Download

1 / 22
220 likes | 244 Vues
This study explores the challenges and solutions in applying multiple imputation for statistical disclosure control in business data. It discusses the benefits of using multiply imputed synthetic datasets and the challenges faced in real data applications. The study delves into missing data, skip patterns, and logical constraints, providing insights into the IAB Establishment Survey data synthesis and regression results for West and East Germany.

E N D
Disclosure Control in Business Data Experiences with Multiply Imputed Synthetic Datasets for the German IAB Establishment Survey Jörg Drechsler (Institute for Employment Research, Germany) NTTS 2009 Brussels, 20. February 2009
Overview • Background • Multiple imputation for statistical disclosure control • Challenges for real data applications • Some preliminary results • Conclusions/Future Work
SDC for Business Data • Public release of business data is often considered too risky • - Skewed distributions make identification of single units easy • - Information on businesses in the public domain • - High benefits from identifying a single unit • - High probability of inclusion for large establishments • Only coarsening and top-coding is not sufficient • Standard perturbation methods have to be applied on a high level • Release of high quality data is very difficult • Multiply imputed synthetic datasets as a possible solution
Partially synthetic datasets (Little 1993) • only potentially identifying or sensitive variables are replaced
Partially synthetic datasets (Little 1993) • only potentially identifying or sensitive variables are replaced
Partially synthetic datasets (Little 1993) • only potentially identifying or sensitive variables are replaced • advantages: - synthesis can be tailored to the records at risk • - approach is applicable to continuous and discrete variables • - modeling tries to preserve the joint distribution of the data
Challenges for real data applications • Missing data • Skip patterns • Logical constraints
Missing Data • Missing data is a common problem in surveys (More than 200 variables with missings in our survey) • Most SDL techniques can not deal with missing values • Imputation in two stages for synthetic data: • - multiply impute missing values on stage one • - generate synthetic datasets for each one stage nest on stage two • New combining rules necessary (Reiter, 2004)
Skip patterns • Joint modeling very difficult for datasets with skip patterns and different types of variables • Imputation by sequential regression (Raghunathan et al., 2001) • linear models for continuous variables • logit models for binary variables • multinomial models for categorical variables • For skip patterns: • Use logit model to decide if filtered questions are applicable • Impute values only for records with a positive outcome from the logit model
Logical constraints • All continuous variables>0 • Redraw from the model for negative units until restriction is always fulfilled • Only possible, if truncation point is at the far end of the distribution • Otherwise, refine model • Y1>Y2, e.g. total nb of employees>nb of part time employees • x=Y2/Y1 • Z=logit(x) • Use standard linear model on transformed variable • Backtransform imputed values to get final values
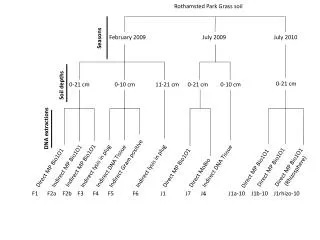
The IAB Establishment Panel • Annually conducted establishment survey • Since 1993 in Western Germany, since 1996 in Eastern Germany • Population: All establishments with at least one employee covered by social security • Source: Official Employment Statistics • Sample of more than 16.000 establishments in the last wave • Contents: employment structure, changes in employment, investment, training, remuneration, working hours, collective wage agreements, works councils
Synthesis of the IAB Establishment Panel • We only synthesize the wave 2007 • Missing values are imputed for all variables • Roughly 25 variables are synthesized • Combination of key variables and sensitive variables • Key variables: region, industry code, personnel structure,… • Sensitive variables: turnover, investments,… • For data quality evaluation, we only look at the synthesis step • Number of imputations for the synthesis: r=10
Suggested by Karr et al. (2006) Measure the overlap of CIs from the original data and CIs from the synthetic data The higher the overlap, the higher the data utility Compute the average relative CI overlap for any Confidence interval overlap CI for the synthetic data CI for the original data
Two regression results • Regressions suggested by colleagues at the IAB • First regression: • - dependent variable: part-time yes/no • - probit regression on 19 explanatory variables + industry dummies • Second regression: • - Dependent variable: expected employment trend (decrease, no change, increase) • - ordered probit on 38 variables + industry dummies • Both regressions are computed separately for West and East Germany
Regression results for West Germany • Average CI overlap: 0.89
Regression results for East Germany • Average CI overlap: 0.92
results for the second regression • Average CI overlap: 0.90 Minimum CI overlap: 0.58
Conclusions • Generating synthetic datasets is difficult and labour intensive • Synthetic datasets can handle many real data problems • Synthetic datasets seem to provide high data quality for our establishment survey • More data quality evaluations are necessary • Remaining disclosure risk needs to be quantified (Drechsler & Reiter, 2008) • Long term goal: release complete longitudinal data Future Work
Categorical Variables with a low number of observations • Standard approach: Multinomial/Dirichlet model • Covariates can only be incorporated indirectly by applying the model separately for different subgroups of the data • Provides good results for subgroups only if original dataset is large • Small datasets don’t provide enough observations to built models for different subgroups • Alternative: CART models • Suggested by Reiter (2005)
Root X1<3 L1 X2<5 L3 L2 CART Models • Flexible tool for estimating the conditional distribution of a univariate outcome given multivariate predictors • Partition the predictor space to form subsets with homogeneous outcomes • Partitions found by recursive binary splits of the predictors
CART models for synthesis • Grow a tree using the original data • Define the minimum number of records in each leaf • Prune the tree if necessary • Use partially synthesized data to locate leaf for each unit • Draw new values for each unit by using the Bayesian Bootstrap for each leaf • Difficult to define optimal tree size