K-Means
K-Means. Michael Jones ENEE698Q Fall 2011. Overview. Introduction Problem Formulation How K-Means Works Pros and Cons of Using K-Means How to Improve K-Means K-Means on a Manifold Vector Quantization. Introduction.


K-Means
E N D
Presentation Transcript
K-Means Michael Jones ENEE698Q Fall 2011
Overview • Introduction • Problem Formulation • How K-Means Works • Pros and Cons of Using K-Means • How to Improve K-Means • K-Means on a Manifold • Vector Quantization
Introduction • K-means was first proposed by Stuart Lloyd in 1957 as a technique for pulse-code modulation. • “Least square quantization in PCM”, Bell Telephone Laboratories Paper. • Groups data into K clusters and attempts to group data points to minimize the sum of squares distance to their central mean. • Algorithm works by iterating between two stages until the data points converge.
Problem Formulation • Given a data set of {x1,…,xN} which consists of N random instances of a random D-dimensional Euclidean variable x. • Introduce a set of K prototype vectors, µk where k=1,…,K and µk corresponds to the mean of the kth cluster. • Goal is to find a grouping of data points and prototype vectors that minimizes the sum of squares distance of each data point.
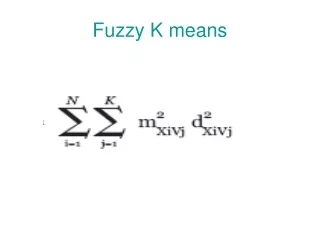
Problem Formulation (cont.) • This can be formalized by introduce a indicator variable for each data point: • rnk is {0,1}, and k=1,…,K • Our objective function becomes:
How K-Means works • Algorithm initializes the K prototype vectors to K distinct random data points. • Cycles between two stages until convergence is reached. • 1. For each data point, determine rnk where: • 2. Update µk :
How K-Means works (cont) • K-Means follows the Expectation Maximization algorithm. • Stage 1 is the E step. • Stage 2 is the M step. • If K and D are fixed, the clustering can be performed in time.
Pros and Cons of K-Means • Convergence: J may converge to a local minima and not the global minimum. May have to repeat algorithm multiple times. • Inter-Vector Relationships: Works well for Euclidian data but cannot make use of inter-vector relationships with each x. • With a large data set, the Euclidian distance calculations can be slow. • K is an input parameter. If K is inappropriately chosen it may yield poor results.
How to Improve K-Means • The E step can modified to have a general dissimilarity measure which leads to the K-medoids algorithm. • Can speed up K-means through various methods: • Pre-compute a tree where near by points are in the same sub tree. (Ramas. And Paliwal, 1990) • Use triangle inequality for computing distances. (Hodgson,1998).
Vector Quantization • Proposed by Robert M. Gray • Algorithm is nearly identical to K-Means • “Step 0. Given: A training sequence and an initial decoder. • Step 1. Encode the training sequence into a sequence of channel symbols using the given decoder minimum distortion rule. If the average distortion is small enough, quit. • Step 2. Replace the old reproduction codeword of the decoder for each channel symbol v by the centriod of all training vectors which mapped into v in Step 1. Go to Step 1.”
K-Means on a Manifold • K-Means can be performed on a manifold if one can compute the mean of the data. • Fletcher et al. introduced the notion of computing means on Riemannian manifolds. • Turagaet al. performed such an experiment applying K-Means on Riemannian manifolds. • Used iterative algorithm to find the sample Karcher mean • Used the dissimilarity measure:
Sources • Bishop C., “K-Means Clustering” in Pattern Recognition and Machine Learning, 2006, 423-430. • Fletcher, P., Lu, C., Pitzer, M., Joshi, & S., “Principal Geodesic Analysis for the Study of Nonlinear Statistics of Shape” from IEEE Transactions on Medical Imaging, VOL. 23, NO. 8, August 2004, 995-1005. • Gray, M., “Vector Quantization” in IEEE ASSP Magazine, pp. 4-29, April 1984. • Turaga, P., Veeraraghavan, A., Srivastava, A. & Chellappa, R., “Statistical Computations on Grassman and Stiefel manifolds for Image and Video-Based Recognition” in IEEE PAMI, accepted 2010.
Questions? July, 2010