Download

1 / 68
680 likes | 700 Vues
Explore the use of Ensemble of Hidden Markov Models (HMMs) in solving the grand challenges of phylogenetic placement, multiple sequence alignment, metagenomic taxon identification, and gene family assignment in bioinformatics.

E N D
Using Ensembles of Hidden Markov Models for Grand Challenges in Bioinformatics Tandy Warnow Department of Computer Science The University of Illinois at Urbana-Champaign
Four Problems • Phylogenetic Placement • Multiple sequence alignment • Metagenomic taxon identification • Gene family assignment and homology detection A unifying technique is the “Ensemble of Hidden Markov Models” (introduced by Mirarab et al., 2012)
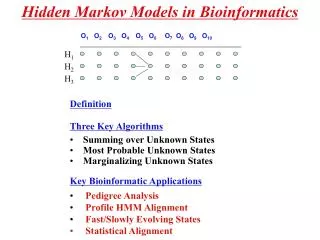
Profile HMMs • Generative model for representing a MSA • Consists of: • Set of states (Match, insertion, and deletion) • Transition probabilities • Emission probabilities
Profile Hidden Markov Models • Probabilistic model to represent a family of sequences, represented by a multiple sequence alignment • Introduced for sequence analysis in Krogh et al. 1994. Popularized in Eddy 1996 and textbook Durbin et al. 1998 • Fundamental part of HMMER and other protein databases • Used for: homology detection, protein family assignment, multiple sequence alignment, phylogenetic placement, protein structure prediction, alignment segmentation, etc.
Multiple Sequence Alignment (MSA): an important grand challenge1 S1 = AGGCTATCACCTGACCTCCA S2 = TAGCTATCACGACCGC S3 = TAGCTGACCGC … Sn = TCACGACCGACA S1 = -AGGCTATCACCTGACCTCCA S2 = TAG-CTATCAC--GACCGC-- S3 = TAG-CT-------GACCGC-- … Sn = -------TCAC--GACCGACA Novel techniques needed for scalability and accuracy NP-hard problems and large datasets Current methods do not provide good accuracy Few methods can analyze even moderately large datasets Many important applications besides phylogenetic estimation 1 Frontiers in Massive Data Analysis, National Academies Press, 2013
S1 S1 S2 S4 S4 S2 S3 S3 Simulation Studies S1 = AGGCTATCACCTGACCTCCA S2 = TAGCTATCACGACCGC S3 = TAGCTGACCGC S4 = TCACGACCGACA Unaligned Sequences S1 = -AGGCTATCACCTGACCTCCA S2 = TAG-CTATCAC--GACCGC-- S3 = TAG-CT-------GACCGC-- S4 = -------TCAC--GACCGACA S1 = -AGGCTATCACCTGACCTCCA S2 = TAG-CTATCAC--GACCGC-- S3 = TAG-C--T-----GACCGC-- S4 = T---C-A-CGACCGA----CA Compare True tree and alignment Estimated tree and alignment
1kp: Thousand Transcriptome Project N. Matasci iPlant T. Warnow, S. Mirarab, N. Nguyen UIUC UCSD UCSD J. Leebens-Mack U Georgia N. Wickett Northwestern G. Ka-Shu Wong U Alberta Plus many many other people… • Plant Tree of Life based on transcriptomes of ~1200 species • More than 13,000 gene families (most not single copy) Gene Tree Incongruence Challenge: Alignments and trees on > 100,000 sequences
PASTA: even better than SATé-2 PASTA: Mirarab, Nguyen, and Warnow, J Comp. Biol. 2015 • Simulated RNASim datasets from 10K to 200K taxa • Limited to 24 hours using 12 CPUs • Not all methods could run (missing bars could not finish)
1KP dataset: more than 100,000 p450 amino-acid sequences, many fragmentary
1KP dataset: more than 100,000 p450 amino-acid sequences, many fragmentary All standard multiple sequence alignment methods we tested performed poorly on datasets with fragments.
HMMs for MSA • Given seed alignment (e.g., in PFAM) and a collection of sequences for the protein family: • Represent seed alignment using HMM • Align each additional sequence to the HMM • Use transitivity to obtain MSA • Can we do something like this without a seed alignment?
HMMs for MSA • Given seed alignment (e.g., in PFAM) and a collection of sequences for the protein family: • Represent seed alignment using HMM • Align each additional sequence to the HMM • Use transitivity to obtain MSA • Can we do something like this without a seed alignment?
UPP UPP = “Ultra-large multiple sequence alignment using Phylogeny-aware Profiles” Nguyen, Mirarab, and Warnow. Genome Biology, 2014. Purpose: highly accurate large-scale multiple sequence alignments, even in the presence of fragmentary sequences.
