Hash Tables
Hash Tables. How well do hash tables support dynamic set operations? Implementations Direct address Hash functions Collision resolution methods Universal hash functions Detailed analysis of hashing methods. Hash Tables and Dynamic Sets. Dynamic set operations and hash tables Search(S,k)


Hash Tables
E N D
Presentation Transcript
Hash Tables • How well do hash tables support dynamic set operations? • Implementations • Direct address • Hash functions • Collision resolution methods • Universal hash functions • Detailed analysis of hashing methods
Hash Tables and Dynamic Sets • Dynamic set operations and hash tables • Search(S,k) • Insert(S,x) • Delete(S,x) • Minimum or Maximum(S) • Successor or Predecessor (S,x) • Merge(S1,S2) • When is a hash table good for dynamic sets?
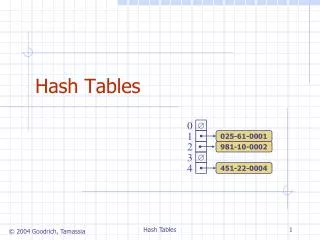
Direct-address hash table • Assumptions • Universe of keys is small (size m) • Set of keys can be mapped to {0, 1, …, m-1} • No elements have the same key • Use an array of size m • Array contents can be pointer to element • Array can directly store element
Hash Functions • Problem with direct-addressed tables • Universe of possible keys U is too large • Set of keys used K may be much smaller • Hash function • Use an array of size Q(m) • Use function h(k) = x to determine slot x • h: U {0, 1, …, m-1} • Collision • When h(k1) = h(k2)
Good Hash Functions • Each key is equally likely to hash to any of the m slots independently of where any other key has hashed to • Difficult to achieve as this requires knowledge of distribution of keys • Good characteristics • Must be able to evaluate quickly • May want keys that are “close” to map to slots that are far apart
Collision Resolution • Collisions are unavoidable even if we have a good hash function • Resolution mechanisms • Chaining • Linked list of items that share same hash value • Universal hash functions • Open addressing • Hash again (and again, and again …)
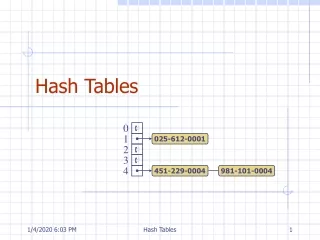
Chaining • Create a linked list to store all elements that map to same table slot • Running time • Insert(T,x): how long? what assumptions? • Search(T,k): how long? (next slide) • Delete(T,x): pointer to element x, how long, what assumptions?
Search time • Notation • n items • m slots • load factor α = n/m • Worst-case search time? • What is worst case? • Expected search time • Simple uniform hashing: each element is equally likely to hash to any of the m slots, independent of where any other element has hashed to. • Expected search time?
Universal hashing • In the worst-case, for any hash function, the keys may be exactly the worst-case for your function • Avoid this by choosing the hash function randomly independent of the keys to be hashed • Key distinction from probabilistic analysis • Universal hash function will work well with high probability on EVERY input instance but may perform poorly with low probability on EVERY input instance • Probabilistic analysis of static hash function h says h will work well on most input instances every time but may perform poorly on some input instances every time
Definition and analysis • Let H be a finite collection of hash functions that map U into {0, …, m-1} • This collection is universal if for each pair of distinct keys k and q in U, the number of hash functions h in H for which h(k) = h(q) is at most |H|/m. • If we choose our hash function randomly from H, this implies that there is at most a 1/m chance that h(k) = h(q). • This leads to the expected length of a chain being n/m • If you are looking for item with key k, what is the expected number of items that will share the same hash value h(k)? • Note we assume chaining and not open addressing in analysis
An example of universal hash functions • Choose prime p larger than all possible keys • Let Zp = {0, …, p-1} and Zp* = {1, …, p-1} • Clearly p > m. Why? • ha,b for any a in Zp* and b in Zp • ha,b(k) = ((ak+b) mod p) mod m • Hp,m = {ha,b | a in Zp* and b in Zp} • This family has a total of p(p-1) hash functions • This family of hash functions is universal
Open addressing • Store all elements in the table • Probe the hash table in event of a collision • Key idea: probe sequence is NOT the same for each element, depends on initial key • h: U x {0, 1, …, m-1} {0, 1, …, m-1} • Permutation requirement • h(k,0), h(k,1), …, h(k,m-1) is a permutation of (0, …, m-1)
Operations • Insert, search straightforward • Why can we not simply mark a slot as deleted? • If keys need to be deleted, open addressing may not be the right choice
Probing schemes • uniform hashing: each of m! permutations equally likely • not typically achieved • linear probing: h(k,i) = (h’(k) + i) mod m • Clustering effect • Only m possible probe sequences are considered • quadratic probing: h(k,i) = (h’(k)+ci+di2) mod m • constraints on c, d, m • better than linear probing as clustering effect is not as bad • Only m possible probe sequences are considered, and keys that map to same position do have identical probe sequences • double hashing: h(k,i) = (h(k) + iq(k)) mod m • q(k) must be relatively prime wrt m • m2 probe sequences considered • Much closer to uniform hashing
Search time • Preliminaries • n elements, m slots, α = n/m with n ≤ m • Assumption of uniform hashing • Expected search time on a miss • Given that h(k,i) is non-empty, what is the probability that h(k,i+1) is empty? • What is expected search time then? • Expected insertion time is essentially the same. Why? • Expected search time on a hit • If entry was ith element added, expected search time is 1/(1 – i/m) = m/(m-i) • Sum this over all m, divide by n, and you get 1/ α (Hm – Hm-n) • This can be bounded by 1/ α ln 1/(1- α)