Una “soluzione d’angolo”
330 likes | 559 Vues
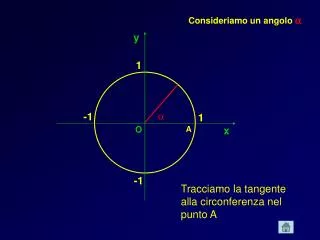
y 2. A. B. y 1. 0. Una “soluzione d’angolo”. Di solito la scelta del consumatore è identificata dal punto di tangenza tra retta del bilancio e curva di indifferenza. Ma non sempre . Nella figura, la tangenza sarebbe nel punto B,. in cui y 2 < 0 . Ma un consumo negativo

Una “soluzione d’angolo”
E N D
Presentation Transcript
y2 A B y1 0 Una “soluzione d’angolo” Di solito la scelta del consumatore è identificata dal punto di tangenza tra retta del bilancio e curva di indifferenza. Ma non sempre. Nella figura, la tangenza sarebbe nel punto B, in cui y2 < 0. Ma un consumo negativo è impossibile. Il paniere preferito sulla retta del bilancio è A, in cui y2 = 0. Una corner solution
Il modello di Regressione Ricordando che: TRONCAMENTO : E(x/x>a) = + (a) e V(x/x>a) = ²[1- (a)] CENSURA:
ATTENZIONE notazione importantissima: Finora abbiamo considerato distribuzioni con un punto di troncamento a che viene poi standardizzato sottraendo la media e dividendo per Quando consideriamo i modelli di regressione Il punto di troncamento rimane unico Lo scarto rimane unico Ma…. Il valor medio cambia, infatti sappiamo che E(yi) = xi cioè è diverso per ciascun soggetto QUINDI il punto (UNICO) di troncamento ha un valore standardizzato DIVERSO per ciascun individuo e quindi avremo:
Regressione troncata: Regressione censurata: modello modelloTobin o Tobit (censura al punto 0) Quindi OLS distorti e inconsistenti
Regressione troncata: verosimiglianza Regressione censurata: verosimiglianza
Regressione troncata: effetto marginale: Il fattore 1- (che deriva dalla varianza troncata) è compreso tra 0 e 1 quindi per ciascuna variabile l’effetto marginale è MINORE del corrispondente coefficiente, si verifica una sorta di ATTENUAZIONE dell’effetto Questo avviene nella sottopopolazione NON troncata, naturalmente a volte siamo interessati a tutta la popolazione e quindi guarderemo semplicemente al coefficiente βche rappresenta l’effetto marginale nell’intera popolazione
Un risultato utile: abbiamo visto che Questo implica che: distorsione La varianza contiene le x (incluse nei i) quindi è ETEROSCHEDASTICO
Alcunedomandefondamentali: • Qualevariabile è di interesse (cosavogliamoprevedere)? • y*? (I non censurati) Probabilmente NO – di solito non rilevante • y? (ladistribuzionelatente) Di solito SI, ilvalore per unaunitàscelta a casodallapopolazione • y | y>0? Forse. Dipendedaciòcheciinteressa • Qual’èilresiduo? • (y – previsto)? Probabilmente no, come consideriamoglizeri? • (qualcosa - x) ? Probabilmente no. x Non è la media. • Quindiqualisonoglieffettimarginali e le mediecondizionatealle x?
Regressione censurata: effetto marginale con censura a sx nel punto 0 Che può essere scomposta in due parti: Si vede così che un cambiamento nelle x ha un DOPPIO effetto: Condiziona la media della parte NON censurata Modifica la prob. di essere censurati
In altri termini l’effetto marginale non è costante, quindi la lettura dei coefficienti del modello NON è sufficiente. L’effetto sulle Y di una variazione delle X DIPENDE dal valore delle X, quindi, ad esempio, è diversa per ogni individuo (perché ha un vettore di X diverso) Se vogliamo una indicazione di sintesi rappresentiamo l’effetto delle X nel “punto medio” o per “l’individuo medio”. Cioè sostituiamo nelle formule di calcolo Se il modello ha più esplicativedue possibilità: valutazione effettuata nel punto medio per UN coefficiente, e per un valore pari a 0 per le altre variabili Valutazione nei punti medi di tutte le variabili, questo ultimo processo equivale a calcolare la media dei valori stimati individuali, modificando una sola variabile indipendente Con lo stesso principio è possibile misurare l’effetto di modificazioni delle variabili per tipologie di unità .
Lo stesso principio si utilizza per il calcolo dei valori previsti e dei residui: Il metodo di calcolo dei valori previsti e quindi dei residui Poiché il modello precede una “mistura” il metodo deve simultaneamente rendere conto della parte censurata (Ripartizione) e della parte ossservata: Naturalmente dipende dalla distribuzione ipotizzata a priori: Per residui normali è: In sostanza avremo un y=0 per coloro che date le x non superano la soglia stimata di censura
Esempio di stima: modello per le ore lavorate da un campione di donne (USA) Quester e Greene (1982) Obiettivo: verificare se le le donne il cui matrimonio sta per dissolversi, tendono a passare più o meno ore al lavoro
Esempio 2: Acquisto di carne = f(reddito) Dati artificiali, censura artificiale
Esempio 2: Sportelli bancari = f(addetti) Dati effettivi, censura artificiale
Esempio 2: Sportelli bancari = f(addetti) Zoom sulla parte troncata/censurata
Eteroschedasticità Problema, in generale risolto sostituendo nella MLE Naturalmente è necessario specificare una “forma per l’eteroschedasticità Ad esempio: Non normalità stimatore robusto: LAD (Least Absolute Deviation) estimator Molto complesso Test di chester e Irish (1987) sui residui generalizzati Stima con dati panel = problema ancora aperto Problema principale sono i processi “double hurdle” con doppia decisione Sample selection models