Q Learning In Reinforcement Learning | Q Learning Example | Machine Learning Tutorial | Simplilearn
Can we train an AI Model to find the best distance between two points without using an algorithm? The answer is yes! with Q-Learning, we can give life like qualities to our AI! In this presentation, we will teach you all there is to know about Q-Learning and more!<br><br> Introduction to Reinforcement Learning<br> What is Q-learning<br> Some important terms<br> Bellman Equation<br> Steps in Q-Learning <br><br>Post Graduate Program in AI and Machine Learning:<br>Ranked #1 AI and Machine Learning course by TechGig<br>Fast track your career with our comprehensive Post Graduate Program in AI and Machine Learning, in partnership with Purdue University and in collaboration with IBM. This AI and machine learning certification program will prepare you for one of the worldu2019s most exciting technology frontiers. This Post Graduate Program in AI and Machine Learning covers statistics, Python, machine learning, deep learning networks, NLP, and reinforcement learning. You will build and deploy deep learning models on the cloud using AWS SageMaker, work on voice assistance devices, build Alexa skills, and gain access to GPU-enabled labs.<br><br>Key Features:<br>u2705 Purdue Alumni Association Membership<br>u2705 Industry-recognized IBM certificates for IBM courses<br>u2705 Enrollment in Simplilearnu2019s JobAssist<br>u2705 25 hands-on Projects on GPU enabled Labs<br>u2705 450 hours of Applied learning<br>u2705 Capstone Project in 3 Domains<br>u2705 Purdue Post Graduate Program Certification<br>u2705 Masterclasses from Purdue<br>u2705Get noticed by the top hiring companies<br><br>ud83dudc49Learn more at: https://www.simplilearn.com/pgp-ai-machine-learning-certification-training-course<br>

Q Learning In Reinforcement Learning | Q Learning Example | Machine Learning Tutorial | Simplilearn
E N D
Presentation Transcript
What’s in it for you? • Introduction to Reinforcement Learning • What is Q-learning? • Some Important Terms • Bellman Equation • Steps in Q-learning
Introduction to Reinforcement Learning Reinforcement learning is a branch of Machine Learning that trains a model to come to an optimum solution for a problem by taking decisions by itself Solve Problems Analyse data Make decisions
Introduction to Reinforcement Learning It consists of an environment, which an agent will interact with to learn to reach a goal or perform an action Action = Fetching
Introduction to Reinforcement Learning The agent is also given a reward if the action performed by it is bringing us closer to the goal/ is leading to the goal. This is done to train the model in the right direction Reward Action = Fetching
Introduction to Reinforcement Learning Reinforcement Learning Reinforcement learning can be divided based on whether the machine uses a model to learn or learns by itself Model Free Model based Given Model Learn the Model Policy Optimization Q-Learning
What is Q-Learning? Q-Learning is a Reinforcement learning policy which will find the next best action, given a current state. It chooses this action at random and aims to maximize the reward Environment Agent Action Reward State
What is Q-Learning? : Ad suggestion Television Advertisement Consider an Ad recommendation system. Usually, when you look up a product online, you get ads which will suggest the same product over and over again
What is Q-Learning? : Ad suggestion Television Advertisement Using Q-learning, we can make an Ad recommendation system which will suggest related products to our previous purchase. The reward will be if user clicks on the suggested product
Some Important Terms States Action Rewards For every action, the agent will get a positive or negative reward The State, S, represents the current position of an agent in an environment The Action, A, is the step taken by the agent when it is in a particular state
Some Important Terms s Episodes Q-Values Temporal Difference A formula used to find the Q-Value by using the value of current state and action and previous state and action When an agent ends up in a terminating state and can’t take a new action Used to determine how good an Action, A, taken at a particular state, S, is Q(A,S)
Bellman’s Equation Learning Rate Current Q Value Reward The Bellman Equation is used to determine the value of a particular state and deduce how good it is to be in/ take that state. The optimal state will give us the highest optimal value [ R( S, A) Q( S, A) New Q( S, A) α + = + Max Q’( S’, A’) Q( S, A) ] - Discount Rate Maximum Expected Future Reward
Bellman’s Equation Learning Rate Current Q Value Reward Factors Influencing Q-values : • Current State and Action (S , A) • Previous State and Action (S’, A’) • Reward for Action, R • Maximum expected future reward [ R( S, A) Q( S, A) New Q( S, A) α + = + Max Q’( S’, A’) Q( S, A) ] - Discount Rate Maximum Expected Future Reward
Steps in Q-Learning Step 1 Create an initial Q-Table with all values initialized to 0 Fetching Running Action Sitting Start 0 0 0 Idle 0 0 0 0 Wrong Action 0 0 0 Correct Action 0 0 0 End 0 0
Steps in Q-Learning Step 2 Choose an action and perform it. Update values in the table Fetching Running Action Sitting Start 1 0 0 Idle 0 0 0 0 Wrong Action 0 0 0 Correct Action 0 0 0 End 0 0
Steps in Q-Learning Step 3 Get the value of the reward and calculate the value Q-Value using Bellman Equation Fetching Running Action Sitting Start 1 0 0 Idle 0 0 0 0 Wrong Action 0 0 34 Correct Action 0 0 0 End 0 0
Steps in Q-Learning Step 4 Continue the same until the table is filled or an episode ends Fetching Action Sitting Running Start 5 7 10 Idle 2 5 3 Wrong Action 2 6 1 Correct Action 54 34 17 End 3 1 4
Steps in Q-Learning The below table gives us an idea of how many times an action has been taken and how positively(correct action) or negatively(wrong action) it is going to affect the next state Fetching Action Sitting Running Start 5 7 10 Idle 2 5 3 Wrong Action 2 6 1 Correct Action 54 34 17 End 3 1 4
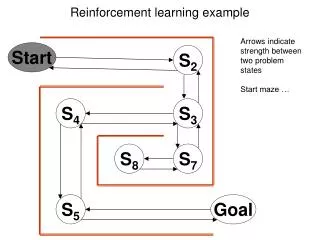
Demo In this demo, we will use Q-learning to find the shortest path between two given points