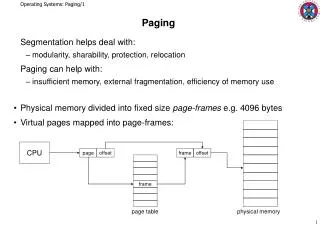
Paging
Paging. Virtual Memory. Segmentation Basic early approach Paging Modern approach Advantages Easy to allocate physical memory Easy to “page out”/swap chunks of memory Disadvantages Overhead added to each memory reference Additional memory is required to store page tables.


Paging
E N D
Presentation Transcript
Virtual Memory • Segmentation • Basic early approach • Paging • Modern approach • Advantages • Easy to allocate physical memory • Easy to “page out”/swap chunks of memory • Disadvantages • Overhead added to each memory reference • Additional memory is required to store page tables
Hardware and OS structures for paging • Hardware • Page table base register • X86: CR3 • TLB • Software • Page table • Virtual->physical or virtual->disk mapping • Page frame database • One entry for each physical page • Information about page • e.g. owning process, r/w permissions • Swap file / Section list
Page Frame Database /* Each physical page in the system has a struct page associated with * it to keep track of whatever it is we are using the page for at the * moment. Note that we have no way to track which tasks are using * a page */ struct page { unsigned long flags; // Atomic flags: locked, referenced, dirty, slab, disk atomic_t _count; // Usage count, atomic_t _mapcount; // Count of ptes mapping in this page struct { unsigned long private; // Used for managing page used in file I/O structaddress_space * mapping; // Used to define the data this page is holding }; pgoff_t index; // Our offset within mapping structlist_headlru; // Linked list node containing LRU ordering of pages void * virtual; // Kernel virtual address };
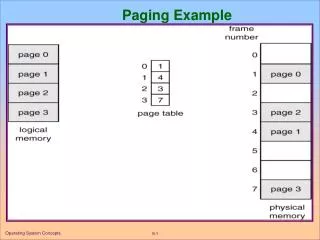
Multilevel page tables • Page of table with N levels • Virtual addresses split into N+1 parts • N indexes to different levels • 1 offset into page • Example: 32 bit paging on x86 • 4KB pages, 4 bytes/PTE • 12 bits in offset: 2^12 = 4096 • Want to fit page table entries into 1 page • 4KB / 4 bytes = 1024 PTEs per page • So level indexes = 10 bits each • 2^10 = 1024
2 level page tables Virtual Address Master Page # (10 bits) Secondary Page # (10 bits) Offset (12 bits) Physical Address Page Frame # Offset Physical Memory Secondary Page Table Page Frame 0 Page Frame 1 Page Frame 2 Page Frame 3 Page Frame Number Master Page Table Page Frame 4 Secondary Page Table
Inverted Page Table • Previous examples: “Forward Page tables” • Page table size relative to size of virtual memory • Physical memory could be much less • Lots of wasted space • Separate approach: Use a hash table • Inverted page table • Size is independent of virtual address space • Directly related to size of physical memory • Cons: • Have to manage a hash table (collisions, rebalancing, etc) Offset Virtual Page # Hash Table Phsyical Page # Offset
Addressing Page Tables • Where are page tables stored? • And in which address space? • Possibility #1: Physical memory • Easy address, no translation required • But page tables must stay resident in memory • Possibility #2: Virtual Memory (OS VA space) • Cold (unused) page table pages can be swapped out • But page table addresses must be translated through page tables • Don’t page the outer page table page (called wiring) • Question: Can the kernel be paged?
Generic PTE • PTE maps virtual page to physical page • Includes Page properties (shared with HW) • Valid? Writable? Dirty? Cacheable? • Acronyms • PTE = Page Table Entry • PDE = Page Directory Entry • VA = Virtual Address • PA = Physical Address • VPN = Virtual Page number • PPN = Physical Page number • PFN = Page Frame Number (same as PPN) Physical Page Number Property Bits Where is the virtual page number?
