Download

1 / 24
240 likes | 361 Vues
Preoperative Prediction of Malignancy of Ovarian Tumors Using Least Squares Support Vector Machines. C. Lu 1 , T. Van Gestel 1 , J. A. K. Suykens 1 , S. Van Huffel 1 , D. Timmerman 2 , I. Vergote 2 1 Department of Electrical Engineering, Katholieke Universiteit Leuven, Leuven, Belgium,

E N D
Preoperative Prediction of Malignancy of Ovarian Tumors Using Least Squares Support Vector Machines C. Lu1, T. Van Gestel1, J. A. K. Suykens1, S. Van Huffel1, D. Timmerman2, I. Vergote2 1Department of Electrical Engineering, Katholieke Universiteit Leuven, Leuven, Belgium, 2Department of Obstetrics and Gynecology, University Hospitals Leuven, Leuven, Belgium SISTA seminar Feb 28, 2002
Overview • Introduction • Data Exploration • LS-SVM and Bayesian evidence framework • LS-SVM classifier • Bayesian evidence framework • Input Selection • Sparse Approximation • Model Building and Model Evaluation • Conclusions SISTA seminar Feb 28, 2002
Introduction • Problem • ovarian masses: a common problem in gynecology (1/70 women). • ovarian cancer : high mortality rate • early detection of ovarian cancer is difficult • treatment and management of different types of ovarian tumors differs greatly. • develop a reliable diagnostic tool to preoperatively discriminate between benign and malignant tumors. • assist clinicians in choosing the appropriate treatment. • techniques for preoperative evaluation • Serum tumor maker: CA125 blood test • Transvaginal ultrasonography • Color Doppler imaging and blood flow indexing SISTA seminar Feb 28, 2002
Logistic Regression Artificial neural networks Support Vector Machines Bayesian Framework Bayesian blief network Least Squares SVM Hybrid Methods Introduction • Attempts to automate the diagnosis • Risk of malignancy Index (RMI) (Jacobs et al)RMI=scoremorph× scoremeno× CA125 • Methematical models SISTA seminar Feb 28, 2002
Introduction • Data • Patient data collected at Univ. Hospitals Leuven, Belgium, 1994~1999 • 425 records, 25 features. • 291 benign tumors, 134 (32%) malignant tumors SISTA seminar Feb 28, 2002
ROC curves • constructed by plotting the sensitivity versus the 1-specificity, or false positive rate, for varying probability cutoff level. • visualization of the relationship between sensitivity and specificity of a test. • Area under the ROC curves (AUC) • measures the probability of the classifier to correctly classify events and nonevents. Introduction • Development Process • Exploratory Data Analysis • Data preprocessing, • univariate analysis, • PCA, factor analysis… • Input Selection • Model training • Model evaluation • Performance measures: Receiver operating characteristic (ROC) analysis • Goal: High sensitivity for malignancy <-> low false positive rate. Providing probabilityof malignancy for individual. SISTA seminar Feb 28, 2002
Demographic, serum marker, color Doppler imaging and morphologic variables Data exploration • Univariate analysis: • preprocessing: e.g. • CA_125->log, • color_score {1,2,3,4} -> 3 design variables {0,1}.. • descriptive statistics, histograms… SISTA seminar Feb 28, 2002
Fig. Biplot of Ovarian Tumor data. • The observations are plotted as points (o - benign, x - malignant), the variables are plotted as vectors from the origin. • - visualization of the correlation between the variables • - visualization of the relations between the variables and clusters. Data exploration • Multivariate analysis: • factor analysis • biplots SISTA seminar Feb 28, 2002
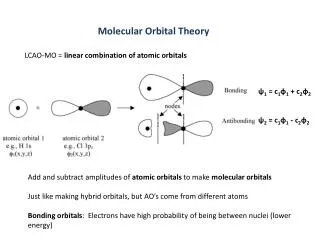
Feature space Dual space Mercer’s theorem K(x, z) = <(x) (z)> Positive definite kernel K(.,.) RBF kernel: Linear kernel: LS-SVM & Bayesian Framework • LS-SVM • Kernel based method • maps n-dimensional input vector into a higher dimensional feature space where a linear algorithm can be applied. • The learning problem: • attracting features: good generalization performance, the existing of unique solution, statistical learning theory SISTA seminar Feb 28, 2002
