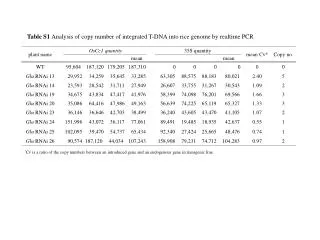
DNA Copy Number Analysis
370 likes | 736 Vues
DNA Copy Number Analysis. Qunyuan Zhang Division of Statistical Genomics Department of Genetics & Center for Genome Sciences Washington University School of Medicine 04 - 23 – 2010 GEMS Course: M 21-621 Computational Statistical Genetics. What is Copy Number ?. Gene Copy Number

DNA Copy Number Analysis
E N D
Presentation Transcript
DNA Copy Number Analysis Qunyuan Zhang Division of Statistical Genomics Department of Genetics & Center for Genome Sciences Washington University School of Medicine 04 - 23 – 2010 GEMS Course: M 21-621 Computational Statistical Genetics
What is Copy Number ? • Gene Copy Number The gene copy number (also "copy number variants" or CNVs) is the amount of copies of a particular gene in the genotype of an individual. Recent evidence shows that the gene copy number can be elevated in cancer cells. For instance, the EGFR copy number can be higher than normal in Non-small cell lung cancer. …Elevating the gene copy number of a particular gene can increase the expression of the protein that it encodes. From Wikipedia www.wikipedia.org
DNA Copy Number A Copy Number Variant (CNV) represents a copy number change involving a DNA fragment that is ~1 kilobases or larger. From Nature Reviews Genetics, Feuk et al. 2006 • DNA Copy Number≠ DNA Tandem Repeat Number (e.g. microsatellites) <10 bases • DNA Copy Number≠RNA Copy Number • RNA Copy Number = Gene Expression Level DNA transcription mRNA • Copy Numberis the amount of copies of a particular fragment of nucleic acid molecular chain. It refers to DNA Copy Number in most publications.
Why study Copy Number ? • Motive 1: Genetic Polymorphisms - restriction fragment length polymorphism (RFLP) - amplified fragment length polymorphism (AFLP) - random amplification of polymorphic DNA (RAPD) - variable number of tandem repeat (VNTR; e.g., mini- and microsatellite) - single nucleotide polymorphism (SNP) - presence/absence of transportable elements … - structural alterations (deletions, duplications, insertions, inversions … ) - DNA copy number variant (CNV) Association with phenotypes/diseases genes/genetic factors
Normal cell CN=2 Homologous repeats Segmental duplications Chromosomal rearrangements Duplicative transpositions Non-allelic recombinations …… Tumor cells deletion amplification CN=0 CN=1 CN=2 CN=3 CN=4 Motive 2: Genetic Aberrations in Tumor Cells Mutation, LOH, Copy Number Aberration (CNA)
Quantitative Polymerase Chain Reaction (Q-PCR) : DNA Amplification • (dNTPs, primers, Taq polymerase, fluorescent dye) • PCR • less CN amplification less DNA low fluorescent intensity • more CN amplification more DNA high fluorescent intensity • (one fragment each time) • Microarray : DNA Hybridization (dNTPs, primers, Taq polymerase, fluorescent dye) • PCR • less CN amplification less DNA arrayed probes low intensities • more CN amplification more DNA arrayed probes high intensities • (multiple/different fragments, mixed pool) • Hybridization How to measure/quantify Copy Number?
