
Enhancing Predictive Performance with Ensemble Methods: Trees, Bagging, and Boosting
Ensemble methods utilize multiple models to achieve superior predictive performance by combining various hypotheses into a more accurate final prediction. This approach typically involves combining weak learners, like decision trees, to create a strong learner. Although ensemble methods require more computational resources, they can significantly reduce overfitting and enhance model accuracy through intentional diversity among models. Techniques such as bagging and boosting, including Random Forests and Adaboost, demonstrate improved results by addressing model misclassifications and increasing stability.
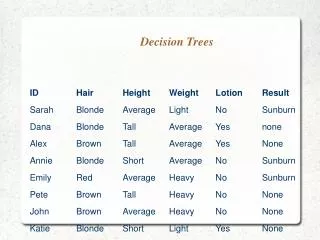

Enhancing Predictive Performance with Ensemble Methods: Trees, Bagging, and Boosting
E N D
Presentation Transcript
Ensemble methods • Use multiple models to obtain better predictive performance • Ensembles combine multiple hypotheses to form a (hopefully) better hypothesis • Combine multiple weak learners to produce a strong learner • Typically much more computation, since you are training multiple learners
Ensemble learners • Typically combine multiple fast learners (like decision trees) • Tend to overfit • Tend to get better results since there is deliberately introduced significant diversity among models • Diversity does not mean reduced performance • Note that empirical studies have shown that random forests do better than an ensemble of decision trees • Random forest is an ensemble of decisions trees that do not minimize entropy to choose tree nodes.
Bagging: Bootstrap aggregating • Each model in the ensemble votes with equal weight • Train each model with a random training set • Random forests do better than bagged entropy reducing DTs
Bootstrap estimation • Repeatedly draw n samples from D • For each set of samples, estimate a statistic • The bootstrap estimate is the mean of the individual estimates • Used to estimate a statistic (parameter) and its variance
Bagging • For i = 1 .. M • Draw n*<n samples from D with replacement • Learn classifier Ci • Final classifier is a vote of C1 .. CM • Increases classifier stability/reduces variance
Boosting • Incremental • Build new models that try to do better on previous model's mis-classifications • Can get better accuracy • Tends to overfit • Adaboost is canonical boosting algorithm
Boosting (Schapire 1989) • Randomly select n1 < nsamples from D without replacement to obtain D1 • Train weak learner C1 • Select n2 < nsamples from D with half of the samples misclassified by C1 toobtain D2 • Train weak learner C2 • Select allsamples from D that C1 and C2 disagree on • Train weak learner C3 • Final classifier is vote of weak learners
Adaboost • Learner = Hypothesis = Classifier • Weak Learner: < 50% error over any distribution • Strong Classifier: thresholded linear combination of weak learner outputs




















