Exploring Markov Decision Process Violations in Reinforcement Learning
Exploring Markov Decision Process Violations in Reinforcement Learning. Jordan Fryer – University of Portland Working with Peter Heeman. Outline. Background: Reinforcement Learning (RL) RL and symbolic reasoning to learn system dialogue policy Background: Markov Decision Processes (MDP)


Exploring Markov Decision Process Violations in Reinforcement Learning
E N D
Presentation Transcript
Exploring Markov Decision Process Violations in Reinforcement Learning Jordan Fryer – University of Portland Working with Peter Heeman
Outline • Background: Reinforcement Learning (RL) • RL and symbolic reasoning to learn system dialogue policy • Background: Markov Decision Processes (MDP) • The Problem • Attempting to find absolute convergence • Simplification process • Evaluation tools • Discussion
Background: Reinforcement Learning • Inputs • States • How the agent represents the environment at a certain time • Actions • How the agent interacts with the environment • Cost Function • A probabilistic mapping of a state-action pair to a value • Most of the costs may be assigned at terminal state • Simulated User • So can system can try out different dialogue behaviors • Outputs: Optimal Policy • A mapping of a state to an action • How it learns • Iteratively: evaluate current policy and explore alternatives, and then update policy
Background: Reinforcement Learning • Keep track of Q score for each state-action pair • Cost to get to the end from state following that action • For each dialogue simulation, take final cost and propagate it back over the state-action pairs in the run Q: 14 Q: 13 Q: 12 Q: 11 a1 a2 a3 a4 S1 S2 S3 S4 S5 Utt: 1 Utt: 1 Utt: 1 Utt: 1 SQ: 10 Total: 14
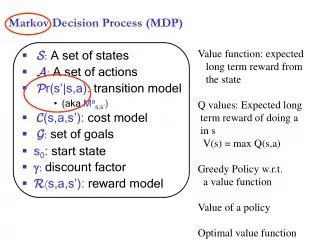
Background: Markov Decision processes • RL guaranteed to converge for Markov Decision Processes • Only use current state to decide what action to do next • System + User + Environment must satisfy: • Pr {st+1 = s’ | st,at, st-1,at-1, …, s0,a0} = Pr {st+1 = s’ | st,at} • Pr {rt+1 = r | st,at, st-1,at-1, …, s0,a0} = Pr {rt+1 = r| st,at} • How detailed should states be? • Too detailed, becomes brute force and explodes state space • Too vague, violates the MDP assumptions • RL learns solution very fast due to “merging” of states
Why RL for Dialogue? • There is a delayed cost to dialogue. • The correctness of a dialogue is not really known until the end of the dialogue and the task has been performed • Modeling after humans isn’t always correct • Many things a computer can do that a human can’t and many things a human can do that a computer can not • Hard to handcraft a policy
The Problem: Finding Absolute Convergence • RL is guaranteed to converge for MDP in the limit • How do we know if we have an MDP violation? • How long do we have to wait for convergence? • How do we measure convergence? • We will use QLearning with ε-greedy (20%)
Domain • Ran on toy Car Domain (from CS550 course) • Database of 2000 cars (differ in color, year, model …) • User has one of the 2000 cars in mind • System asks questions and reports list of cars that match the user’s car • State: • 11 Questions: Boolean (asked or not) • carBucket: Number (bucketized number of cars) • Done: Boolean (reported cars or not) • Cost Function: • 1 cost per utterance, 5 cost per extra reported car
Full Version of Problem • Every 1000 epochs (100 dialogue runs) test the current policy • Could not get it to converge