LS-SVM • LS-SVM classifier (Suykens & Vandewalle,1999) • Given {(xi, yi)}i=1,..,N, with input data xiRp, and the corresponding output data yi {-1, 1}. The following model is taken: where the input data x->(x) are projected to a higher dimensional feature space. One considers the following optimization problem: subject to The lagrangian is defined as where are Lagrange multipliers. SISTA seminar Feb 28, 2002
LS-SVM • LS-SVM classifier (c.t.) Taking the Kuhn-Tucker conditions for optimality, providing a set of linear equations, eliminating w and e, the solutions are obtained: withY=[y1; …; yN], 1v=[1;…;1], =[1; …, N], and ij= yiyj<(xi)(xj)> = yiyj K(xi, xj) for i, j = 1, …, N The resulting LS-SVM model for classification is • Some parameters need to be tuned: • Regularization parameter , determine the tradeoff between the minimizing training errors and minimizing the model complexity. • Kernel parameters, e.g. for an RBF kernel. Popular ways for choosing hyper parameters: cross-validation, utilize an upper bound on the generalization error. Our approach: Bayesian method. SISTA seminar Feb 28, 2002
Bayesian Evidence Framework • Bayesian Evidence Framework (MacKay 1993) • Probability theory and Occam’s razor • Bayesian probability theory provides a unifying framework for data modeling. • Occam’s razor is needed for model comparison. • Each model Hi is assumed to have: • a vector of parameters w; • a prior distribution P(w |Hi); • a set of probability distributions one for each value of w, defining the predictions P(D | w, Hi) that the model makes about the data. SISTA seminar Feb 28, 2002
Evaluating the evidence if the posterior is well approximated by a Gaussian, then evaluate most probable values for wMP, and summarize the posterior distribution by wMP, and error bars; evaluating the Hessian at wMP, The posterior can be locally approximated as Gaussian with covariance matrix A-1 evidence (2) Model comparison Assuming choosing equal priors P(Hi) to alternative models, Bayesian Evidence Framework • Probability theory and Occam’s razor (1) Model fitting Model Hi are ranked by evaluating the evidence SISTA seminar Feb 28, 2002
For classification problem with binary target yi=±1, LS-SVM cost function can also be formulized as subject to with regularization term and sum of squares error while amount of regularization determined by Bayesian Evidence Framework for LS-SVM • A Bayesian framework for LS-SVM classifiers (VanGestel and Suykens, 2001) • Starting from the feature space formulation, analytic expression are obtained in the dual space on the three levels of Bayesian inference. • Posterior class probabilities marginalizing over the model parameters. SISTA seminar Feb 28, 2002
Assume: data points are independent, target has Gaussian noise ei, the noise level is defined as 2=1/ Assume: separate Gaussian prior for w and b, w2=1/, and b (uniform distribution) The posterior probability of model parameter w and b is given by Bayesian Evidence Framework for LS-SVM • Probability interpretation of LS-SVM classifier (Level1) Applying Bayes rule, the first level of inference is obtained: wMP and bMP are obtained by solving a standard LS-SVM in dual space. SISTA seminar Feb 28, 2002
Marginalizing over w, yield a Gaussian distributed e± with mean me± and variance e±2 conditional probability where Calculated at dual space the class probability incorporate prior class probability or misclassification cost Bayesian Evidence Framework for LS-SVM • Posterior class probability for LS-SVM classifier (Level1) with In our experiments, the prior P(y=+1)=2/3, P(y=-1)=1/3 SISTA seminar Feb 28, 2002
Evidence in level 1 Assume: uniform distribution in log and log. with The eigenvalue problem The number of effective parameters A practical way to find MP, MP the is to solve first the scalar minimization problem in Bayesian Evidence Framework for LS-SVM • Inference of Hyperparameters (Level 2) Applying Bayes rule, the second level of inference is obtained: SISTA seminar Feb 28, 2002
