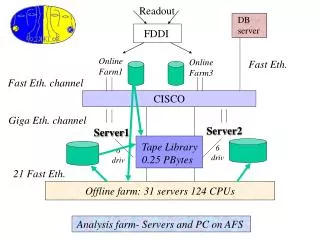
Sistema de adquisición de datos RoDFlujo de datos y particiones de disparo (TTC) 9856 canales del calorímetro . (Dos fibras/drawer. 19712 ch con información redundante) Usando la nueva tarjeta más integrada: sólo 8 RODs/partición. Total 32 RODs en vez de 64 (especificación de TDR)
Level 1 Of USA 15 Level 2134 racks Detector Cavern UX15 Row 19 Row 16 USA15 Level 1 104 racks Tilecal 2 rows: 19 and 16 USA15 7 x 52 U high racks/row Instalación Tilecal RoD: LEVEL 1 of USA15
Esquema de Particiones TTC • Número de particiones TTC: 4 • Organizados en f [0, 2p]: EB(h<0), CB(h<0), CB(h>0), EB(h>0) • Esta distribución nos permite trabajar con independencia en los barriles del calorímetro. • Cada RODcrate conforma una Partición TTC con un TBM (Trigger and Busy Module) cada una
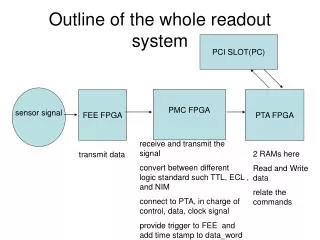
Módulo ROD final: Funcionalidades básicas • Flujo de datos: • Procesado de datos: Envío y procesado de Raw Data desde FEB a los ReadOut buffers (ROB) con una frecuencia de eventos de L1A de 100KHz. Es decir, se dispone de 10ms para procesar un total ~10.000 canales (celdas) de datos digitalizados de un par PMT/centelleador. • Detección de Errores: Cada módulo debe chequear BCid y EvtID con los recibidos con los datos de FE. También se comprueban los datos para detectar alineación y consistencia (paridad, CRC). • Enlaces/links de datos: • Entrada: Fibra óptica. Enlaces integrados basados en G-link como capa física. • Salida: Fibra óptica. Basados en estandar s-link, y con formato de datos estándar de atla (DAQ-1 req.) • Interfase con Procesador central de trigger (CTP): • TRIGGER o DISPARO: Las señales de TTC serán recibidas por cada módulo con una latencia de ~2ms para habilitar de sincronismo al sistema (EvtID, TType, BCx). • Generación de señal OCUPADO/BUSY: Retroalimentación al CTP para parar la generación de triggers de nivel 1. Cada unidad de proceso genera un Busy que es una función OR de todos los BUSY de una partición. • Control y Monitoreo de información: • Provee acceso a la tarjeta sin introducir tiempos-muertos al flujo de datos. Cada Placa madre ROD provee de acceso VME en modo esclavo comandado por el Controlador de la Crate ROD. • Configura y hace booting de firmware (FPGAs y DSPs) así como de constantes de calibración y otros parámetros. 2 Prototipos disponibles en Septiembre de 2003
Sumario • Introducción al sistema de adquisición RoD del calorímetro hadrónico tilecal • Estudio de algoritmos de reconstrucción on-line
Introducción • 4 Algoritmos han sido estudiados: • Ajuste de la señal (FIT). Actualmente no implementable debido al alto coste computacional iterativo. • Algoritmo de Filtrado Óptimo (Optimal Filtering OF). • Algoritmo de Filtrado Plano (Flat Filtering FF). • Algoritmo de Muestra Máxima (Maximum Sample MS). • Se han aplicado a datos reales del testbeam de Julio 2002
x x x x x x x x x Algoritmo de Ajuste o FIT Reconstrucción de la forma de onda para cada canal y ganancia 45·2 conjuntos de 4 parámetros CIS NTUPLE Ajuste a una función analítica con 4 parámetros como salida Ganancia Canal f(t) E & τ Ajuste evento a evento con 2 parámetros como salida y un Chi2 χ2 {S’i} {S’i}
x x x x x x x x x Algoritmo de Optimal Filtering (OF) CIS NTUPLE 45·2 conjuntos de pesos de Optimal Filtering. f(t) f’(t) 45·2 conjuntos de 4 parámetros ai bi PEDESTAL EVENTS 45 conjuntos de matrices Rij Ch & g Ch & g ai E Gain Channel χ2 {S’i} {S’i} bi τ
x x x x x x x x x Algoritmo de Flat Filtering (FF) El algoritmo empleado actualmente en el testbeam. Ganancia Canal {S’i} No hay información del tiempo ni factor de calidad de la reconstrucción
Algoritmo de Máximo Sample (MS) Extremadamente sencillo y rápido !! Ganancia Canal {S’i} No hay información del tiempo ni factor de calidad de la reconstrucción x x x Pero demasiado sensible a la variación de fase x x x x x x
Características de los datos de CIS • Amplia gama de cargas inyectadas • Disponibilidad de muestras (samples) para las dos ganancias. • Para cada carga hay un barrido de fases en pasos de (7*0.1024 ns). • Amplitud y fase pueden ser fácilmente calculados desde la NTUPLE.
Resolución de la Amplitud vs. intervalo de fase permitida Desfase máximo esperado en ATLAS ~3ns => OF~FIT!!!
