Enhanced Motion Estimation via Edge Detection Using PLX Sub-Word Parallel ISA
130 likes | 244 Vues
This paper explores the acceleration of motion estimation through an innovative edge detection algorithm implemented via PLX sub-word parallel Instruction Set Architecture (ISA). We analyze various coding strategies, including block-based algorithms and object-based segmentation methods, assessing their performance at low bit rates. The edge detection techniques utilized—Sobel, Laplace, and Canny’s—enable effective image structure representation. The study highlights advantages such as efficient compression rates while addressing implementation challenges, offering insights for optimized low bit rate video coding and practical usage in image processing applications.

Enhanced Motion Estimation via Edge Detection Using PLX Sub-Word Parallel ISA
E N D
Presentation Transcript
Acceleration of motion estimation by edge detection algorithm using PLX sub-word parallel ISA Dongkeun Oh Sanghamitra Roy
Low bit rate Video coding(1) • Block based algorithms • H.263, MPEG-1,2 • Good • easy to implement, good image quality at low bit rates • Bad • Image quality degraded at very low bit rates
Low bit rate video coding (2) • Object or Segmentation based algorithm • Subdividing an image into moving objects and background • Good : Efficient compression rate • Bad : Hard to implement • Necessary condition • Accurate representation of the shape of Objects
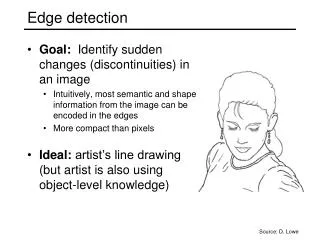
Edge detection for object recognition • Block is visually continuous and discontinuous • Lines of discontinuous interface: edge • Coded edges : structure of an image • Edge detection • Sobel • Laplace • Canny’s
Canny’s Edge detection • Stages • 1. Gaussian Smoothing • 2. First derivative for x,y of all pixels • 3. Magnitude of the gradient • 4. Non-maximal suppression • 5. Use hysteresis to mark the edge pixels • We simulate 2nd stages using PLX code
Derivative Mask Gx(z5)=(z6-z4) Gy(z5)=(z8-z2 )
Unfold C code for x-derivative calculation for(r=0; r < rows; r++) { pos = r * cols; del_x[pos] = s[pos + 1] – s[pos]; for(c = 1; c < (cols – 1); c++, pos++) { del_x[pos] = s[pos + 1] – s[pos – 1]; } del_x[pos] = s[pos] – s[pos – 1]; }
Loop unfolded C code for sub-word parallel implementation for(r=0; r < 100; r++) { pos = r * cols; del_x[pos] = s[pos + 1] – s[pos]; for(c = 1; c < 24; c++, pos+= 4) { del_x[pos] = s[pos + 1] – s[pos – 1]; del_x[pos + 1] = s[pos + 2] – s[pos]; del_x[pos + 2] = s[pos + 3] – s[pos + 1]; del_x[pos + 3] = s[pos + 4] – s[pos + 2]; } …. del_x[pos] = s[pos] – s[pos – 1]; }
PLX sub-word parallel ISA • Sub-word parallel ISA • 1, 2, 4, or 8 bytes sub-words • 32 general purpose registers • Aligned memory address • 4/8 bytes • SIMD instructions allow parallel operations with faster performance
Issues in PLX implementation • Interfacing with C code • short int = 2 bytes • use fwrite/fread to write/read binary data from C • Memory aligned load • load address: multiple of 4 bytes to avoid trap • Load from aligned address and shift/add to get required sub-words • Loops • using predicated jump instruction
Results PLX FFCF, FFB5, FFB5, 0002 C