Evidence Models are ranked by evidence Assume: uniform distribution Bayesian Evidence Framework for LS-SVM • Bayesian model comparison (Level 3) Applying Bayes rule, the third level of inference is obtained: SISTA seminar Feb 28, 2002
Bayesian Evidence Framework for LS-SVM - design • Preprocess the data • Normalize the training data into zero mean, and variance 1. • Test set follows the same normalization as training set. • Hyperparameter tuning • Select the model Hiby choosing a kernel type Kiand kernel parameter, e.g. in RBF kernels. Then the optimal regularization parameter for model Hiis estimated on the second level of inference. • The corresponding MP, MPand the number of effective parameters effcan also be estimated. Compute the model evidence P(D|Hi) at the third level of inference. • For a kernel Kiwith tuning parameters, refine the tuning parameters (e.g. ), such that a higher model evidence P(D|Hi) is obtained. SISTA seminar Feb 28, 2002
Bayesian Evidence Framework for LS-SVM - design • Input selection under the Bayesian evidence framework • Given a certain type of kernel • Performs a forward selection (greedy search). • Starting from zero variables, • the variable which gives the greatest increase in the current model evidence is chosen at each iteration step. • The selection is stopped when the adding of any remaining variable can no longer increase the model evidence. 10 variables were selected based on the training set (first treated 265 patient data), using an RBF kernel. l_ca125, pap, sol, colsc3, bilat, meno, asc, shadows, colsc4, irreg SISTA seminar Feb 28, 2002
Bayesian Evidence Framework for LS-SVM - design • Sparse approximation • Due to the choice of 2-norm in cost function, LS-SVM lost the sparseness compared with standard SVMs. • Sparseness can be imposed to LS-SVM by a pruning procedure based upon the support values i=ei. • We propose to prune the data points which have negative support values. • Intuitively, pruning of easy examples will focus the model on the harder cases which lie around the decision boundary. • Iteratively prune the data with negative i, the hyper parameters are retuned several times based on the reduced data set using the Bayesian evidence framework. • Stop when no more support values are negative. SISTA seminar Feb 28, 2002
ROC curve on training set ROC curve on test set ROC curve on test set Performance on Test set -- LSSVMrbf -- LSSVMlin -- LR -- RMI -- LSSVMrbf -- LSSVMlin -- LR -- RMI -- LSSVMrbf -- LSSVMlin -- LR -- RMI * Probability cutoff value: 0.4 and 0.3 Model Evaluation - Temporal Validation • Training set : data from the first treated 265 patients • Test set : data from the latest treated 160 patients SISTA seminar Feb 28, 2002
Averaged Performance on 30 runs of validations Expected ROC curve on validation * Probability cutoff value: 0.5 and 0.4 Model Evaluation - Randomized Cross-validation • randomly separating training set (n=265) and test set (n=160) • Stratified, #malignant : #benign ~ 2:1 for each training and test set. • Repeat 30 times SISTA seminar Feb 28, 2002
Conclusions • Summary • Data exploratory analysis helps to analyze the data set. • Under the Bayesian evidence framework, choosing of the model regularization and kernel parameters for LS-SVM classifier can be done in a unified way, without the need of selecting additional validation set. • A forward input selection procedure which tries to maximize the model evidence has been proved to be able to identify the subset of important variables for model building. • A sparse approximation can further improve the generalization performance of the LS-SVM classifiers. • LS-SVMs have the potential to give reliable preoperative prediction of malignancy of ovarian tumors. • Future work • A larger scale validation is still needed. • Hybrid methodology, e.g. combine the Bayesian network with the learning of LS-SVM, might be more promising SISTA seminar Feb 28, 2002










![C[ i ][j]=A[ i ][1]+B[1][j]](https://cdn2.slideserve.com/3988576/slide1-dt.jpg)