Simplified version of problem • Let’s simplify problem (common CS approach) • Removed some attributes, reduced buckets from 4 to 2, force output and exit when only one car left • Reduced number of state-action pairs • Were able to use exact user distribution for testing • Tool to examine the degree of convergence • Compare results from multiple policies (existing tool) • Keep track of the minimum testing score seen while training a policy • Calculated the percentage of test sessions that are at the minimum testing score
E # AVE MIN C % SA 19000 20 7.95082 7.95082 0.5 0.989 216 20000 20 7.95082 7.95082 0.5 0.990 216 21000 20 7.95082 7.95082 0.5 0.990 216 22000 20 7.95082 7.95082 0.5 0.990 216 23000 20 7.95082 7.95082 0.5 0.991 216 24000 20 7.95082 7.95082 0.5 0.991 216 25000 20 7.95082 7.95082 0.5 0.991 216 26000 20 7.95082 7.95082 0.5 0.991 216 27000 20 7.95082 7.95082 0.5 0.992 216 28000 20 7.95082 7.95082 0.5 0.992 216 29000 20 7.95082 7.95082 0.5 0.992 216 30000 20 7.95082 7.95082 0.5 0.992 216 31000 20 7.95082 7.95082 0.5 0.992 216 32000 20 7.95082 7.95082 0.5 0.992 216 33000 20 7.95082 7.95082 0.5 0.993 216 34000 20 7.95082 7.95082 0.5 0.993 216 35000 20 7.95082 7.95082 0.5 0.993 216 36000 20 7.95082 7.95082 0.5 0.993 216 37000 20 7.95082 7.95082 0.3 0.993 216 38000 20 7.95082 7.95082 0.1 0.994 216 39000 20 7.95082 7.95082 0.1 0.997 216 40000 20 7.95082 7.95082 0.0 0.999 216 41000 20 7.95082 7.95082 0.0 0.999 216 42000 20 7.95082 7.95082 0.0 0.999 216 43000 20 7.95082 7.95082 0.0 1.000 216 44000 20 7.95082 7.95082 0.0 1.000 216 45000 20 7.95082 7.95082 0.0 1.000 216 46000 20 7.95082 7.95082 0.0 1.000 216 47000 20 7.95082 7.95082 0.0 1.000 216 48000 20 7.95082 7.95082 0.0 1.000 216 49000 20 7.95082 7.95082 0.0 1.000 216 50000 20 7.95082 7.95082 0.0 1.000 216 E # AVE MIN C % SA 1 20 7.96066 7.95082 0.1 1.000 182 2 20 7.95738 7.95082 0.3 0.975 187 5 20 7.95656 7.95082 0.4 0.933 193 10 20 7.95328 7.95082 0.5 0.925 200 25 20 7.95082 7.95082 0.5 0.940 208 50 20 7.95082 7.95082 0.5 0.950 212 100 20 7.95164 7.95082 0.5 0.950 213 200 20 7.95082 7.95082 0.5 0.956 214 300 20 7.95082 7.95082 0.5 0.961 214 400 20 7.95082 7.95082 0.5 0.965 214 500 20 7.95082 7.95082 0.5 0.968 216 700 20 7.95082 7.95082 0.5 0.971 216 1000 20 7.95082 7.95082 0.5 0.973 216 1500 20 7.95082 7.95082 0.5 0.975 216 2000 20 7.95082 7.95082 0.5 0.977 216 2500 20 7.95082 7.95082 0.5 0.978 216 3000 20 7.95082 7.95082 0.5 0.979 216 4000 20 7.95082 7.95082 0.5 0.980 216 5000 20 7.95082 7.95082 0.5 0.981 216 6000 20 7.95082 7.95082 0.5 0.982 216 7000 20 7.95082 7.95082 0.5 0.983 216 8000 20 7.95082 7.95082 0.5 0.984 216 9000 20 7.95082 7.95082 0.5 0.985 216 10000 20 7.95082 7.95082 0.5 0.985 216 11000 20 7.95082 7.95082 0.5 0.986 216 12000 20 7.95082 7.95082 0.5 0.987 216 13000 20 7.95082 7.95082 0.5 0.987 216 14000 20 7.95082 7.95082 0.5 0.987 216 15000 20 7.95082 7.95082 0.5 0.988 216 16000 20 7.95082 7.95082 0.5 0.988 216 17000 20 7.95082 7.95082 0.5 0.989 216 18000 20 7.95082 7.95082 0.5 0.989 216
E # AVE MIN C % SA 1 20 7.96066 7.95082 0.1 1.000 182 2 20 7.95738 7.95082 0.3 0.975 187 500 20 7.95082 7.95082 0.5 0.968 216 43000 20 7.95082 7.95082 0.0 1.000 216
Simplified version of problem • Bugs found: • Would converge and then go out of convergence • Alpha rounding errors • Would find a minimum score within first 10 epochs that it could never find again • States not seen yet in training, but seen in testing, must choose same action during the test session • Got convergence • Convergence achieved when all SA pairs explored
