Download

1 / 32
501 likes | 1.33k Vues
K-means and Fuzzy K-means. week6. K-means. Unsupervised learning algorithm C lassify a given data set through a certain number of k clusters ( k is fixed ). Description.

E N D
K-means • Unsupervised learning algorithm • Classify a given data set through a certain number of k clusters (k is fixed)
Description Given a set of observations (x1, x2, …, xn), where each observation is a d-dimensional real vector, k-means clustering aims to partition the n observations into k sets (k ≤ n): S = {S1, S2, …, Sk}, so as to minimize the within-cluster sum of squares (WCSS): where μi is the mean of points in Si.
Algorithm • Place K points into the space represented by the objects that are being clustered. These points represent initial group centroids. • Assign each object to the group that has the closest centroid. • When all objects have been assigned, recalculate the positions of the K centroids. • Repeat Steps 2 and 3 until the centroids no longer move. This produces a separation of the objects into groups from which the metric to be minimized can be calculated.
Demonstration k initial "means" (in this case k=3) are randomly generated within the data domain (shown in color). k clusters are created by associating every observation with the nearest mean. The partitions here represent the Voronoi diagram generated by the means. The centroid of each of the k clusters becomes the new mean. Steps 2 and 3 are repeated until convergence has been reached.
Interpretation In Math • Given an initial set of k means m1(1),…,mk(1), the algorithm proceeds by alternating between two steps: • Assignment step: Assign each observation to the cluster whose mean yields the least within-cluster sum of squares (WCSS). Since the sum of squares is the squared Euclidean distance, this is intuitively the "nearest" mean.(Mathematically, this means partitioning the observations according to the Voronoi diagram generated by the means). • where each xp is assigned to exactly one S(t), even if it could be is assigned to two or more of them. • Update step: Calculate the new means to be the centroids of the observations in the new clusters. • Since the arithmetic mean is a least-squares estimator, this also minimizes the within-cluster sum of squares (WCSS) objective. • The algorithm has converged when the assignments no longer change. • where each xp is assigned to exactly one S(t), even if it could be is assigned to two or more of them.
Remarks • The way to initialize the means was not specified. One popular way to start is to randomly choose k of the samples. • The results produced depend on the initial values for the means, and it frequently happens that suboptimal partitions are found. The standard solution is to try a number of different starting points. • It can happen that the set of samples closest to miis empty, so that mi cannot be updated. This is an annoyance that must be handled in an implementation, but that we shall ignore. • The results depend on the metric used to measure || x - mi||. A popular solution is to normalize each variable by its standard deviation, though this is not always desirable. • The results depend on the value of k.
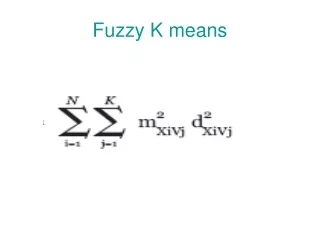
Fuzzy K-means • K-means usually generates “hard” or “crisp” clusters. • K-means only allows a data point to strictly belong to one cluster. • Fuzzy K-means is called “soft” or “fuzzy” clusters. • Fuzzy K-means allows one piece of data to belong to one or more clusters.
Algorithm Initialize U=[uij] matrix, U(0) At t-step: calculate the centers vectors C(t)=[cj] with U(t) Update U(t) , U(t+1) If || U(t+1) – U(t)||< then STOP; otherwise return to step 2.
K-means under MapReduce • Iterative MapReduceframework • The implementation accepts two input directories • Data points • The data directory contains multiple input files of SequenceFile(key, VectorWritable), • The initial clusters • The clusters directory contains one or more SequenceFiles(Text, Cluster | Canopy) containing k initial clusters or canopies. • None of the input directories are modified by the implementation, allowing experimentation with initial clustering and convergence values.
Mapper – KmeansMapper • Reads the input clusters during its setup() method, then assigns and outputs each input point to its nearest cluster as defined by the user-supplied distance measure. • Output key: Cluster Identifier. • Output value: Cluster Observation.
Data • {1.0, 1.0} C1, {1.0, 1.0} • {1.0, 3.0} C1, {1.0, 3.0} • {3.0, 1.0} C2, {3.0, 1.0} • {3.0, 3.0} C2, {3.0, 3.0} • {8.0, 8.0} C2, {8.0, 8.0} • Cluster (K=2) • C1: {1.0, 1.0} • C2: {3.0, 3.0}
Combiner – KmeansCombiner • Receives all (key : value) pairs from the mapper and produces partial sums of the input vectors for each cluster. • Output key is: Cluster Identifier. • Output value is: Cluster Observation.