Array Comparative Genomic Hybridization (CGH) Tumor: red intensity Normal: green intensity more DNA copy number more DNA hybridization higher intensity Red < Green: Deletion (CN<2) Red > Green: Amplification (CN>2) Red = Green: No Alteration (CN=2)
Tumor Normal Affymetrix Mapping 250K Sty-I chip ~250K probe sets ~250K SNPs probe set (24 probes) CN=2 CN=2 CN=2 Deletion CN=1 CN=0 CN>2 Deletion Amplification more DNA copy number more DNA hybridization higher intensity SNP Array
Genotyping & Copy Number Calling CN=0 CN=1 CN=2 CN=3 CN=4 2 copy deletion, genotype (_//_) 1 copy deletion, genotype (_//B) Normal , genotype (A//B) 1 copy amplification, genotype (AA//B) 2 copy amplification, genotype (AA//BB)
BBBB AABB BB AB AA A_
Copy Number Analysis • Data Pre-processing • Individual Sample Analysis • Population Analysis
Finished chips (scanner) Raw image data [.DAT files] (experiment info [ .EXP]) (image processing software) Probe level raw intensity data [.CEL files] Background adjustment, Normalization, Summarization Summarized intensity data Raw copy number (CN) data [log ratio of tumor/normal intensities] Significance test of CN changes Estimation of CN Smoothing and boundary determination Concurrent regions among population Amplification and deletion frequencies among populations Association analysis chip description file [.CDF] Preprocessing : • An Example
Background Adjustment/Correction Reduces unevenness of a single chip Makes intensities of different positions on a chip comparable Before adjustment After adjustment Corrected Intensity (S’) = Observed Intensity (S) – Background Intensity (B) For each region i, B(i) = Mean of the lowest 2% intensities in region i AffyMetrix MAS 5.0
Background Adjustment/Correction Eliminates non-specific hybridization signal Obtains accurate intensity values for specific hybridization sense or antisense strands 25 oligonucleotide probes quartet probe set PM only, PM-MM, Ideal MM, etc.
S – Mean of S S’ = STD of S S’ ~ N(0,1 ) Base Line Array (linear); Quantile Normalization etc. Normalization Reduces technical variation between chips Makes intensities from different chips comparable Before normalization After normalization
Summarization Combines the multiple probe intensities for each probe set to produce a summarized value for subsequent analyses. Average methods: PM only or PM-MM, allele specific or non-specific Model based method : Li & Wong , 2001 Gene Expression Index
after Log transformation Log(S) before Log transformation S S : Summarized raw intensity S’ : Log transformation, S’ = log2(S) Log ratio of sample i / sample ref. CN_log2 = log2(Si/Sref) CN = 2(Si/Sref ) Raw CN Raw Copy Number Data
Individual Level Analysis • Smoothing • Significance test of amplification and deletion • Segmentation • CN estimation
… .. … … . . . . .. …… …… .. … … . . . . .. …… … .. …… … .. Window k Window N Window 10 Window 9 Window 6 Window 8 Window 4 Window 3 Window 2 Window 1 Window 7 Window 5 ……….. ……….. Each window (k) contains n consecutive SNPs (k, k+1, k+2, k+3, …, k+n-1) Sliding Window
Chrom. 7 CN Mbp Smoothing (sliding window=30 snps) Affymetrix Chrom. 7 Chrom. 7 CN CN Mbp Mbp Illumina Chrom. 7 CN Mbp
CN SD CN CN -log P -log FDR Mbp Mbp Mbp Mbp Mbp Significance Test of CN Changes
-log FDR CN Mbp Mbp Window Selection (FDR < 0.05) epidermal growth factor receptor (EGFR)
Segmentation (Break chrom. into CN-homologous pieces)BioConductor R Packages (www.bioconductor.org)DNAcopy package, circular binary segmentation (CBS) GLAD package, adaptive weights smoothing (AWS)
CBS Algorithm 1,2,3, ….,i-1, i, i+1,…,j-1,j, j+1,...n Iterate until Zc is not significant. Olshen et al. Biostatistics. 2004 Oct;5(4):557-72.