UPP UPP = “Ultra-large multiple sequence alignment using Phylogeny-aware Profiles” Nguyen, Mirarab, and Warnow. Genome Biology, 2014. Purpose: highly accurate large-scale multiple sequence alignments, even in the presence of fragmentary sequences. Uses an ensemble of HMMs
Simple idea (not UPP) • Select random subset of sequences, and build “backbone alignment” • Construct a Hidden Markov Model (HMM) on the backbone alignment • Add all remaining sequences to the backbone alignment using the HMM
PASTA: even better than SATé-2 Starting tree is based on UPP(simple): one profile HMM for Backbone alignment PASTA: Mirarab, Nguyen, and Warnow, J Comp. Biol. 2015 • Simulated RNASim datasets from 10K to 200K taxa • Limited to 24 hours using 12 CPUs • Not all methods could run (missing bars could not finish)
This approach works well if the dataset is small and has low evolutionary rates, but is not very accurate otherwise. • Select random subset of sequences, and build “backbone alignment” • Construct a Hidden Markov Model (HMM) on the backbone alignment • Add all remaining sequences to the backbone alignment using the HMM
Or 2 HMMs? HMM 1 HMM 2
Or 4 HMMs? HMM 1 HMM 2 HMM 3 HMM 4
Or all 7 HMMs? HMM 1 m HMM 2 HMM 4 HMM 7 HMM 3 HMM 5 HMM 6
UPP Algorithmic Approach • Select random subset of full-length sequences, and build “backbone alignment” • Construct an “Ensemble of Hidden Markov Models” on the backbone alignment • Add all remaining sequences to the backbone alignment using the Ensemble of HMMs
Evaluation • Simulated datasets (some have fragmentary sequences): • 10K to 1,000,000 sequences in RNASim – complex RNA sequence evolution simulation • 1000-sequence nucleotide datasets from SATé papers • 5000-sequence AA datasets (from FastTree paper) • 10,000-sequence Indelible nucleotide simulation • Biological datasets: • Proteins: largest BaliBASE and HomFam • RNA: 3 CRW datasets up to 28,000 sequences
RNASim Million Sequences: tree error • Using 12 processors: • UPP(Fast,NoDecomp) took 2.2 days, • UPP(Fast) took 11.9 days, and • PASTA took 10.3 days
UPP is very robust to fragmentary sequences Under high rates of evolution, PASTA is badly impacted by fragmentary sequences (the same is true for other methods). UPP continues to have good accuracy even on datasets with many fragments under all rates of evolution. Performance on fragmentary datasets of the 1000M2 model condition
UPP Running Time Wall-clock time used (in hours) given 12 processors
Other Applications of the Ensemble of HMMs SEPP (phylogenetic placement, Mirarab, Nguyen, and Warnow PSB 2014) TIPP (metagenomic taxon identification, Nguyen, Mirarab, Liu, Pop, and Warnow, Bioinformatics 2014) HIPPI (protein classification and remote homology detection), RECOMB-CG 2016 and BMC Genomics 2016 (Nguyen, Nute, Mirarab, and Warnow)
Metagenomic taxonomic identification and phylogenetic profiling Metagenomics, Venter et al., Exploring the Sargasso Sea: Scientists Discover One Million New Genes in Ocean Microbes
1. What is this fragment? (Classify each fragment as well as possible.) 2. What is the taxonomic distribution in the dataset? (Note: helpful to use marker genes.) 3. What are the organisms in this metagenomic sample doing together? Basic Questions
SEPP and TIPP • SEPP (PSB 2012): SATé-enabled Phylogenetic Placement, and Ensembles of HMMs (eHMMs) • TIPP (Bioinformatics 2014): Applications of the eHMM technique to metagenomic abundance classification Both available at https://github.com/smirarab/sepp
Phylogenetic Placement Input: Backbone alignment and tree on full-length sequences, and a set of homologous querysequences (e.g., reads in a metagenomic sample for the same gene) Output: Placement of query sequences on backbone tree Phylogenetic placement can be used inside a pipeline, after determining the genes for each of the reads in the metagenomic sample.
