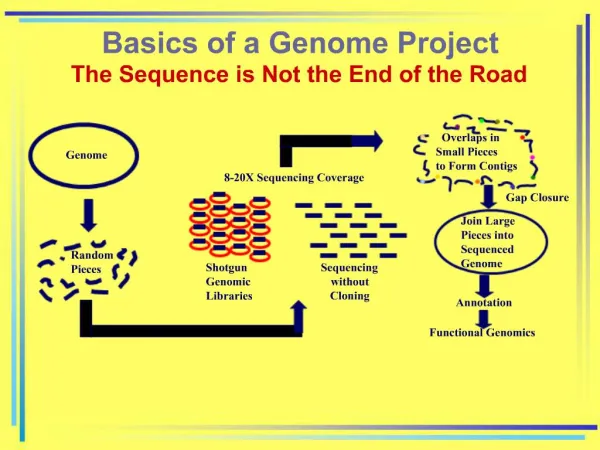
Genome properties
E N D
Presentation Transcript
Genome properties Henrik Lantz - NBIS/SciLifeLab/Uppsala University
Genome properties • Genome size • Heterozygosity levels • Repeat-content • GC-content • Secondary structure • Ploidy level
Genome size • Genome sizes range from 100 kbp to 150 Gbp • The larger the genome, the more data is needed to assemble it (>50x usually) • Compute needs grow with increased amount of data (running time and memory) • Note that larger genomes do not necessarily have to be harder to assemble, although empirically this is often the case
Heterozygosity (Slide by Torsten Seeman, Victorian Life Sciences Computation Initiative)
Highly heterozygous fungus (Zheng et al. (2013) Nature Com.)
Heterozygosity • Highly heterozygous regions tend to be assembled separately • Homologous regions existing in multiple copies in the assembly • Downstream problems in determining orthology for gene based analyses, comparative genomics etc.
Effect of heterozygosity on assembly size (Pryszcz and Gabaldon (2016) Nucl. Acids. res.)
Repeats • Identical, or near identical, regions occurring in multiple copies in a genome (Istvan et al. (2011), PLoS ONE)
Repeats • Low complexity regions Regions where some nucleotides are overrepresented, such as in homopolymers, e.g., AAAAAAAAAA, or slightly more complex, e.g., AAATAAAAAGAAAA • Tandem repeats A pattern of one or more nucleotides repeated directly adjacent to each other, e.g., AGAGAGAGAGAGAGAGAGAG 2-5 nucleotides - microsatellites (e.g., GATAGATAGATA) 10-60 nucleotides - minisatellite • Complex repeats (transposons, retroviruses, segmental duplications, rDNA, etc.)
How repeats can cause assembly errors Mathematically best result: C R B A
Repeat errors Collapsed repeats and chimeras Overlapping non-identical reads Inversions Wrong contig order
When can I expect repeats to cause a problem? • Always… • Much more common in eukaryotes, in particular plants and many animals • Several conifers have a repeat content of ~75%, mostly simple repeats -> huge genomes
How to deal with repeats • Long range information, e.g., long reads or paired reads with long insert sizes R1 R2 Short reads
How to deal with repeats • Long range information, e.g., long reads or paired reads with long insert sizes Long reads
Genome properties • GC-content • Regions of low or high GC-content have a lower coverage (Illumina, not PacBio) • Secondary structure • Regions that are tightly bound get less coverage • Ploidy level • On higher ploidy levels you potentially have more alleles present
Additional complexity • Size of organism • Hard to extract enough DNA from small organisms • Pooled individuals • Increases the variability of the DNA (more alleles) • Inhibiting compounds • Lower coverage and shorter fragments • Presence of additional genomes/contamination • Lower coverage of what you actually are interested in, potentially chimeric assemblies
Project planning Henrik Lantz - NBIS/SciLifeLab/Uppsala University
De novo genome project workflow • Plan your project! • Extract DNA (and RNA) • Choose best sequence technology for the project • Sequencing • Quality assessment and other pre-assembly investigations • Assembly • Assembly validation • Assembly comparisons • Repeat masking? • Annotation
De novo genome project workflow • Plan your project!
What do you want to achieve? Quality Fullyassembled and phasedgenome, full gene space Draft genome, split in longerrepeats, complete genes, almost full gene space Draft genome, highlyfragmented, split genes, partial gene space Effort and cost
Pilot project? • One lane of Illlumina data is cheap and can be used to investigate genome size, presence of contaminants, and more. • Long read technologies are sensitive to DNA quality issues. Trying several extractions before deciding which one to use can be a good idea. An extraction that gives good QC values (fragment sizes, absorption rates, etc.), can still fail in sequencing!
Estimate computing resources (Dominguez del Angel et al., 2018)
Estimate computing resources • What tools do you want to run? • Assembly can be memory-intense. Polishing can also require a lot of memory. A normal Rackham node might not be enough. • Do you have the necessary storage space? • Can you run your tools on several nodes over MPI?
DNA extraction Henrik Lantz - NBIS/SciLifeLab/Uppsala University
Causes of DNA degradation • Mechanical damage during tissue homogenization. • Wrong pH and ionic strength of extraction buffer. • Incomplete removal / contamination with nucleases. • Phenol: too old, or inappropriately buffered (pH 7.8 – 8.0); incomplete removal. • Wrong pH of DNA solvent (acidic water). • Recommended: 1:10 TE for short-term storage, or 1xTE for long-term storage. • Vigorous pipetting (wide-bore pipet tips). • Vortexing of DNA in high concentrations. • Too many freeze-thaw cycles (we tested 5, still Ok). • Debatable: sequence-dependent
What are the main contaminants? Polysaccharides Lypopolysaccharides Growth media residuals Chitin Protein Secondary metabolites Pigments Growth media residuals Chitin Fats Proteins Pigments Polyphenols Polysaccharides Secondary metabolites Pigments By Olga Vinnere Pettersson, Uppsala Genome Center, SciLifeLab
What do absorption ratios tell us? Pure DNA 260/280: 1.8 – 2.0 < 1.8: Too little DNA compared to other components of the solution; presence of organic contaminants: proteins and phenol; glycogen - absorb at 280 nm. > 2.0: High share of RNA. Pure DNA 260/230: 2.0 – 2.2 <2.0: Salt contamination, humic acids, peptides, aromatic compounds, polyphenols, urea, guanidine, thiocyanates (latter three are common kit components) – absorb at 230 nm. >2.2: High share of RNA, very high share of phenol, high turbidity, dirty instrument, wrong blank. Photometrically active contaminants: phenol, polyphenols, EDTA, thiocyanate, protein, RNA, nucleotides (fragments below 5 bp) By Olga Vinnere Pettersson, Uppsala Genome Center, SciLifeLab
DNA quality requirements Some DNA left in the well Sharp band of 20+kb No sign of proteins No smear of degraded DNA No sign of RNA NanoDrop: 260/280 = 1.8 – 2.0 260/230 = 2.0 – 2.2 Qubit or Picogreen: 10 kb insert libraries: 3-5 ug 20 kb insert libraries: 10-20 ug
De novo genome project workflow • Plan your project! • Extract DNA (and RNA) • Extract much more DNA than you think you need • Also remember to extract RNA for the annotation • Single individual and haploid tissue if possible • In particular for Illumina mate-pairs data and PacBio, a lot of high molecular weight DNA is critical! • Extracting DNA for de novo assembly is very different from extractions intended for PCR • Do several extractions if possible, and run them on a gel to get an idea of how fragmented the DNA is • Try to remove contaminants from the extractions
Effect of insert size on scaffold length (Treangen and Salzberg, 2013)