CLOUD BATCH
CLOUD BATCH. A Batch Job Queuing System on Clouds with Hadoop and Hbase Presents By Niharika Potharam. Introduction. “With CouldBATCH , a complete shift to Hadoop for managing an entire cluster to cater for hybrid computing needs becomes feasible.”


CLOUD BATCH
E N D
Presentation Transcript
CLOUD BATCH A Batch Job Queuing System on Clouds with Hadoop and Hbase Presents By NiharikaPotharam
Introduction “With CouldBATCH, a complete shift to Hadoop for managing an entire cluster to cater for hybrid computing needs becomes feasible.” • It is difficult to manage the Hadoop Clusters due to hadoop’s Lack of functionality ,user access control, accounting, finegrain performance monitoring, etc. • Hadoop is Incompatible with existing cluster batch job queuing systems and requires a dedicated cluster under its full control.
Existing Solutions • Hadoop Schedulers: FIFO Queue: But, It does not guarantee fair resource allocation. • Hadoop on Demand: Running deamons on each computer node creates an Hadoop on demand . But, Data locality of the external HDFS is not exploited.
Desired Properties for A. Job Queue Management: Cluster nodes can be assigned to queues with a minimum and maximum quantity and capacity guarantee for optimized resource utilization. Job Scheduling and Resource Utilization: Jobs with higher priority must be scheduled first and may require preemption based on priority. And reservation for pre-scheduled jobs can be supported by putting a Threshold on job submission allowance for each user. User Access Control & Accounting: Access control must be supported at least at queue level (Stateful job execution).
CloudBATCH Defintion: Uses a set of Hbase tables globally accessible, to maintain Meta-data for jobs and runs job through HadoopMapReduce.
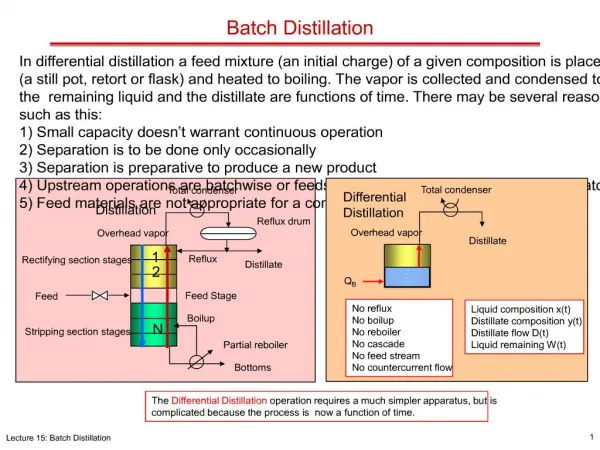
Cloud BATCH - Architecture Monitor Hbase Tables Check Status poll poll Submit Wrapper Submit Wrapper Execute Job Execute Job wrapper wrapper job X wn job Y Serial Job Client Job Table User Table Queue Table Reservation Table Reserved Job Map Reduce job Job Broker i Job Broker j
Hbase Tables Queue Table: Stores information such as type of jobs, queue capacity, queue job priority, execution time limit, queue domain, list of users or groups allowed to access the queue .
Job Table: • Contains extensive information about jobs. • Jobs are identified by unique IDs, submitted to queues and associated with the submitting users. Cloud-BATCH currently accepts 3 types of job. ->serial ->MapReduce ->Scheduled Time
Scheduled Time Table: • When Scheduled Time Table receives the information, then it sets up the status of the job in Job Table as Status:Submitted. • The value of “scheduled time” in Scheduled Tabled is used to set the “Submit Time” in the Job Table. • When a Broker sees a Scheduled job, It will not process until its “Submit Time”
Wrapper • Executes job through Hadoop Map Reduce frame work. • When a wrapper starts at some node, it grabs job information from Hbase table and stages it to local machine • Now, It performs job execution, and updates job status to “status:Running” . • After execution , sets Job status to “Status:successful” or “Status:failed”
Monitor: Detects and Handles wrapper failures • A threshold T is set , Monitor Polls the job the table for “queued” status for a time period longer than T.
Conclusion “CloudBatch” enables Hadoop to function as a traditional batch queuing system with enhanced management functionalities for cluster resource management.
Future Enhancements • Future work will be explored in the direction of further testing the system under multi-queue, multi-user situations with heavy load and refining the prototype implementation of the system for trial production deployment in solving real-world use cases. • CloudBATCH may also be exploited to make dedicated Hadoop clusters useful for the load balancing of legacy batch job submissions.
Bibilography [1] J. Dean and S. Ghemawat. Mapreduce: Simplified Data Processing on Large Clusters. Commun. ACM, 51:107–113, 2008. [2] Hadoop. http://hadoop.apache.org/. [3] HBase. http://hadoop.apache.org/hbase/. [4] T. Sandholm and K. Lai. Dynamic Proportional Share Scheduling in Hadoop. In LNCS: Proceedings of the 15th Workshop on Job Scheduling Strategies for Parallel Processing, pages 110–131, 2010. [5] M. Zaharia, D. Borthakur, J. SenSarma, K. Elmeleegy, S. Shenker, and I. Stoica. Delay Scheduling: A Simple
Technique for Achieving Locality and Fairness in Cluster Scheduling. In Proceedings of the 5th European conference on Computer systems, EuroSys ’10, pages 265–278, 2010. [6] C. Zhang and H. De Sterck. Supporting Multi-row Distributed Transactions with Global Snapshot Isolation Using Bare-bones HBase. In Proceedings of the 11th International Conference on Grid Computing (Grid), 2010. [7] C. Zhang, H. De Sterck, A. Aboulnaga, H. Djambazian, and R. Sladek. Case Study of Scientific Data Processing on a Cloud Using Hadoop. In LNCS: Proceedings of the 23rd International Symposium of High Performance Computing Systems and Applications (HPCS), pages 400–415, 2009.