Marker-based Taxon Identification Fragmentary sequences from some gene Full-length sequences for same gene, and an alignment and a tree ACCG CGAG CGG GGCT TAGA GGGGG TCGAG GGCG GGG • . • . • . ACCT AGG...GCAT TAGC...CCA TAGA...CTT AGC...ACA ACT..TAGA..A
Input S1 = -AGGCTATCACCTGACCTCCA-AA S2 = TAG-CTATCAC--GACCGC--GCA S3 = TAG-CT-------GACCGC--GCT S4 = TAC----TCAC--GACCGACAGCT Q1 = TAAAAC S1 S2 S3 S4
Align Sequence S1 = -AGGCTATCACCTGACCTCCA-AA S2 = TAG-CTATCAC--GACCGC--GCA S3 = TAG-CT-------GACCGC--GCT S4 = TAC----TCAC--GACCGACAGCT Q1 = -------T-A--AAAC-------- S1 S2 S3 S4
Place Sequence S1 = -AGGCTATCACCTGACCTCCA-AA S2 = TAG-CTATCAC--GACCGC--GCA S3 = TAG-CT-------GACCGC--GCT S4 = TAC----TCAC--GACCGACAGCT Q1 = -------T-A--AAAC-------- S1 S2 S3 S4 Q1
Phylogenetic Placement in 2011 • Align each query sequence to backbone alignment • HMMER (Finn et al., NAR 2011) • PaPaRa (Berger and Stamatakis, Bioinformatics 2011) • Place each query sequence into backbone tree • pplacer (Matsen et al., BMC Bioinformatics, 2011) • EPA (Berger and Stamatakis, Systematic Biology 2011) Note: pplacer and EPA solve same problem (maximum likelihood placement under standard sequence evolution models)
HMMER vs. PaPaRa Alignments 0.0 Increasing rate of evolution
Or 2 HMMs? HMM 1 HMM 2
Or 4 HMMs? HMM 1 HMM 2 HMM 3 HMM 4
SEPP Parameter Exploration Alignment subset size and placement subset size impact the accuracy, running time, and memory of SEPP: Small alignment subset sizes best Large placement subset size best 10% rule (both subset sizes 10% of backbone) had best overall performance
SEPP (10%-rule) on simulated data 0.0 0.0 Increasing rate of evolution
Metagenomic Taxon Identification Objective: classify short reads in a metagenomic sample
Objective: Distribution of the species (or genera, or families, etc.) within the sample. For example: The distribution of the sample at the species-level is: 50% species A 20% species B 15% species C 14% species D 1% species E Abundance Profiling
TIPP (https://github.com/smirarab/sepp) TIPP (Nguyen, Mirarb, Liu, Pop, and Warnow, Bioinformatics 2014), marker-based method that only characterizes those reads that map to the Metaphyler’s marker genes TIPP pipeline • Uses BLAST to assign reads to marker genes • Computes UPP/PASTA reference alignments • Uses reference taxonomies, refined to binary trees using reference alignment • Modifies SEPP by considering statistical uncertainty in the extended alignment and placement within the tree. • Can consider more than one extended alignment • Can consider more than optimal placement in the tree for each extended alignment • Assign taxonomic label based on MRCA of all selected placements for all selected extended alignment
TIPP (https://github.com/smirarab/sepp) TIPP (Nguyen, Mirarb, Liu, Pop, and Warnow, Bioinformatics 2014), marker-based method that only characterizes those reads that map to the Metaphyler’s marker genes TIPP pipeline • Uses BLAST to assign reads to marker genes • Computes UPP/PASTA reference alignments • Uses reference taxonomies, refined to binary trees using reference alignment • Modifies SEPP by considering statistical uncertainty in the extended alignment and placement within the tree. • Can consider more than one extended alignment • Can consider more than optimal placement in the tree for each extended alignment • Assign taxonomic label based on MRCA of all selected placements for all selected extended alignment
TIPP (https://github.com/smirarab/sepp) TIPP (Nguyen, Mirarb, Liu, Pop, and Warnow, Bioinformatics 2014), marker-based method that only characterizes those reads that map to the Metaphyler’s marker genes TIPP pipeline • Uses BLAST to assign reads to marker genes • Computes UPP/PASTA reference alignments • Uses reference taxonomies, refined to binary trees using reference alignment • Modifies SEPP by considering statistical uncertainty in the extended alignment and placement within the tree. • Can consider more than one extended alignment • Can consider more than one placement in the tree for each extended alignment • Assign taxonomic label based on MRCA of all selected placements for all selected extended alignment
TIPP (https://github.com/smirarab/sepp) TIPP (Nguyen, Mirarb, Liu, Pop, and Warnow, Bioinformatics 2014), marker-based method that only characterizes those reads that map to the Metaphyler’s marker genes TIPP pipeline • Uses BLAST to assign reads to marker genes • Computes UPP/PASTA reference alignments • Uses reference taxonomies, refined to binary trees using reference alignment • Modifies SEPP by considering statistical uncertainty in the extended alignment and placement within the tree. • Can consider more than one extended alignment • Can consider more than one placement in the tree for each extended alignment • Assign taxonomic label based on MRCA of all selected placements for all selected extended alignments