Reconstrucción: Ruido (I) Reconstruction carried on with empty events Flat Filtering Optimal Filtering
Reconstrucción: Ruido (II) Reconstruction carried on with empty events
Conclusiones del estudio de algoritmos • OF y SM son muy sensibles con la fase pero pueden ser tan buenos como un ajuste dentro del intervalo adecuado de fases. • OF tiene una resolución en la reconstrucción temporal de menos de 1 ns. • OF reduce el ruido electrónico en un factor dos. Algoritmo ONLINE actual: Optimal Filtering
Sumario • Introducción al sistema de adquisión RoD del calorímetro hadrónico tilecal • Estudio de algoritmos de reconstrucción on-line • Rendimiento e implementación de algoritmos de reconstrucción en procesadores digitales de señal (DSP)
Unidad de Proceso (PU): Texas C6202 DSP • DSP: 250 MHzTMS320C6202 DSP con 256K Bytes de memoria de programa interna y 128K Bytes de memoria de datos. • Input FPGA: recibe FEB data e información de TTC. Chequea la consistencia de los datos y los direcciona a la Memoria de doble-puerto. • Dual Port Memory: Los eventos son almacenados en esta memoria (128), disponible para el DSP como memoria externa asíncrona de sólo lectura. También se usa para inicializar el programa de la memoria interna del DSP (booting) después de un reset. • Output FPGA: Depués de procesar el evento se almacena en la memoria FIFO de salida con el formato de datos adecuado. También provee de una FIFO para almacenar histogramas en tiempo real y es responsable del “booting” VME de la Input FPGA y el DSP.
Arquitectura interna del DSP • Arquitectura Harvard:Memoria de Programa y Datos accessibles simultáneamente. • FCLK = 250Mhz . Cycle time = 4ns. 2000 MIPs • Data/Program Memory: 1Mbit (128kbyte)/2Mbit (64k 32bits) • Canales DMA : 4 • EMIF & HPI: 32bits • McBSP: 3 • Timers: 2 (32 bit) • VCORE: 1.8v / VI/O: 3.3v • 8 ALUs independientes. Arquitectura Load-Store con 32 registros de propósito general de 32-Bit (dos bancos de 16). Todas las instrucciones son condicionales
Operación de la PIPELINE • Característica VLIW (Very Long Instruction Word): Código de instrucción de 256 bits (8 instrucciones de 32 bits). • La Pipeline puede atender 8 intrucciones paralelas por ciclo. Las intrucciones paralelas, avanzan simultáneamente durante la misma fase pipeline. • El código en Ensamblador debe de ser optimizado en este punto para que todas las instrucciones parezcan ser ejecutadas en 1 ciclo máquina evitando “pipeline stalls” Se contruyen Gráficos de Interdependencia Fases Pipeline: Fetch: fijo, 4 ciclos Decode: fijo, 2 ciclos Execute: variable, 1-10 ciclos
Implementación de Optimal Filtering • Calculamos Energía,t,y factor de calidad c2. • La implementación de hace considerando 7 Muestras de 10 bits y considerando el mismo set de coeficientes para todos los canales (misma tabla de constantesde calibración). • Los cálculos son realizados con operaciones sobre una ALU entera, siempre intentando sacar la máxima resolución/precisión en todas las operaciones (coeficientes en formato Q15, operaciones en 32bits, excepto multiplicación (16bits), etc...) • Código en C y en Ensamblador han sido desarrollados para comparar el rendimiento del compilador con estos dos lenguajes.
Perfilando compilación con “Code Composer v2” • Dos formas rápidas de desarrollar código: • Ensamblador • Programación en C/C++ • Opción Code Composer v2:PBC Option (Profile Based Compilation) • Nos ofrece la posibilidad de elegir entre el tamaño del código y el rendimiento para cada función de nuestra aplicación dentro de diferentes opciones de compilación. • Tamaño Programa (código máquina) aumenta => Velocidad de ejecución disminuye. • Disponibilidad de Memoria de programa vs. Velocidad de ejecución • Este programa permite compilar el código con diferentes opciones y comparar el resultado.
Gráfico de rendimiento en 'C' Flags de compilación para "Maximum Speed“: -o3 -oi0
Gráfico de rendimiento de “Ensamblador” Para compilación de ensamblador todas las configuraciones son idénticas como era de esperar (982 cycles)
C vs. Assembler • Algoritmo Energy/t/c2 para 45 canales y 7 muestras de 10bit. Comparativa de de compilaciónparala opción de “best speed performance profiling”
Conclusiones de la implementación del algotimo de Filtrado Óptimo • Podemos procesar en ensamblador un EB (32ch) y un CB(45ch) en menos de 10ms (lvl1 100kHz rate) con esta Unidad de proceso TMS320C6202@250MHz. • La unidad de proceso actual contiene 2 DSPs TMS320C6414@720MHz con lo que la capacidad de proceso se multiplica directamente por 3/DSP, a parte de una controladora de DMAs mejorada para una E/S más rápida y mejor set de instrucciones (ej: MPY2 multiplicación de 32bits). • Esto nos permite reducir el número de unidades de proceso, debido a una mejor relación de MIPs/€ o bien, probar algoritmos online con mayor carga computacional (ajustes, algoritmos adaptativos,...). • Estudio de resolución vs. Coste computacional: Usando 5 muestras en vez de 7 el alogoritmo sería 7/5 veces más rápido. Procesar ~10.000 canales online en menos de 10ms
Sumario • Introducción al sistema de adquisión RoD del calorímetro hadrónico tilecal • Estudio de algoritmos de reconstrucción on-line • Rendimiento e implementación de algoritmos de reconstrucción en procesadores digitales de señal (DSP)