Comprehensive Guide to Basic Learning Machines and Overfitting in MATLAB
This lab introduces essential concepts of basic learning machines, focusing on polynomial regression and ridge regression algorithms using MATLAB. Key elements include implementing ridge regression, exploring leave-one-out error (LOO), and observing effects of sample size and noise on model performance. The tutorial also delves into Support Vector Machines, discussing various loss functions and gradient descent algorithms. Additional topics like hyperparameters of model objects and practical exercises enhance understanding of the Challenge Learning Object Package (CLOP). Engage with hands-on coding examples to solidify your machine learning foundation.


Comprehensive Guide to Basic Learning Machines and Overfitting in MATLAB
E N D
Presentation Transcript
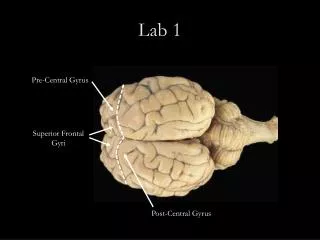
Lab 1 Getting started with Basic Learning Machines and the Overfitting Problem
Lab 1 Polynomial regression
Matlab: POLY_GUI • The code implements the ridge regression algorithm: w=argmin Si (1-yi f(xi))2 + g|| w ||2 f(x) = w1 x + w2 x2 + … + wn xn = wxT x = [x, x2, … , xn] wT = X+Y X+= XT(XXT+g)-1=(XTX+ g)-1XT X=[x(1); x(2); … x(p)] (matrix (p, n)) • The leave-one-out error (LOO) is obtained with PRESS statistic (Predicted REsidual Sums of Squares.): • LOO error = (1/p) Sk[ rk/1-(XX+)kk ]2
Matlab: POLY_GUI • At the prompt type: poly_gui; • Vary the parameters. Refrain from hitting “CV”. Explain what happens in the following situations: • Sample num. << Target degree (small noise) • Large noise, small sample num • Target degree << Model degree • Why is the LOO error sometimes larger than the training and test error? • Are there local minima in the LOO error? Is the LOO error flat near the optimum? • Propose ways of getting a better solution.
CLOP Data Objects The poly_gui emulates CLOP objects of type “data”: • X = rand(10,5) • Y = rand(10,1) • D = data(X,Y) % constructor • methods(D) • get_x(D) • get_y(D) • plot(D);
CLOP Model Objects poly_ridge is a “model” object. • P = poly_ridge; h = plot(P); • D = gene(P); plot(D, h); • [resu, P] = train(P, D); • mse(resu) • Dt = gene(P); • [tresu, P] = test(P, Dt); • mse(tresu) • plot(P, h);
Lab 1 Support Vector Machines
Support Vector Classifier x2 f(x)<0 f(x)>0 f(x) = S aiyi k(x, xi) k SV x=[x1,x2] f(x)=0 x1 Boser-Guyon-Vapnik-1992
Matlab: SVC_GUI • At the prompt type: svc_gui; • The code implements the Support Vector Machine algorithm with kernel k(s, t) = (1 + s t)q exp -g||s-t||2 • Regularization similar to ridge regression: Hinge loss: L(xi)=max(0, 1-yi f(xi))b Empirical risk: Si L(xi) w=argmin (1/C)||w||2 + Si L(xi) shrinkage
Lab 1 More loss functions…
Loss Functions L(y, f(x)) Decision boundary Margin SVC loss, b=2 max(0, (1- z))2 Adaboost loss e-z logistic loss log(1+e-z) square loss (1- z)2 SVC loss, b=1 max(0, 1-z) 0/1 loss Perceptron loss max(0, -z) z=y f(x) missclassified well classified
Exercise: Gradient Descent • Linear discriminant f(x) = Sj wj xj • Functional margin z=y f(x), y=1 • Compute z/ wj • Derive the learning rules Dwj=-h L/wj corresponding to the following loss functions: SVC loss max(0, 1-z) Adaboost loss e-z square loss (1- z)2 logistic loss log(1+e-z) Perceptron loss max(0, -z)
Exercise: Dual Algorithms • From the Dwj derive the Dw • w = Siaixi • From the Dw, derive the Dai of the dual algorithms.
