Development and Validation of Predictive Classifiers using Gene Expression Profiles
Development and Validation of Predictive Classifiers using Gene Expression Profiles. Richard Simon, D.Sc. Chief, Biometric Research Branch National Cancer Institute http://brb.nci.nih.gov. BRB Website brb.nci.nih.gov. Powerpoint presentations and audio files Reprints & Technical Reports


Development and Validation of Predictive Classifiers using Gene Expression Profiles
E N D
Presentation Transcript
Development and Validation of Predictive Classifiers using Gene Expression Profiles Richard Simon, D.Sc. Chief, Biometric Research Branch National Cancer Institute http://brb.nci.nih.gov
BRB Websitebrb.nci.nih.gov • Powerpoint presentations and audio files • Reprints & Technical Reports • BRB-ArrayTools software • BRB-ArrayTools Data Archive • 100+ published cancer gene expression datasets with clinical annotations • Sample Size Planning for Clinical Trials with Predictive Biomarkers
Types of Clinical Outcome • Survival or disease-free survival • Response to therapy
90 publications identified that met criteria • Abstracted information for all 90 • Performed detailed review of statistical analysis for the 42 papers published in 2004
Major Flaws Found in 40 Studies Published in 2004 • Inadequate control of multiple comparisons in gene finding • 9/23 studies had unclear or inadequate methods to deal with false positives • 10,000 genes x .05 significance level = 500 false positives • Misleading report of prediction accuracy • 12/28 reports based on incomplete cross-validation • Misleading use of cluster analysis • 13/28 studies invalidly claimed that expression clusters based on differentially expressed genes could help distinguish clinical outcomes • 50% of studies contained one or more major flaws
Kinds of Biomarkers • Surrogate endpoint • Pre & post rx, early measure of clinical outcome • Pharmacodynamic • Pre & post rx, measures an effect of rx on disease • Prognostic • Which patients need rx • Predictive • Which patients are likely to benefit from a specific rx • Product characterization
Cardiac Arrhythmia Supression Trial • Ventricular premature beats was proposed as a surrogate for survival • Antiarrythmic drugs supressed ventricular premature beats but killed patients at approximately 2.5 times that of placebo
Prognostic Biomarkers • Most prognostic factors are not used because they are not therapeutically relevant • Most prognostic factor studies are poorly designed • They are not focused on a clear therapeutically relevant objective • They use a convenience sample of patients for whom tissue is available. Generally the patients are too heterogeneous to support therapeutically relevant conclusions • They address statistical significance rather than predictive accuracy relative to standard prognostic factors
Pusztai et al. The Oncologist 8:252-8, 2003 • 939 articles on “prognostic markers” or “prognostic factors” in breast cancer in past 20 years • ASCO guidelines only recommend routine testing for ER, PR and HER-2 in breast cancer • “With the exception of ER or progesterone receptor expression and HER-2 gene amplification, there are no clinically useful molecular predictors of response to any form of anticancer therapy.”
Prognostic and Predictive Classifiers • Most cancer treatments benefit only a minority of patients to whom they are administered • Particularly true for molecularly targeted drugs • Being able to predict which patients are likely to benefit would • save patients from unnecessary toxicity, and enhance their chance of receiving a drug that helps them • Help control medical costs • Improve the success rate of clinical drug development
Molecularly targeted drugs may benefit a relatively small population of patients with a given primary site/stage of disease • Iressa • Herceptin
Prognostic Biomarkers Can be Therapeutically Relevant • 3-5% of node negative ER+ breast cancer patients require or benefit from systemic rx other than endocrine rx • Prognostic biomarker development should focus on specific therapeutic decision context
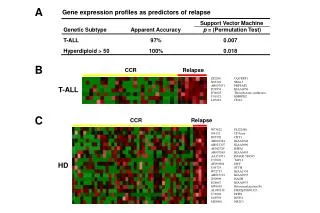
p<0.0001 338 pts 149 pts 181 pts B-14 Results—Relapse-Free Survival Paik et al, SABCS 2003
Key Features of OncotypeDx Development • Identification of important therapeutic decision context • Prognostic marker development was based on patients with node negative ER positive breast cancer receiving tamoxifen as only systemic treatment • Use of patients in NSABP clinical trials • Staged development and validation • Separation of data used for test development from data used for test validation • Development of robust assay with rigorous analytical validation • 21 gene RTPCR assay for FFPE tissue • Quality assurance by single reference laboratory operation
Predictive Biomarkers • Cancers of a primary site are often a heterogeneous grouping of diverse molecular diseases • The molecular diseases vary enormously in their responsiveness to a given treatment • It is feasible (but difficult) to develop prognostic markers that identify which patients need systemic treatment and which have tumors likely to respond to a given treatment • e.g. breast cancer and ER/PR, Her2
Mutations Copy number changes Translocations Expression profile Treatment
DNA Microarray Technology • Powerful tool for understanding mechanisms and enabling predictive medicine • Challenges ability of biomedical scientists to use effectively to produce biological knowledge or clinical utility • Challenges statisticians with new problems for which existing analysis paradigms are often inapplicable • Excessive hype and skepticism
Myth • That microarray investigations should be unstructured data-mining adventures without clear objectives