X86 address translation (32 bit) • Page Tables organized as a 2 level tree • Efficiently handle sparse address space • One set of page tables per process • Current page tables pointed to by CR3 • CPU “walks” page tables to find translations • Accessed and Dirty bits updated by CPU • 32 bit: 4KB or 4MB pages • 64 bit: 4 levels; 4KB or 2MB pages
X86 32 bit PDE/PTE details PWT: Write through PCD: Cache Disable P: Present R/W: Read/Write U/S: User/System AVL: Available for OS use A: Accessed D: Dirty PAT: Cache behavior definition G: Global • If page is not present (P=0), then other bits are available for OS to use. • Remember: Useful for swapping
Making it efficient • Original page table scheme doubled cost of memory accesses • 1 page table access, 1 data access • 2-level page tables triple the cost • 2 page table accesses + 1 data access • 4-level page tables quintuple the cost • 4 page table accesses + 1 data access • How to achieve efficiency • Goal: Make virtual memory accesses as fast as physical memory accesses • Solution: Use a hardware cache • Cache virtual-to-physical translations in hardware • Translation Lookaside Buffer (TLB) • X86: • TLB is managed by CPU’s MMU • 1 per CPU/core
TLBs • Translation Lookaside buffers • Translates Virtual page #s into PTEs (NOT physical addresses) • Why? • Can be done in single machine cycle • Implemented in hardware • Associative cache (many entries searched in parallel) • Cache tags are virtual page numbers • Cache values are PTEs • With PTE + offset, MMU directly calculates PA • TLBs rely on locality • Processes only use a handful of pages at a time • 16-48 entries in TLB is typical (64-192KB for 4kb pages) • Targets “hot set” or “working set” of process • TLB hit rates are critical for performance
Managing TLBs • Address translations are mostly handled by TLB • (>99%) hit rate, but there are occasional TLB misses • On miss, who places translations into TLB? • Hardware (MMU) • Knows where page tables are in memory (CR3) • OS maintains them, HW accesses them • Tables setup in HW-defined format • X86 • Software loaded TLB (OS) • TLB miss faults to OS, OS finds right PTE and loads it into TLB • Must be fast • CPU ISA has special TLB access instructions • OS uses its own page table format • SPARC and IBM Power
Managing TLBs (2) • OS must ensure TLB and page tables are consistent • If OS changes PTE, it must invalidate cached PTE in TLB • Explicit instruction to invalidate PTE • X86: invlpg • What happens on a context switch? • Each process has its own page table • Entire TLB must be invalidated (TLB flush) • X86: Certain instructions automatically flush entire TLB • Reloading CR3: asm (“mov %1, %%cr3”); • When TLB misses, a new PTE is loaded, and cached PTE is evicted • Which PTE should be evicted? • TLB Replacement Policy • Defined and implemented in hardware (usually LRU)
x86 TLB • TLB management is shared by CPU and OS • CPU: • Fills TLB on demand from page tables • OS is unaware of TLB misses • Evicts entries as needed • OS: • Ensures TLB and page tables are consistent • Flushes entire TLB when page tables are switched (e.g. context switch) • asm (“mov %0, %%cr3”:: “r”(page_table_addr)); • Modifications to a single PTE are flushed explicitly • asm (“invlpg %0;”:: “r”(virtual_addr));
Cool Paging Tricks • Exploit level of indirection between VA and PA • Shared memory • Regions of two separate processes’ address spaces map to the same physical memory • Read/write: access to shared data • Execute: shared libraries • Each process can have a separate PTE pointing to same physical memory • Different access privileges for different processes • Does the shared region need to map the same VA in each process? • Copy-On-Write (COW) • Instead of copying physical memory on fork() • Just create a new set of identical page tables with writes disabled • When a child writes to a page, OS gets page fault • OS copies physical memory page, and maps new page into child process
Saving Memory to Disk • In memory shortage: • OS writes memory contents to disk and reuses memory • Copying a whole process is called “swapping” • Copying a single page is called “paging” • Where does data go? • If it came from a file and was not modified: deleted from memory • E.g. Executable code • Unix Swap partition • A partition (file, disk segment, or entire disk) reserved as a backing store • Windows Swap file • Designated file stored in regular file system • When does data move? • Swapping: In advance of running a process • Paging: When a page of memory is accessed