Summary • Modern ML algorithms optimize a penalized risk functional:
Lab 2 Getting started with CLOP
Lab 2 CLOP tutorial
What is CLOP? • CLOP=Challenge Learning Object Package. • Based on the Spider developed at the Max Planck Institute. • Two basic abstractions: • Data object • Model object • Put the CLOP directory in your path. • At the prompt type: use_spider_clop; • If you have used before poly_gui… type clear classes
CLOP Data Objects At the Matlab prompt: • addpath(<clop_dir>); • use_spider_clop; • X=rand(10,8); • Y=[1 1 1 1 1 -1 -1 -1 -1 -1]'; • D=data(X,Y); % constructor • [p,n]=get_dim(D) • get_x(D) • get_y(D)
CLOP Model Objects D is a data object previously defined. • model = kridge; % constructor • [resu, model] = train(model, D); • resu, model.W, model.b0 • Yhat = D.X*model.W' + model.b0 • testD = data(rand(3,8), [-1 -1 1]'); • tresu = test(model, testD); • balanced_errate(tresu.X, tresu.Y)
Hyperparameters and Chains A model often has hyperparameters: • default(kridge) • hyper = {'degree=3', 'shrinkage=0.1'}; • model = kridge(hyper); • model = chain({standardize,kridge(hyper)}); • [resu, model] = train(model, D); • tresu = test(model, testD); • balanced_errate(tresu.X, tresu.Y) Models can be chained:
Hyper-parameters • Kernel methods: kridge and svc: k(x, y) = (coef0 + xy)degree exp(-gamma ||x - y||2) kij = k(xi, xj) kii kii + shrinkage • Naïve Bayes: naive: none • Neural network: neural units, shrinkage, maxiter • Random Forest: rf (windows only) mtry
Exercise • Here some the pattern recognition CLOP objects: @rf @naive @svc @neural @gentleboost @lssvm @gkridge @kridge @klogistic @logitboost • Try at the prompt example(neural) • Try other pattern recognition objects • Try different sets of hyperparameters, e.g., example(svc({'gamma=1', 'shrinkage=0.001'})) • Remember: use default(method) to get the HP.
Lab 2 Example: Digit Recognition Subset of the MNIST data of LeCun and Cortes used for the NIPS2003 challenge
data(X, Y) % Go to the Gisette directory: • cd('GISETTE') % Load “validation” data: • Xt=load('gisette_valid.data'); • Yt=load('gisette_valid.labels'); % Create a data object % and examine it: • Dt=data(Xt, Yt); • browse(Dt, 2); % Load “training” data (longer): • X=load('gisette_train.data'); • Y=load('gisette_train.labels'); • [p, n]=get_dim(Dt); • D=train(subsample(['p_max=' num2str(p)]), data(X, Y)); • clear X Y Xt Yt % Save for later use: • save('gisette', 'D', 'Dt');
model(hyperparam) % Define some hyperparameters: • hyper = {'degree=3', 'shrinkage=0.1'}; % Create a kernel ridge % regression model: • model = kridge(hyper); % Train it and test it: • [resu, Model] = train(model, D); • tresu = test(Model, Dt); % Visualize the results: • roc(tresu); • idx=find(tresu.X.*tresu.Y<0); • browse(get(D, idx), 2);
Exercise • Here are some pattern recognition CLOP objects: @rf @naive @gentleboost @svc @neural @logitboost @kridge @lssvm @klogistic • Instanciate a model with some hyperparameters (use default(method) to get the HP) • Vary the HP and the number of training examples (Hint: use get(D, 1:n) to restrict the data to n examples).