Data • {1.0, 1.0} C1, {1.0, 1.0} • {1.0, 3.0} C1, {1.0, 3.0} • {3.0, 1.0} C2, {3.0, 1.0} • {3.0, 3.0} C2, {3.0, 3.0} • {8.0, 8.0} C2, {8.0, 8.0} • Cluster (K=2) • C1: {1.0, 1.0} • C2: {3.0, 3.0} C1, {{1.0, 1.0},{1.0, 3.0}} C2, {{3.0, 1.0},{3.0, 3.0}} C2, {{8.0, 8.0}}
Reducer – KmeansReducer • A single reducer receives all (key : value) pairs from all combiners and sums them to produce a new centroid for the cluster which is output. • Output key is: encoded cluster identifier. • Output value is: Cluster. • The reducer encodes un-converged clusters with a 'Cn' cluster Id and converged clusters with 'Vn' cluster Id.
Data • {1.0, 1.0} C1, {1.0, 1.0} • {1.0, 3.0} C1, {1.0, 3.0} • {3.0, 1.0} C2, {3.0, 1.0} • {3.0, 3.0} C2, {3.0, 3.0} • {8.0, 8.0} C2, {8.0, 8.0} • Cluster (K=2) • C1: {1.0, 1.0} Cn1: {1.0, 2.0} • C2: {3.0, 3.0} Cn2: {5.5, 5.0} C1, {{1.0, 1.0},{1.0, 3.0}} C2, {{3.0, 1.0},{3.0, 3.0}} C2, {{8.0, 8.0}}
Driver – KmeansDriver • Iterates over the points and clusters until • all output clusters have converged (VnclusterIds) • or a maximum number of iterations has been reached. • During iterations, a new cluster directory "clusters-N" is produced with the output clusters from the previous iteration used for input to the next. • A final optional pass over the data using the KMeansClusterMapper clusters all points to an output directory "clusteredPoints" and has no combiner or reducer steps.
Data • {1.0, 1.0} C1, {1.0, 1.0} … C1, {2.0, 2.0} • {1.0, 3.0} C1, {1.0, 3.0} … C1, {2.0, 2.0} • {3.0, 1.0} C2, {3.0, 1.0} … C1, {2.0, 2.0} • {3.0, 3.0} C2, {3.0, 3.0} … C1, {2.0, 2.0} • {8.0, 8.0} C2, {8.0, 8.0} … C2, {8.0, 8.0} • Cluster (K=2) • C1: {1.0, 1.0} … Vn1: {2.0, 2.0} • C2: {3.0, 3.0} … Vn2: {8.0, 8.0}
Using “KMeansClusterMapper” to get all clustered points • ClusteredPoints • {1.0, 1.0} 1 • {1.0, 3.0} 1 • {3.0, 1.0} 1 • {3.0, 3.0} 1 • {8.0, 8.0} 2
Choose Initial Centroids • Canopy clustering can be used to compute the initial clusters for k-Kmeans. • // run the CanopyDriver job • CanopyDriver.runJob("testdata", "output" ManhattanDistanceMeasure.class.getName(), (float) 3.1, (float) 2.1, false); • // now run the KMeansDriver job • KMeansDriver.runJob("testdata", "output/clusters-0", "output", EuclideanDistanceMeasure.class.getName(), "0.001", "10", true);
K-Means on Mahout • The k-Means clustering algorithm may be run using a command-line invocation on KMeansDriver.main or by making a Java call to KMeansDriver.runJob(). $bin/mahout kmeans\ -i <input vectors directory> \ -c <input clusters directory> \ -o <output working directory> \ -k <optional number of initial clusters to sample from input vectors> \ -dm <DistanceMeasure> \ -x <maximum number of iterations> \ -cd <optional convergence delta. Default is 0.5> \ -ow <overwrite output directory if present> -cl <run input vector clustering after computing Canopies> -xm <execution method: sequential or mapreduce>
Arguments • If the -k argument is supplied, any clusters in the -c directory will be overwritten and k random points will be sampled from the input vectors to become the initial cluster centers. 1. input: a file path string to a directory containing the input data set a SequenceFile(WritableComparable, VectorWritable). The sequence file key is not used. 2. clusters: a file path string to a directory containing the initial clusters, a SequenceFile(key, Cluster | Canopy). Both KMeans clusters and Canopy canopies may be used for the initial clusters. 3. output: a file path string to an empty directory which is used for all output from the algorithm.
4. distanceMeasure: the fully-qualified class name of an instance of DistanceMeasure which will be used for the clustering. 5. convergenceDelta: a double value used to determine if the algorithm has converged (clusters have not moved more than the value in the last iteration). 6. maxIter: the maximum number of iterations to run, independent of the convergence specified. 7. runClustering: a boolean indicating, if true, that the clustering step is to be executed after clusters have been determined. 8. runSequential: a boolean indicating, if true, that the k-means sequential implementation is to be used to process the input data.