Demand paging • Moving pages between memory and disk • OS uses main memory as a cache • Most of memory is used to store file data • Programs, libraries, data • File contents cached in memory • Anonymous memory • Memory not used for file data • Heap, stack, globals, … • Backed to swap file/partition • OS manages movement of pages to/from disk • Transparent to application
Why is this “demand” paging? • When a process first starts: fork()/exec() • Brand new page tables with no valid PTEs • No pages mapped to physical memory • As process executes memory is accessed • Instructions immediately fault on code and data pages • Faults stop once all necessary code/data is in memory • Only code/data that is needed • Memory that is needed changes over time • Pages shift between disk and memory
Page faults • What happens when a process references an evicted page? • When page is evicted, OS sets PTE as invalid (present = 0) • Sets rest of PTE bits to indicate location in swap file • When process accesses page, invalid PTE triggers a CPU exception (page fault) • OS invokes page fault handler • Checks PTE, and uses high 31 bits to find page in swap disk • Handler reads page from disk into available frame • Possibly has to evict another page… • Handler restarts process • What if memory is full? • Another page must be evicted (page replacement algorithm)
Evicting the best page • OS must choose victim page to be evicted • Goal: Reduce the page fault rate • The best page to evict is one that will never be accessed again • Not really possible… • Belady’s proof: Evicting the page that won’t be used for the longest period of time minimizes page fault rate
Belady’s Algorithm • Find page that won’t be used for the longest amount of time • Not possible • So why is it here? • Provably optimal solution • Comparison for other practical algorithms • Upper bound on possible performance • Lower bound? • Depends on workload… • Random replacement is generally a bad idea
FIFO • Obvious and simple • When a page is brought in, goes to tail of list • On eviction take the head of the list • Advantages • If it was brought in a while ago, then it might not be used... • Disadvantages • Or its being used by everybody (glibc) • Does not measure access behavior at all • FIFO suffers from Belady’s Anomaly • Fault rate might increase when given more physical memory • Very bad property… • Exercise: Develop a workload where this is true
Least Recently Used (LRU) • Use access behavior during selection • Idea: Use past behavior to predict future behavior • On replacement, evict page that hasn’t been used for the longest amount of time • LRU looks at the past, Belady’s looks at future • Implementation • To be perfect, every access must be detected and timestamped (way too expensive) • So it must be approximated
Approximating LRU • Many approximations, all use PTE flag • x86: Accessed bit, set by HW on every access • Each page has a counter (where?) • Periodically, scan entire list of pages • If accessed = 0, increment counter (not used) • If accessed = 1, clear counter (used) • Clear accessed flag in PTE • Counter will contain # of iterations since last reference • Page with largest counter is least recently used • Some CPUs don’t have PTE flags • Can simulate it by forcing page faults with invalid PTE
LRU Clock • Not Recently Used (NRU) or Second Chance • Replace page that is “old enough” • Arrange page in circular list (like a clock) • Clock hand (ptr value) sweeps through list • If accessed = 0, not used recently so evict it • If accessed = 1, recently used • Set accessed to 0, go to next PTE • Recommended for Project 3 • Problem: • If memory is large, “accuracy” of information degrades
N-Chance clock • Basic Clock only has two states • used or not used • Can we add more? • Answer: Embed counter into PTE • Clock hand (ptr value) sweeps through list • If accessed = 0, not used recently • if counter = 0, evict • else, decrement counter and go to next PTE • If accessed = 1, recently used • Set accessed to 0 • Increment counter • Go to next PTE