A bit more complexity • Make domain more complex: • Added back all attributes, 2 buckets, no exit constraint • Absolute convergence before all SA pairs seen E # AVE MIN C % SA 125000 7 6.82600 6.82600 0.1 0.997 19380 126000 7 6.82600 6.82600 0.1 0.997 19390 127000 7 6.82600 6.82600 0.1 0.997 19398 128000 7 6.82600 6.82600 0.1 0.997 19401 129000 7 6.82600 6.82600 0.1 0.997 19404 130000 7 6.82600 6.82600 0.1 0.997 19415 131000 7 6.82600 6.82600 0.1 0.997 19428 132000 7 6.82600 6.82600 0.1 0.997 19434 133000 7 6.82600 6.82600 0.1 1.000 19443 134000 7 6.82600 6.82600 0.1 1.000 19450 135000 7 6.82600 6.82600 0.1 1.000 19457 136000 7 6.82600 6.82600 0.1 1.000 19463 137000 7 6.82600 6.82600 0.0 1.000 19468 138000 7 6.82600 6.82600 0.0 1.000 19475 139000 7 6.82600 6.82600 0.0 1.000 19481 140000 7 6.82600 6.82600 0.0 1.000 19492 141000 7 6.82600 6.82600 0.0 1.000 19499 E # AVE MIN C % SA … 1000000 7 6.82600 6.82600 0.0 1.000 21445 1001000 7 6.82600 6.82600 0.0 1.000 21445 1002000 7 6.82600 6.82600 0.0 1.000 21446 1003000 7 6.82600 6.82600 0.0 1.000 21448 1004000 7 6.82600 6.82600 0.0 1.000 21449 1005000 7 6.82600 6.82600 0.0 1.000 21449 1006000 7 6.82600 6.82600 0.0 1.000 21450 1007000 7 6.82600 6.82600 0.0 1.000 21450 1008000 7 6.82600 6.82600 0.0 1.000 21451 1009000 7 6.82600 6.82600 0.0 1.000 21451 1010000 7 6.82600 6.82600 0.0 1.000 21454 1011000 7 6.82600 6.82600 0.0 1.000 21455 1012000 7 6.82600 6.82600 0.0 1.000 21455 1013000 7 6.82600 6.82600 0.0 1.000 21457 1014000 7 6.82600 6.82600 0.0 1.000 21457 1015000 7 6.82600 6.82600 0.0 1.000 21459 …
Qtrain and Qtest • Qtrain: The Q values of an SA pair, used by RL in training by following the policy and exploring • Should converge to Q* (values for the optimal policy), but never know what Q* is • Our group has also been using Qtest • The Q values of an SA pair, determined through testing the optimal policy • Qtest and Qtrain should converge to Q* and so should converge to same value
Qtrain and Qtest • Helps to show absolute convergence
Now the Full Version • Moved up to 4 buckets, no absolute convergence • Noticed difference in Qtest and Qtrain • Can further analyze Qtest, • Different states “merge” • If MDP, path should not matter
Visualizing MDP Violation 2.0 CDYM1 2.0 2.0 CYM5 4.255 Action: AskDoors CDYM5 4.4425 5.0 CYM15 CDYM15 6.333 6.333
MDP Violation • Why is there an MDP violation? • CarBuckets: caused states to be treated as equal when clearly they are not. • How to remove MDP violation? • Keep a more accurate history • Not always possible: State space explodes • Just keeping track of the order in which questions are asked leads to ~40 million states • Barto & Sutton admit that most problems are not perfect MDPs but that RL can deal with it
Discussion • Does having a MDP violation hurt you? • Despite non-convergence the 4 buckets did better than the 2 buckets. • 6.8091 vs 6.8260 • RL can deal with some MDP violation • Car gas mileage analogy
Discussion • Does this mean we don’t care about MDP violation? • Rueckert (REU last year) removed an MDP violation • did not increase the state space dramatically • improved the policy learned • One should be aware of any MDP violations • Our tool can find them (or some of them) • Major MDP violations need to be fixed
Acknowledgements and Questions • Thanks to: • My fellow interns • Pat Dickerson & Kim Basney • Peter Heeman • Rebecca Lunsford • Andrew Rueckert • Ethan Selfridge • Everyone at OGI • Questions?