Output • clusters-N: directories containing SequenceFiles(Text, Cluster) produced by the algorithm for each iteration. The Text key is a cluster identifier string. • clusteredPoints: (if --clustering enabled) a directory containing SequenceFile(IntWritable, WeightedVectorWritable). The IntWritable key is the clusterId. The WeightedVectorWritable value is a bean containing a double weight and a VectorWritable vector where the weight indicates the probability that the vector is a member of the cluster. For k-Means clustering, the weights are computed as 1/(1+distance) where the distance is between the cluster center and the vector using the chosen DistanceMeasure.
FuzzyKmeansDriver • This is similar to KMeansDriver. • It iterates over input points and cluster points for specified number of iterations or until it is converged. • During the ith iteration, a new cluster-i directory is created which contains the modified cluster centers obtained during FuzzyKMeans iteration. This will be feeded as input clusters in the next iteration. • Final pass: a map task is run to output "the point and the cluster membership to each cluster" pair as final output to a directory named "points”.
FuzzyKmeansMapper • Reads the input cluster during its configure() method, then computes cluster membership probability of a point to each cluster. Cluster membership is inversely proportional to the distance. Distance is computed using user supplied distance measure. • Output key is encoded Cluster Id. • Output values are Cluster Observations containing observation statistics (probability).
FuzzyKmeansCombiner • Receives all (key : value) pairs from the mapper and produces partial sums of the cluster membership probability times input vectors for each cluster. • Output key is: encoded cluster identifier. • Output values are Cluster Observations containing observation statistics.
FuzzyKmeansReducer • Multiple reducers receives certain keys and all values associated with those keys. The reducer sums the values to produce a new centroid for the cluster which is output. • Output key is: encoded cluster identifier. • Output value is: formatted cluster. The reducer encodes un-converged clusters with a 'Cn' cluster Id and converged clusters with 'Vn' clusterId.
Fuzzy Kmeans on Mahout $ bin/mahout fkmeans\ -i <input vectors directory> \ -c <input clusters directory> \ -o <output working directory> \ -dm <DistanceMeasure> \ -m <fuzziness argument >1> \ -x <maximum number of iterations> \ -k <optional number of initial clusters to sample from input vectors> \ -cd <optional convergence delta. Default is 0.5> \ -ow <overwrite output directory if present> -cl <run input vector clustering after computing Clusters> -e <emit vectors to most likely cluster during clustering> -t <threshold to use for clustering if -e is false> -xm <execution method: sequential or mapreduce>
input: a file path string to a directory containing the input data set a SequenceFile(WritableComparable, VectorWritable). The sequence file key is not used. • clustersIn: a file path string to a directory containing the initial clusters, a SequenceFile(key, SoftCluster | Cluster | Canopy). Fuzzy k-Means SoftClusters, k-Means Clusters and Canopy Canopies may be used for the initial clusters. • output: a file path string to an empty directory which is used for all output from the algorithm. • measure: the fully-qualified class name of an instance of DistanceMeasure which will be used for the clustering. • convergence: a double value used to determine if the algorithm has converged (clusters have not moved more than the value in the last iteration)
6. max-iterations: the maximum number of iterations to run, independent of the convergence specified. 7. m: the "fuzzyness" argument, a double > 1. For m equal to 2, this is equivalent to normalizing the coefficient linearly to make their sum 1. When m is close to 1, then the cluster center closest to the point is given much more weight than the others, and the algorithm is similar to k-means. 8. runClustering: a boolean indicating, if true, that the clustering step is to be executed after clusters have been determined. 9. emitMostLikely: a boolean indicating, if true, that the clustering step should only emit the most likely cluster for each clustered point. 10. threshold: a double indicating, if emitMostLikely is false, the cluster probability threshold used for emitting multiple clusters for each point. A value of 0 will emit all clusters with their associated probabilities for each vector. 11. runSequential: a boolean indicating, if true, that the algorithm is to use the sequential reference implementation running in memory.
Output • clusters-N: directories containing SequenceFiles(Text, SoftCluster) produced by the algorithm for each iteration. The Text key is a cluster identifier string. • clusteredPoints: (if runClustering enabled) a directory containing SequenceFile(IntWritable, WeightedVectorWritable). The IntWritable key is the clusterId. The WeightedVectorWritable value is a bean containing a double weight and a VectorWritable vector where the weights are computed as 1/(1+distance) where the distance is between the cluster center and the vector using the chosen DistanceMeasure.