chain({model1, model2,…}) % Combine preprocessing and kernel ridge regression: • my_prepro=normalize; • model = chain({my_prepro,kridge(hyper)}); % Combine replicas of a base learner: • for k=1:10 • base_model{k}=neural; • end • model=ensemble(base_model); ensemble({model1, model2,…})
Exercise • Here are some preprocessing CLOP objects: @normalize @standardize @fourier • Chain a preprocessing and a model, e.g., • model=chain({fourier, kridge('degree=3')}); • my_classif=svc({'coef0=1', 'degree=4', 'gamma=0', 'shrinkage=0.1'}); • model=chain({normalize, my_classif}); • Train, test, visualize the results. Hint: you can browse the preprocessed data: • browse(train(standardize, D), 2);
Summary % After creating your complex model, just one command: train • model=ensemble({chain({standardize,kridge(hyper)}),chain({normalize,naive})}); • [resu, Model] = train(model, D); % After training your complex model, just one command: test • tresu = test(Model, Dt); % You can use a “cv” object to perform cross-validation: • cv_model=cv(model); • [resu, Model] = train(model, D); • roc(resu);
Lab 3 Getting started with Feature Selection
POLY_GUI again… • clear classes • poly_gui; • Check the “Multiplicative updates” (MU) box. • Play with the parameters. • Try CV • Compare with no MU
Lab 3 Exploring feature selection methods
Re-load the GISETTE data % Start CLOP: • clear classes • use_spider_clop; % Go to the Gisette directory: • cd('GISETTE') • load('gisette');
Visualization 1) Create a heatmap of the data matrix or a subset: show(D); show(get(D,1:10, 1:2:500)); 2) Look at individual patterns: browse(D); browse(D, 2); % For 2d data % Display feature positions: browse(D, 2, [212, 463, 429, 239]); 3) Make a scatter plot of a few features:scatter(D, [212, 463, 429, 239]);
Example • my_classif=svc({'coef0=1', 'degree=3', 'gamma=0', 'shrinkage=1'}); • model=chain({normalize, s2n('f_max=100'), my_classif}); • [resu, Model] = train(model, D); • tresu = test(Model, Dt); • roc(tresu); % Show the misclassified first • [s,idx]=sort(tresu.X.*tresu.Y); • browse(get(Dt, idx), 2, Model{2});
Some Filters in CLOP Univariate: • @s2n (Signal to noise ratio.) • @Ttest (T statistic; similar to s2n.) • @Pearson (Uses Matlab corrcoef. Gives the same results as Ttest, classes are balanced.) • @aucfs (ranksum test) Multivariate: • @relief (no elimination of redundancy) • @gs (Gram-Schmidt orthogonalization; complementary features)
Exercise • Change the feature selection algorithm • Visualize the features • What can you say of the various methods? • Which one gives the best results for 2, 10, 100 features? • Can you improve by changing the preprocessing? (Hint: try @pc_extract)
Lab 3 Feature significance
T-test m- m+ P(Xi|Y=1) P(Xi|Y=-1) -1 xi s- s+ • Normally distributed classes, equal variance s2 unknown; estimated from data as s2within. • Null hypothesis H0: m+ = m- • T statistic: If H0 is true, • t= (m+ - m-)/(swithin1/m++1/m-) Student(m++m--2 d.f.)
Evalution of pval and FDR • Ttest object: • computes pval analytically • FDR~pval*nsc/n • probe object: • takes any feature ranking object as an argument (e.g. s2n, relief, Ttest) • pval~nsp/np • FDR~pval*nsc/n
Analytic vs. probe 1 0.9 0.8 0.7 0.6 FDR 0.5 0.4 0.3 0.2 0.1 0 0 500 1000 1500 2000 2500 3000 3500 4000 4500 5000 rank
Example • [resu, FS] = train(Ttest, D); • [resu, PFS] = train(probe(Ttest), D); • figure('Name', 'pvalue'); • plot(get_pval(FS, 1), 'r'); • hold on; plot(get_pval(PFS, 1)); • figure('Name', 'FDR'); • plot(get_fdr(FS, 1), 'r'); • hold on; plot(get_pval(PFS, 1));
Exercise • What could explain differences between the pvalue and fdr with the analytic and probe method? • Replace Ttest with chain({rmconst('w_min=0'), Ttest}) • Recompute the pvalue and fdr curves. What do you notice? • Choose an optimum number fnum of features based on pvalue or FDR. Visualize with browse(D, 2,FS, fnum); • Create a model with fnum. Is fnum optimal? Do you get something better with CV?
Lab 3 Local feature selection
Exercise Consider the 1 nearest neighbor algorithm. We define the following score: Where s(k) (resp. d(k)) is the index of the nearest neighbor of xk belonging to the same class (resp. different class) as xk.
Exercise • Motivate the choice of such a cost function to approximate the generalization error (qualitative answer) • How would you derive an embedded method to perform feature selection for 1 nearest neighbor using this functional? • Motivate your choice (what makes your method an ‘embedded method’ and not a ‘wrapper’ method)
Relief Relief=<Dmiss/Dhit> Local_Relief= Dmiss/Dhit nearest hit Dhit Dmiss nearest miss Dhit Dmiss
Exercise • [resu, FS] = train(relief, D); • browse(D, 2,FS, 20); • [resu, LFS] = train(local_relief,D); • browse(D, 2,LFS, 20); • Propose a modification to the nearest neighbor algorithm that uses features relevant to individual patterns (like those provided by “local_relief”). • Do you anticipate such an algorithm to perform better than the non-local version using “relief”?
Epilogue Becoming a pro and playing with other datasets