Good microarray studies have clear objectives, but not generally gene specific mechanistic hypotheses • Design and analysis methods should be tailored to study objectives
Good Microarray Studies Have Clear Objectives • Class Comparison • Find genes whose expression differs among predetermined classes • Fing genes whose expression varies over a time course in response to a defined stimulus • Class Prediction • Prediction of predetermined class (phenotype) using information from gene expression profile • Survival risk group prediction • Class Discovery • Discover clusters of specimens having similar expression profiles • Discover clusters of genes having similar expression profiles
Class Comparison and Class Prediction • Not clustering problems • Global similarity measures generally used for clustering arrays may not distinguish classes • Don’t control multiplicity or for distinguishing data used for classifier development from data used for classifier evaluation • Supervised methods • Requires multiple biological samples from each class
Levels of Replication • Technical replicates • RNA sample divided into multiple aliquots and re-arrayed • Biological replicates • Multiple subjects • Replication of the tissue culture experiment
Biological conclusions generally require independent biological replicates. The power of statistical methods for microarray data depends on the number of biological replicates. • Technical replicates are useful insurance to ensure that at least one good quality array of each specimen will be obtained.
Class Prediction • Predict which tumors will respond to a particular treatment • Predict which patients will relapse after a particular treatment
Microarray Platforms for Developing Predictive Classifiers • Single label arrays • Affymetrix GeneChips • Dual label arrays using common reference design • Dye swaps are unnecessary
Common Reference Design A1 A2 B1 B2 RED R R R R GREEN Array 1 Array 2 Array 3 Array 4 Ai = ith specimen from class A Bi = ith specimen from class B R = aliquot from reference pool
The reference generally serves to control variation in the size of corresponding spots on different arrays and variation in sample distribution over the slide. • The reference provides a relative measure of expression for a given gene in a given sample that is less variable than an absolute measure. • The reference is not the object of comparison. • The relative measure of expression will be compared among biologically independent samples from different classes.
Class Prediction • A set of genes is not a classifier • Testing whether analysis of independent data results in selection of the same set of genes is not an appropriate test of predictive accuracy of a classifier
Components of Class Prediction • Feature (gene) selection • Which genes will be included in the model • Select model type • E.g. Diagonal linear discriminant analysis, Nearest-Neighbor, … • Fitting parameters (regression coefficients) for model • Selecting value of tuning parameters • Estimating prediction accuracy
Class Prediction ≠ Class Comparison • The criteria for gene selection for class prediction and for class comparison are different • For class comparison false discovery rate is important • For class prediction, predictive accuracy is important • Demonstrating statistical significance of prognostic factors is not the same as demonstrating predictive accuracy. • Statisticians are used to inference, not prediction • Most statistical methods were not developed for p>>n prediction problems
Myth • Complex classification algorithms such as neural networks perform better than simpler methods for class prediction.
Simple Gene Selection • Select genes that are differentially expressed among the classes at a significance level (e.g. 0.01) • The level is a tuning parameter • For class comparison false discovery rate is important • For class prediction, predictive accuracy is important • For prediction it is usually more serious to exclude an informative variable than to include some noise variables
Optimal significance level cutoffs for gene selection. 50 differentially expressed genes out of 22,000 on n arrays
Complex Gene Selection • Small subset of genes which together give most accurate predictions • Genetic algorithms • Little evidence that complex feature selection is useful in microarray problems • Failure to compare to simpler methods • Improper use of cross-validation
Linear Classifiers for Two Classes • Fisher linear discriminant analysis • Diagonal linear discriminant analysis (DLDA) assumes features are uncorrelated • Compound covariate predictor (Radmacher) • Golub’s weighted voting method • Support vector machines with inner product kernel • Perceptron
The Compound Covariate Predictor (CCP) • Motivated by J. Tukey, Controlled Clinical Trials, 1993 • A compound covariate is built from the basic covariates (log-ratios) tj is the two-sample t-statistic for gene j. xijis the log-expression measure of sample i for gene j. Sum is over selected genes. • Threshold of classification: midpoint of the CCP means for the two classes.
Linear Classifiers for Two Classes • Compound covariate predictor Instead of for DLDA
Perceptrons • Perceptrons are neural networks with no hidden layer and linear transfer functions between input output • Number of input nodes equals number of genes selected • Number of output nodes equals number of classes minus 1 • Number of inputs may be major principal components of genes or major principal components of informative genes • Perceptrons are linear classifiers
Other Simple Methods • Nearest neighbor classification • Nearest k-neighbors • Nearest centroid classification • Shrunken centroid classification