… SNP_i SNP_i+1 SNP_i+2 SNP_i+3 SNP_i+4 … CN=? CN=? CN=? CN=? CN=? log ratio log ratio log ratio log ratio log ratio CN Estimation: Hidden Markov Model (HMM)CNAT(www.affymetrix.com); dChip (www.dchip.org) ; CNAG (www.genome.umin.jp) position hidden status (unknown CN ) observed status (raw CN = log ratio of intensities) CN estimation:finding a sequence of CN values which maximizes the likelihood of observed raw CN. Algorithm: Viterbi algorithm (can be Iterative) Information/assumptions below are needed Background probabilities: Overall probabilities of possible CN values. P(CN=x); x=0,1,2,3,4,…, n (usually,n<10) Transition probabilities: Probabilities of CN values of each SNP conditional on the previous one. P(CN_i+1=xi | CN_i=xj); x=0,1,2,3,4,…, or n Emission probabilities: Probabilities of observed raw CN values of each SNP conditional on the hidden/unknown/true CN status. P(log ratio<x|CN=y)=f(x|CN=y); x=one of real numbers; y=0,1,2,3,4, …, or n
CN=4 CN=3 CN=2 CN=1 HMM Results (An Example)Black: Normal Intensities, Red: Tumor Intensities, Green: Tumor- Normal Blue: HMM estimated CNs in Tumor Tissue
References for Single Sample Analysis • Hsu et al. 2005. Denoising array-based comparative genomic hybridization data using wavelets. Biostatistics6: 211-226. • Hupe et al. Analysis of array CGH data: from signal ratio to gain and loss of DNA regions. Bioinformatics20: 3413-3422. • Jong et al. 2004. Breakpoint identification and smoothing of array comparative genomic hybridization data. Bioinformatics20: 3636-3637. • Lai et al. 2005. Comparative analysis of algorithms for identifying amplifications and deletions in array CGH data. Bioinformatics21: 3763-3770. • Lai et al. 2005. A statistical method to detect chromosomal regions with DNA copy number alterations using SNP-array-based CGH data. Comput Biol Chem29: 47-54. • Olshen et al. Circular binary segmentation for the analysis of array-based DNA copy number data. Biostatistics5: 557-572. • Picard et al. 2005. A statistical approach for array CGH data analysis. BMC Bioinformatics6: 27. • Shah et al. 2007. Modeling recurrent DNA copy number alterations in array CGH data. Bioinformatics23: i450-458. • Nilssonet al. Bioinformatics. 2009 Apr 15;25(8):1078-9. Epub 2009 Feb 19.
Population Level Analysis • Common/Reocurrent Region Identification samples Nature 2007, 450, 893-898
Genome-wide Raw Copy Number Changes(sliding window plot, averaged over ~400 pairs )
Diskin et al. 2006. STAC, Genome Res16: 1149-1158. Permutation test Frequency Test
Amplitude Test GISTIC Beroukhim et al. 2007. Proc Natl Acad Sci U S A104: 20007-20012 Weir et al. Nature 2007, 450, 893-898
Population-based One-step Analysis CMDS Method Q Zhang et al. Bioinformatics, 2009 doi:10.1093/bioinformatics/btp708
Referencesfor Multiple Sample Analysis • (GISTIC ) Beroukhim et al. 2007. Assessing the significance of chromosomal aberrations in cancer: methodology and application to glioma. Proc Natl Acad Sci U S A104: 20007-20012. • (STAC) Diskin et al. 2006. STAC: A method for testing the significance of DNA copy number aberrations across multiple array-CGH experiments. Genome Res16: 1149-1158. • (MSA) Guttman et al. 2007. Assessing the significance of conserved genomic aberrations using high resolution genomic microarrays. PLoS Genet3: e143. • (GFA) Lipson et al. 2006. Efficient calculation of interval scores for DNA copy number data analysis. J Comput Biol13: 215-228. • (MAR) Rouveirol et al. 2006. Computation of recurrent minimal genomic alterations from array-CGH data. Bioinformatics22: 849-856. • (CMDS) Zhang et al. CMDS: a population-based method for identifying recurrent DNA copy number aberrations in cancer from high-resolution data. Bioinformatics, 2009 doi:10.1093/bioinformatics/btp708
Sequencing Datacoverage/depth based analysis Nature Genetics41, 1061 - 1067 (2009)
Sequencing Datapaired-end data based analysis Science 2007:Vol. 318. pp. 420 - 426DOI: 10.1126/science.1149504
Homework Download the data file dsgweb.wustl.edu/qunyuan/data/cn_data.csv Use any published or self-developed method/software to analyze/present the data Write a report of your analysis Send to qunyuan@wustl.edu in two weeks